Download

1 / 28
280 likes | 837 Views
Neural Network - Perceptron. 숭실대 전기공학과 C ontrol I nformation P rocess L ab 김경진. Variant of Network. Variety of Neural Network Feedforward Network – Perceptron Recurrent Network - Hopfield Network 입력과 출력을 동일하게 하는 Network Optimization Problem 에 이용

E N D
Neural Network - Perceptron 숭실대 전기공학과 Control Information Process Lab 김경진
Variant of Network • Variety of Neural Network • Feedforward Network – Perceptron • Recurrent Network - Hopfield Network • 입력과 출력을 동일하게 하는 Network • Optimization Problem에 이용 • Competitive Network - Hamming Network • Feedforward + Recurrent Network • 입력에 대하여 Hamming distance를 최소화 하는 Network • Target 불필요함 • Recurrent Layer • Layer with Feedback • 초기조건 필요
HopfieldNetwork – Example W = [w11 w12 w13 w21 w22 w23 w31 w32 w33] b = [b1 b2 b3]T P1 = [-1 1 -1]T(banana) P2 = [-1 -1 1]T(pineapple) T1 = [-1 1 -1]T, T2 = [-1 -1 1]T
HammingNetwork – Example W1 = [P1T P2T]T, b = [R R]T, (R= 입력의 개수) W2 = [1 -ε;- ε 1], 0< ε<1/s-1 (s = Recurrent Layer의 Neuron 개수)
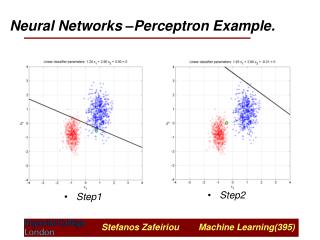
Single Neuron Perceptron - definition The Perceptron is a binary classifier. SingleNeuron Perceptron
Perceptron - Algorithm • Learning Rule – Perceptron • e = t – o (t = target, o = output, e = error) • W = W + eX = W + (t – o)X • b = b + e = b + (t – o) • 초기값에따라 Weight, Bias 값이달라짐.
Single Neuron Perceptron – example1(AND) • Simulation Result1 • Initial Weight : [0 0] • Initial Bias : 0 • Iteration Number : 3 • Weight : [2 2] • Bias = -2 • Simulation Result2 • Initial Weight : [-1.5 -1.5] • Initial Bias : -10 • Iteration Number : 4 • Weight : [4.5 4.5] • Bias = -4 X = [1 1 -1 -1 1 -1 1 -1] O = [1 -1 -1 -1]
ADALINE Network – Algorithm • ADAptiveLInearNEuron • Perceptron과의 차이 • Transfer Function : Hard Limit vs Linear • Algorithm(Least Mean Square) • W(k+1) = W(k) + 2αe(k)pT(k) • b(k+1) = b(k) + 2αe(k)
ADALINE Network – example1(AND) • X = [1 1 -1 -1 • 1 -1 1 -1] • O = [1 -1 -1 -1] • Simulation Result1 • Initial Weight : [0 0] • Initial Bias : 0 • α : 0.5 • Iteration Number : 2 • Weight : [0.5 0.5] • Bias = -0.5 • Simulation Result2 • Initial Weight : [-1.5 -1.5] • Initial Bias : -10 • α : 0.5 • Iteration Number : 2 • Weight : [0.5 0.5] • Bias = -0.5
ADALINE Network – example1(AND) • Simulation Result4 • Initial Weight : [0 0] • Initial Bias : 0 • α : 0.1 • Iteration Number : 162 • Weight : [0.5 0.5] • Bias = -0.5 • Simulation Result3 • Initial Weight : [0 0] • Initial Bias : 0 • α : 1.2 • Weight : [-5.2 -5.2]*e153 • Bias = 5.2e153 • Simulation 시 주의사항 • 적정한 α값 찾기 • α가 크면 발산 • α가 작으면 반복 횟수 증가 • error가 더 이상 줄어들지 않으면 멈추기 • ADALINE은 선형시스템
ADALINE Network – example2(XOR) • Linearly Separable • 직선으로구분 가능한 것 • AND Problem • NotLinearly Separable • 직선으로구분 불가능 한 것 • XOR Problem • ADALINE Network로는 분류 불가능 • 해결 방법1 - Multi Neuron 사용 • 해결방법2 - Multi Layer 사용
ADALINE Network – example2(XOR) • 한계점 - ① 차원 늘리기 ② 선형적 분류 • ∴ 해결방법2. Multi Layer Perceptron사용 • 해결방법1. MultiNeuron 사용 • Target의 차원을 늘린다. • Ex) 1, 0 -> [0;0], [0;1], [1;0], [1;1] • Simulation 결과 • Initial Weight : [1 2;-1 -5] • Initial Bias : [3;-2], α : 0.5 • Iteration Number : 2 • W = [0 0;0 0], b = [0;0]
Multi-Layer Perceptron - Characteristic • MLP의 장단점 • NotLinear Separable 문제 해결, 함수 근사화 • 복잡한 구조 및 알고리즘, 국소적 최소값 수렴
Multi-Layer Perceptron – Algorithm1 • 3. Weight Bias Update • BackPropagation • Forward Propagation • Backward Propagation • (Sensitivity)
Multi-Layer Perceptron – Variable • Weight, Bias • Rand 함수로 임의의 값 선정 • HiddenLayer Neuron • 은닉층 뉴런의 개수(HDNEU) • HDNEU가 많을수록 복잡한 문제 해결 가능 • Alpha • Steepest Descent Method에서와 같은 개념 • StopCriteria • 수치적인 Algorithm이므로 학습을 중단할 기준이 필요함 • Mean Square Error로 판단함
Multi-Layer Perceptron – example2(XOR) HDNEU = 20 α = 0.1 Stop Criteria = 0.005 Iteration Number : 480 MSE : 4.85e-3 Elapsed Time : 113.65[sec]
Multi-Layer Perceptron – example3(sine Function) • BP Algorithm • HDNEU= 20 • α = 0.2 • Stop Criteria = 0.005 • Iteration Number : 3000 • 3000번에 수렴 못 함 • 4710번에 수렴 • MSE : 0.0081 • Elapsed Time : 739[sec] • 그림 띄우지 않을 시 7.76[sec]
Multi-Layer Perceptron – Algorithm2 • MOmentumBackPropagation • Backpropagation Algorithm + Low Pass Filter • Weight, Bias Update • Variable • Gamma(γ) – 전달함수에서의 pole
Multi-Layer Perceptron – example3(sine Function) • MOBP Algorithm • HDNEU = 20 • α = 1 • γ = 0.9 • Stop Criteria = 0.005 • Iteration Number : 625 • MSE : 0.005 • Elapsed Time : 150[sec]
Multi-Layer Perceptron – Algorithm3 • Conjugate GradientBackPropagation • 최적화이론의 ConjugateGradient Method 인용 • 복잡한 알고리즘이지만 수렴속도는 빠름 • Variable • α, γ불필요 • HDNEU, Stop Criteria • Algorithm • Step1. Search Direction( ) • Step2. Line Search( ) • Step3. Next Search Direction( ) • Step4. if Not Converged, Continue Step2
Multi-Layer Perceptron – example3(sine Function) • CGBP Algorithm • HDNEU = 20 • Stop Criteria = 0.005 • Iteration Number : 69 • MSE : 0.0046 • Elapsed Time : 22[sec]
Multi-Layer Perceptron – example3(sine Function) • HDNEU = 20 • Stop Criteria = 0.0005 • Iteration Number : 125 • MSE : 0.0005 • Elapsed Time : 37[sec]
Multi-Layer Perceptron – Local Minima • Global Minima : 전역적 최소값 • LMS Algorithm은 언제나 Global Minima 보장 • Local Minima : 국소적 최소값 • BP Algorithm은 Global Minima 보장 못 함 • 여러 번의 시뮬레이션이 필요함 • HDNEU = 10 • Stop Criteria = 0.001 • Iteration Number : 3000 • MSE : 0.2461 • Elapsed Time : 900[sec]
Multi-Layer Perceptron – Over Parameterization • Over Parameterization • 신경회로망에서 은닉층 내의 뉴런의 개수가 필요이상으로 많을 때, 학습 데이터는 제대로 학습 시키지만그 외의 데이터에서는 오차가 발생하는 것 • GeneralizationPerformance(일반화 성능) • 학습 데이터가 아닌 다른 입력을 통해 신경회로망의 성능을 시험하는 것
Multi-Layer Perceptron – Scaling • Ex) 전력수요 예측 • [어제 전력수요;요일;최고온도;최저온도] – 하루치 데이터 • OriginData • [34780 31252 39317 • 7 1 2 • 34 32 33 • 20 23 24] • ModificationData • [0.4374 0 0 • 1 0 0.1667 • 1 0 0.5 • 0 0.25 1] • 모든입력의 attribute를 0~1사이의 값으로 만드는 것 • 학습 데이터로 Scaling할 때, 최대·최소값을 저장하고 그 값을 통해 검증 데이터를 Scaling 한다. • NearestNeighbor에서의 normalize 개념과 유사 • 선택사항 – Target 값의 Scaling 유무 • Target 값이 백단위 이상이라면 Scaling 필요
Multi-Layer Perceptron – Scaling • 전력수요예측 Simulation • HDNEU= 20, Stop Criteria = 0.01, Max Iteration Number = 1000 • Case1. Not Scaling • Iteration Number : 1000, Train Set MSE : 11,124,663, Test Set MSE : 20,425,686 • Case2. Scaling • Iteration Number : 1000, Train Set MSE : 11,124,663, Test Set MSE : 20,425,686 • Case3. Target Scaling • Iteration Number : 6, Train Set MSE : 0.008628, Test Set MSE : 0.0562
Multi-Layer Perceptron – Overfitting • ☆Issue • 1. Stop Criteria를 얼마로 선정해야 하는가? • 2. HDNEU는 몇 개가 적당한가? • Stop Criteria : 0.01 / 0.001 • Test Set MSE : 0.0562 / 0.1697 • Overfitting • Stop Criteria를 지나치게 작게 선정하여 학습 데이터의 에러는 작아지도록 Weight, Bias를 학습시키나 검증 데이터의 에러는 오히려 커져서 일반화 성능이 떨어지는 것을 말한다.
Reference Machine Learning, Tom Mitchell, McGraw Hill. Introduction to Machine Learning, EthemAlpaydin, MIT press. Neural Network Design, Martin T.Hagan, Howard B.Demuth, Mark Beale, PWS Publishing Company. Neural Networks and Learning Machine, Simon Haykin, Prentice Hall.