Download

1 / 14
140 likes | 156 Views
A comprehensive study on Acoustic Segment Modeling (ASM) for language identification without phonetic transcription. The method utilizes feature vectors extracted from different languages for accurate identification.

E N D
A Vector Space Modeling Approach to Spoken Language Identification Haizhou Li, Bin Ma, Chin-Hui Lee IEEE Transactions on Audio, Speech and Language Processing 2007 Yu-chen Kao Department of Computer Science & Information Engineering National Taiwan Normal University 2010.03.22
Outline • Introduction • Self-taught Learning • Acoustic Segment Modeling • Extraction of Feature Vectors • Experiments
Introduction • Typical method: PPR-LM
Introduction • Another method: UPR-LM
Introduction • Purposed method: PPR-VSM and UPR-VSM
Acoustic Segment Modeling: Introduction • ASM (Acoustic Segment Modeling): a proposed unsupervised way to train the set of universal acoustic units. • Without the need of phonetic transcription • Intended to cover the entire sound space of all spoken languages in an unsupervised manner. • An API (Augmented Phoneme Inventory), which forms a superset of phonemes, is used to bootstrap ASM
Acoustic Segment Modeling: Training • Carefully select a few languages, typically with large amounts of labeled data, and train language-specific phone models. Choose a set of J models for bootstrapping • Decoding, force-align and segment all training utterances. • using the available set of labels and HMMs. • Group all segments corresponding to a specific label into a class. Use these segments to retrain an HMM. • Repeat 2-3 several times until convergence.
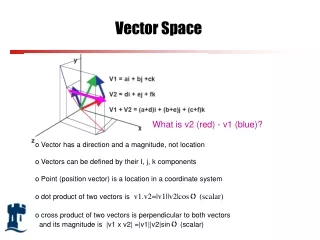
Extraction of Feature Vectors • AW (Acoustic Word): composed of acoustic units in the form of n-gram. • According to Zipf’s Law, some AWs can be seen as stop words and effectively reduce the vector dimension and computation cost. • After the feature extraction step, we can feed it into an SVM classifier or ANN after dimensionality reduction.
Setup of Experiments • Training Data • IIR-LID Corpus: 3 languages • OGI-TS Corpus: 6 languages • LDC Call-Friend Corpus: 12 languages • Testing Data • 1996/2003 NIST LRE: Recorded telephony speech of 12 languages
Experiments CT: Count Trimming MI: Mutual Information SM: Seperation Margin