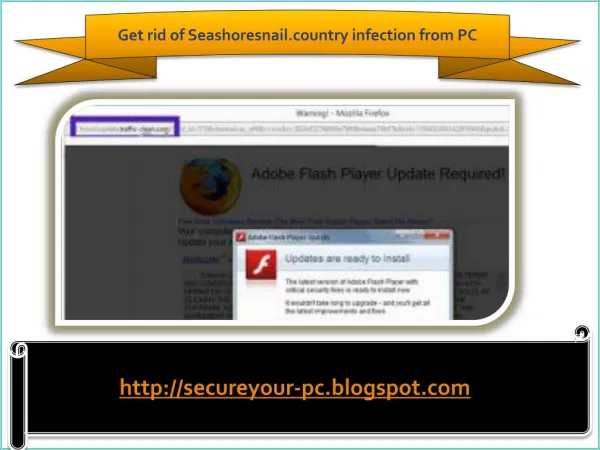
Download

1 / 27
270 likes | 364 Views
CACHETOR Detecting Cacheable Data to Remove Bloat. Khanh Nguyen Guoqing Xu UC Irvine USA. Introduction. Bloat: Excessive work to accomplish simple tasks Modern software suffers from bloat [ Xu et.al., FoSER 2010] It is difficult for compilers to remove the penalty

E N D
CACHETORDetecting Cacheable Data to Remove Bloat Khanh Nguyen Guoqing Xu UC Irvine USA
Introduction • Bloat: Excessive work to accomplish simple tasks • Modern software suffers from bloat [Xu et.al., FoSER 2010] • It is difficult for compilers to remove the penalty • One pattern: repeated computations that have the same inputs and produce the same outputs • 4 out of 18 best practices (IBM’s)* are to reuse data Khanh Nguyen - UC Irvine * www.ibm.com/software/webservers/appserv/ws_bestpractices.pdf
Example float[] fValues = {?, ?, ?, ?, . . . , ?}; float[] fValues = {0.0, 1.0, 2.3, 1.0, 1.0, 3.4, 1.0, 1.0, . . . , 1.0}; int[] iValues = new int[fValues.length] ; for (int i = 0; i < fValues.length; i++){ iValues[i] = Float.floatToIntBits(fValues[i]); } {adapted from sunflow, an open-source image rendering system} intcached_result = Float.floatToIntBits(1.0); if (fValues[i] == 1.0) iValues[i] = cached_result; else iValues[i] = Float.floatToIntBits(fValues[i]); Khanh Nguyen - UC Irvine
The Big Picture • Dynamic Dependence Analysis • Dependence Profile/Graph • I-Cachetor • D-Cachetor • M-Cachetor Inst.: a = b+c; Obj.: a = new A(); Call: a = f(); Khanh Nguyen - UC Irvine
Cachetor • Introduction • Scalable algorithms for the dependence analysis • 3 detectors • Evaluations Khanh Nguyen - UC Irvine
Abstract Value Profiling In Theory In Practice • Full Value Profiling • Cachetor • Abstract Dynamic Slicing • Full Dynamic Slicing Khanh Nguyen - UC Irvine
Overview • Combine value profiling and dynamic slicing in a mutually-beneficial and scalable manner • Distinct values are used to abstract instruction instances • Result: an abstract dependence graph • Nodes: abstract representations of runtime instances • Edges: dependence relationships between nodes Khanh Nguyen - UC Irvine
Equivalence Class • Instruction i Inst. instances f1 Khanh Nguyen - UC Irvine
Equivalence Class Values created Inst. instances Unbounded f1(inst. instance) = value created
Values created Inst. instances Bounded Size N -Top-N ? - Hashing ? f2 Unbounded f1
Values created Inst. instances Size N - Hashing f2 value % N f1
Another Abstraction Level • Context sensitive: • To distinguish entities based on the calling context • To improve the tool’s precision • Please refer to our paper for details Khanh Nguyen - UC Irvine
Cacheability • Quantitative measurement indicating how likely a program entity will keep producing/containing identical values • Compute cacheability for 3 kinds of program entities: • Instruction a = b+c; • Data structure a = new A(); • Method call a = f(); • Rank and report top entities Khanh Nguyen - UC Irvine
Cachetor • Introduction • Scalable algorithms for the dependence analysis • 3 detectors • Evaluations Khanh Nguyen - UC Irvine
I-Cachetor • 0 • 3 • Detect instructions that create identical values • Compute cacheability for each static instruction (Inst.CM) • Cacheability: • 1 • 2 1 4 2 1 4/8 = 0.5
D-Cachetor: Overview • 2 steps: • Step 1: detect cacheable individual objects • Step 2: detect cacheable data structure • Compute cacheability for each allocation site node
D-Cachetor: Step 1 • Compute cacheability for each object (Obj.CM), not considering reference relationships • Focus: instructions that write primitive-typed fields a = new A()1 … t 1 2 a.h = d<5,7> a.f = b<2,3> a.g = c<3,3> a.… = …
D-Cachetor: Step 2 • Group objects using the reference relationships • Compute DataStructureCM • Focus: instructions that write reference-typed fields • Add only objects whose Obj.CM is within a range ds= new DS()2 a = new A()4 b = new B()6 c = new C()2 d = new D()7
M-Cachetor • Detect method calls that have the same inputs and produce the same outputs • Compute CallSiteCM • For each call site c: a = f( ), CallSiteCM is: • If a is primitive: CallSiteCM = Inst.CMc • If a is reference: CallSiteCM = the average of DataStructureCM of all data structures rooted at a
Implementation • Jikes RVM 3.1.1 • Optimizing-compiler-only mode • Context-sensitive • Evaluated on 14 benchmarks from DaCapo & Java Grande Khanh Nguyen - UC Irvine
Overheads Khanh Nguyen - UC Irvine
Case Studies Khanh Nguyen - UC Irvine
False Positives Numbers of false positives identified among top 20 items in the reports of D-Cachetorand M-Cachetor. Khanh Nguyen - UC Irvine
False Positives Sources • Handling of floating point values • Context-sensitive reporting • Missing the actual values • Hashing-induced false positives Khanh Nguyen - UC Irvine
Conclusions • Cachetor - novel tool, supports detection of cacheable data to improve performance • Scalable combination of value profiling and dynamic slicing • 3 detectors that can detect cacheable: • Instructions • Data structures • Method calls • Large optimization opportunities can be found from Cachetor’s reports Khanh Nguyen - UC Irvine
THANK YOU! Questions - Comments? Khanh Nguyen - UC Irvine
What happened in montecarlo? public void runSerial() { results = new Vector(nRunsMC); // Now do the computation. PriceStockps; for( intiRun=0; iRun < nRunsMC; iRun++ ) { ps= new PriceStock(); ps.setInitAllTasks(initAllTasks); ps.setTask(tasks.elementAt(iRun)); ps.run(); results.addElement(ps.getResult()); } ps.setTask(iRun, (long)iRun*11); {Calculate the result on the fly} private void processSerial() { processResults(); } private void initTasks(intnRunsMC) { tasks = new Vector(nRunsMC); for( inti=0; i < nRunsMC; i++ ) { String header= "MC run “ + String.valueOf(i); ToTasktask = new ToTask(header, (long)i*11); tasks.addElement((Object) task); } } Khanh Nguyen - UC Irvine