Download

1 / 34
360 likes | 511 Views
Y.Y . Yao Dept of Computer Science University of Regina Presented by Mohamad Seif Dept of Computer Science UNCC 11/24/2008. Granular Computing for the Design of Information Retrieval Support System.

E N D
Y.Y . Yao Dept of Computer Science University of Regina Presented by Mohamad Seif Dept of Computer Science UNCC 11/24/2008 Granular Computing for the Design ofInformation Retrieval Support System
IR systems used as a tool for searching for relevant information. Current IR systems & challenges: Focus on the retrieval functionality Do not understand the meaning of user query & document contents . Translating info needs into queries. Matching queries to stored information We need new generation of IR that support user tasks in finding & utilizing information. IRSS is the potential solution: Framework that support scientific research. Provides models, tools, utilities to allow the user to explore both semantic & structural information of each document. Presentation Overview
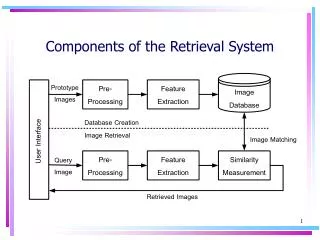
The three components, user, resource, and intermediary and their interactions with one another , together constitute the Information Retrieval System(IR). IR Situation User Intermediary Resource
Information retrieval is a communication process, by which users of information system can find information that matches their needs ((solve a problem, make a decision).) IR goal is to provide, identify, and rank useful documents from a large collection of documents. IR
IR(Cont) • Conceptually, IR is used to cover all related problems in finding needed information. • Historically, IR is about document retrieval. • Technically, IR refers to (text) string manipulation, indexing , matching, querying, etc.
IR(Cont) • What do we retrieve? • Data • Information • Knowledge • Data does not have meaning of itself, data items need to be part of a structure like a sentence to give them meaning. • Information: The meaning of the data interpreted by a system or person. It adds context and meaning to the data. • Text: Strings of ASCII symbols. If understood it’s information. • Documents: logical unit of text (articles, books, web pages).
IR & DR Information retrieval vs. Data retrieval
IR & WWW • The WEB, digital libraries, and markup languages are new challenges to IR researchers. • The WEB has significant impact on academic research, however making effective use of it is a challenge for scientists. • Many of Search engines inherit disadvantages of traditional IR systems.
IR Limitations • Current IR limitations • IR focus mainly on the retrieval functionality. There is little support for others activities of scientific research. • Does not attempt to understand the “meaning” of user’s query (because users use very few terms in search queries ). • Does not inform the user on the subject of his inquiry. It merely informs on the existence or non-existence of documents related to his request. • Current IR techniques are unable to exploit the semantic knowledge within documents and hence cannot give precise answers to precise questions. • IR use simple pattern based matching to identify documents
IR & IRSS • IR are not sufficient to support research on the new WEB platform. • So we introduce IRSS (Information Retrieval Support System) framework for supporting scientific research. • IRSS is a framework for supporting scientific research. • IRSS provides models, tools, and functionalities.
Granular Computing • The concept of GrC originally called information granulation. • The term is first used in 1996-1997. • Granulation seems to be natural problem-solving methodology deeply rooted in human thinking. • Human body granulated into head, neck, …etc, so the noting is fuzzy and vague. • Granulation involves partitioning class of objects into granules. • GrC deals with representing information in the form of aggregates (embracing a number of individual entities) and their processing. • GrC is knowledge-oriented (data mining ).
Information Granules • IG arise in the process of data abstraction and derivation of knowledge. • IG Are collections of entities. They are arranged together due to their similarity, functional adjacency, coherency or alike. • An image of any landscape consists of trees, houses, roads, and lakes. All these objects are generic information granules. • The level of information granulation depends on the problem at hand and the need of the decision-making process. With the big view of the world we deal with large granules (continents and countries). When more details are required we move down to regions, provinces, and states. • Information granulation: process of constructing granules.
GrC Components • Granules (Description): • A granule may be interpreted as one of the numerous small particles forming a larger unit. • In set theory: a granule may be interpreted as a subset of a universal set. • In planning: a granule can be a sub-plan . • In programming: a granule can be a program module • The size of a granule is considered as a basic property. Intuitively, the size may be interpreted as the degree of abstraction, concreteness, or detail.
Components of GrC • Granules (Relationships): • Connections and relationship between granules can be represented by binary relations. In concrete models, they may be interpreted as dependency. • For example, based on the notion of size, one can define an order relation on granules. Depending on the particular context, the relation may be interpreted as “greater than or equal to” or “more abstract than”. • Granules (Operations): • Combining many granules to form a new granule • Decomposing a granule into many granules. The operations on granules must be consistent with the binary relations on the granules. For example, the combined granule should be more abstract than its components
GrC Components • Granules views & Levels • A level consists of a family of granules that provide a complete description of a real world problem, or theory, or design or plan. • Each entity in a level is a granule. • Level = Granulated view = a family of granules • Granules in a level are formed with respect to a particular degree of granularity or detail. • Multiple levels of granularity in any technical writing: High level of abstraction title, abstract Middle levels of abstraction chapter/section titles subsection titles Low level of abstraction text
GrC Components • Granules (Hierarchies) • A hierarchy may be interpreted as levels of abstraction, levels of organization, and levels of detail. • Granules in different levels are linked by the order relations and operations on granules. • A higher level (Generalization) may provide constraint to and/or context of a lower level (Specialization). • A granule in a higher level can be decomposed into many granules in a lower level. • A granule in a lower level may be a more detailed.
Granulation • Granulation: Construction & Decomposition of granules. • Granulation criteria :Why two objects are put into the same granule? • Granulation methods: How to put objects together to form a granule? • Granulation involves the process of 2 directions in problem solving: • Construction involves the process of forming a larger and higher level granule with smaller and lower level granules that share similarity and functionality , based on available information and knowledge. • Decomposition is the process of dividing a larger granule into smaller and lower level granules , based on available information and knowledge.
IR • IR deals with the representation, storage, organization of, and access to information items. • IR designed to identify and rank useful items from a stored information in response to user request. • Scientists use IR as an effective tool to find relevant information
IR Basic Issues • Three fundamental issues in information retrieval: • Document representation (logical view of the documents). • Documents represented as list of words based on limited statistical analysis. We need to consider the semantic information of the document. • Query formulation (translation). • Query might be too Restrictive or too complicated. • A user is not clear what is being searched for. • Retrieval functions. • Retrieval based on keyword level matching . • Documents containing the keywords appearing in the query are retrieved or ranked higher. Other information that may suggest the relevance of documents is not fully explored.
Document Space Granulations • Document clustering is a technique to reduce computational costs and improve retrieval effectiveness. • Clustering ways • Content based: Documents with similar content or topic are put into the same cluster. • Query based: documents are put into the same cluster if they tend to be relevant at the same to some queries. • Citation based : Such clustering methods are used in Research Index, in which, for example, co-cited documents are put into a cluster • Document can be clustered based on authors and journals.
Query Space Granulations • Like the granulation of document space, one can construct granulated views of query space in several ways: • Content based It is similar to content based document clustering. The similarity of queries is evaluated based on index terms used by the queries. Similar queries are grouped together to represent the needs of a group of users. Content based approaches can be easily extended to cluster users based on user profiles or user logs. • Document based This method uses the overlap of relevant documents, retrieval results, of queries.
Unified Probabilistic Model • The relevance of documents to queries is modeled in probabilistic terms. Its 4 sub-models are: • Model 1: based on the granulation of query (user) space . • Model 2: based on the granulation of document space. • Model 3: (no granulation) represents the ideal situation where the relevance of individual documents to individual queries is used. • Module 4 (combination of Model 1 & 2 ): More specifically, the relevance of a particular document to a particular query is estimated by the relevance of the document to a group of queries and the relevance of a group of documents to the query.
Retrieval Results Granulations • IR systems return list of document that is too long and duplicate. So we need clustering to organize the result. • Granulating retrieval results referred to as query specific document classification. • An important issue in query specific document clustering is to obtain a meaningful description of the derived clusters to be presented to the user. • It has been suggested that a few titles and some terms can be used as the description of a cluster . One may also extract some important sentences from the documents in a cluster as a description of the cluster.
Structured and XML Document • The document level structure information can be obtained from the use of markup language. • In XML, the structures and the meaning of data are explicitly indicated by element tags. The structure of a document and element tags are defined through a DTD . • In XML one can cluster documents using certain tag fields. • One may use structured queries by focusing on certain tags or perform free text retrieval by simply ignoring all tags.
DRS to IRS • DRmay be considered as an early stage, and IRS as the next evolutionary stage in the development of retrieval systems. • Both DR and IRfocus on the retrieval functionality, namely, the match of items and user information needs. • The differences between DR and IRcan be seen from the ways in which information items and user information needs are represented, as well as the matching process. • In DR data items and user needs are precisely described, in IR is the opposite. • DRdeals with structured problems, IR deals with semi-structured problems.
IR User Tasks • There are 2 different types of user tasks when using IR system: • A retrieval task Performed by translating an information need into a query and searching using the query. • A browsing task Looking around in a collection of documents through an interactive interface. During browsing the user information need or objective may not be clearly defined, and can be revised through the interaction with the system.
IR to IRSS • IRhave important role in the success of the web, however can still be viewed as document retrieval • IR provide the basic search and browsing functionalities. • The next generation of IRsystems must support more types of user tasks (better understanding), in addition to searching and browsing. • A new set of principles for the design and implementation of the next generation IR systems is needed. • The evolution of retrieval systems leads to the introduction of IRSS (Information Retrieval Support System).
IRSS • IRSSsupports user tasks in finding and utilizing information. • Techniques and principles from DSS (Decision Support System) are applicable to IRSS by substituting “decision making” for the tasks of “information retrieval” • Features of DSS: • Combination of data & models: Models to make sense of the raw data. Therefore DSS deals with both data & their interpretation. • User involvement: An DSS plays a supporting role in problem solving. • Retrieval problem: Finding information from documents are unstructured problems and it is more complicated if the user might not know exactly what being searched for.
IRSS Characteristic • IRSSprovides models, languages, utilities, and tools to allow the user to explore both semantic and structural information of each document as well as the entire collection. • IRSS Models: • Document models: deal with representations & interpretation of documents and the document collection. • Retrieval models: deal with the search. A user can choose different retrieval models with respect to different document models. • Presentation models: deal with the representation and interpretation of results from the search. A user views and arrange results by using distinct models. • The main function of IRSSis to support a user.
IRSS Components • Data management subsystem Deals with raw data management using DBMS. • Model Management Subsystem For analyzing & interpreting the raw data and to build user models. • Knowledge-based Management subsystem Supports other subsystem and provides intelligence to a decision maker. • User Interface Subsystem Handles the interaction between user & the system
A GrC Model for Organizing & Retrieval XML Documents • The granulated representation of an article is the document level granulation. • The collection level granulation “ seek relationships between individual XML documents. A tag or more may be used to form granules. Document might be grouped and divided. • Building hierarchal granulation: at each level the same documents is represented differently. • The granulation of the collection enables the user to understand structural information about the collection. • In GrC model: 3 basics types of operations support the user • Creation of logical views, navigation through different logical views, and retrieval.
Conclusion We discussed: • The application of granule computing to information retrieval. • The introduction of Information Retrieval Support Systems (IRSS).