Download
1 / 1
10 likes | 103 Views
Automatically Detecting Action Items in Audio Meeting Records. William Morgan, Pi-Chuan Chang, Surabhi Gupta, Jason M. Brenier Natural Language Processing Group Department of Computer Science Stanford University, USA. Summary. Results.

E N D
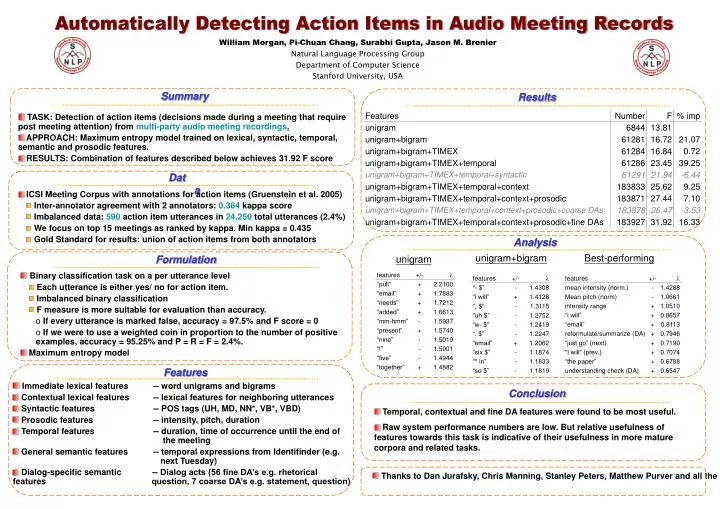
Automatically Detecting Action Items in Audio Meeting Records William Morgan, Pi-Chuan Chang, Surabhi Gupta, Jason M. Brenier Natural Language Processing Group Department of Computer Science Stanford University, USA Summary Results • TASK: Detection of action items (decisions made during a meeting that require post meeting attention) from multi-party audio meeting recordings. • APPROACH: Maximum entropy model trained on lexical, syntactic, temporal, semantic and prosodic features. • RESULTS: Combination of features described below achieves 31.92 F score Data • ICSI Meeting Corpus with annotations for action items (Gruenstein et al. 2005) • Inter-annotator agreement with 2 annotators: 0.364 kappa score • Imbalanced data: 590 action item utterances in 24,250 total utterances (2.4%) • We focus on top 15 meetings as ranked by kappa. Min kappa = 0.435 • Gold Standard for results: union of action items from both annotators Analysis Formulation unigram+bigram Best-performing unigram • Binary classification task on a per utterance level • Each utterance is either yes/ no for action item. • Imbalanced binary classification • F measure is more suitable for evaluation than accuracy. • If every utterance is marked false, accuracy = 97.5% and F score = 0 • If we were to use a weighted coin in proportion to the number of positive examples, accuracy = 95.25% and P = R = F = 2.4%. • Maximum entropy model Features • Immediate lexical features -- word unigrams and bigrams • Contextual lexical features -- lexical features for neighboring utterances • Syntactic features -- POS tags (UH, MD, NN*, VB*, VBD) • Prosodic features -- intensity, pitch, duration • Temporal features -- duration, time of occurrence until the end of the meeting • General semantic features -- temporal expressions from Identifinder (e.g. next Tuesday) • Dialog-specific semantic -- Dialog acts (56 fine DA’s e.g. rhetorical features question, 7 coarse DA’s e.g. statement, question) Conclusion • Temporal, contextual and fine DA features were found to be most useful. • Raw system performance numbers are low. But relative usefulness of features towards this task is indicative of their usefulness in more mature corpora and related tasks. • Thanks to Dan Jurafsky, Chris Manning, Stanley Peters, Matthew Purver and all the anonymous reviewers.






















