Download

1 / 26
260 likes | 430 Views
Hash Tables. Gordon College CS212. Hash Tables. Recall order of magnitude of searches Linear search O(n) Binary search O(log 2 n) Balanced binary tree search O(log 2 n) Unbalanced binary tree can degrade to O(n). Hash Tables. In some situations faster search is needed

E N D
Hash Tables Gordon College CS212
Hash Tables • Recall order of magnitude of searches • Linear search O(n) • Binary search O(log2n) • Balanced binary tree search O(log2n) • Unbalanced binary tree can degrade to O(n)
Hash Tables • In some situations faster search is needed • Solution is to use a hash function • Value of key field given to hash function • Location in a hash table is calculated Like an array but much better: Do not have to set aside space to account for every possible key
Hash Functionsmapping from key to index • Simple function: mod (%) the key by arbitrary integerint h(int i){ return i % maxSize; } • Note the max number of locations in table maxSize
Hash Function Access • Note that we have traded speed for wasted space • Table must be considerably larger than number of items anticipated
Hash Function Access • Example: 7 digit serial number Need 10 million records* * Not practical to have this much space when in reality you are only stocking at most a few thousand records Why 10 million records? n!/(n-r)! 10!/(10-7)! Number of r-permutations of a set with n elements
Hash Function (Mapping) • Example: 7 digit serial number Use only 10000 slots Hashing (Mapping) function - unsigned int Hf(int key) Hf(1234567) = 1234567 % 10000 = 4567 1234567/10000 = 123.4567 1234567 - (123 * 10000) = 4567
Hash Function (Mapping) • Design Considerations • Efficient • Minimize collisions • Produce uniformly distributed mappings • (helps minimize collisions) • Must be able to deal with int, char, string, etc. types for keys • Must be able to associate a hash function with a container
Function Objects • Can pass a function to a function • Can use Function Objects template<typename t> class functionobject { public: returntype operator() (arguments) const { return returnvalue; } ……. };
Function Objects Example function class: less than template<typenameT> classlessThan { public: booloperator() (constT& x, constT& y) const { return x < y; } };
Function Objects Example function class use template <typename T, typename Compare> void insertionSort(vector<T>& v, Compare comp) { int i, j, n = v.size(); T temp; ….. } Called: insertionSort(v, lessThan<int>());
Function Objects Example function class use (as seen with the SET container) template<typenameT> classlessThan { public: booloperator() (constT& x, constT& y) const { return x < y; } }; set <int, lessThan<int> > A(arr, arr+arrSize); for(set <int, lessThan<int> >::iterator ii=A.begin();ii!=A.end();ii++) cout << *ii << " "; cout << endl;
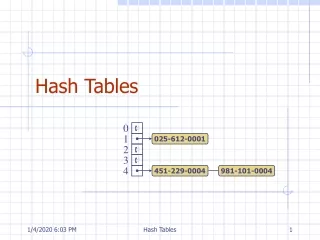
CollisionsHash Function Access Problem Collisions are possible: Depending on the number of slots and the size of the key mapping
CollisionsHash Function Access Problem • Problem: same value returned by h(i) for different values of i • Called collisions • Simple solution: linear probing • Linear search begins atcollision location • Continues until emptyslot found for insertion
Hash Functions • Retrieving a value:linear probe until found • If empty slot encounteredthen value is not in table • What if deletions permitted? • Slot can be marked so it will • not be empty and cause an • invalid linear probe
Hash Functions • Improved performance strategies: • Increase table capacity (less collisions) • Use different collision resolution technique • Devise different hash function • Hash table capacity • Size of table must be 1.5 to 2 times the size of the number of items to be stored • Otherwise probability of collisions is too high
Other Collision Strategies • Linear probing can result in primary clustering Consider: • quadratic probing • Probe sequence from location i isi + 1, i – 1, i + 4, i – 4, i + 9, i – 9, … • Secondary clusters can still form • Double hashing • Use a second hash function to determine probe sequence • hF(key) --> index hF(index)--> next index
Collision Strategies • Chaining • Table is a list or vector of head nodes to linked lists • When item hashes to location, it is added to that linked list
Improving the Hash Function • Ideal hash function • Simple to evaluate (fast) • Scatters items uniformly throughout table • Modulo arithmetic not so good for strings • Possible to manipulate numeric (ASCII) value of first and last characters of a name
Hash Function (basic mapping) class hFintID { public: unsigned int operator() (int item) const { return (unsigned int) item % 10000; } }; hFintID hf; Hf(12341234) = 1234;
Hash Function (better) Midsquare technique mixes up the digits in the serial number class hFint { public: unsigned int operator() (int item) const { unsigned int value = (unsigned int) item; value *= value; value /=256; //discard low order 8 bits // (division performs a shift right) return value % 65536; } };
String Hash Functions class hFstring { public: unsigned int operator() (const string & item) const { unsigned int prime = 2049982463; int n = 0, i; for (i = 0; i < item.length(); i++) n = n*8 + item[i]; return n > 0 ? (n % prime) : (-n % prime); } }; GOAL: random distribution
Custom Hash Functions class hfCode { public: unsigned int operator() (const code & item) const { return (unsigned int )item.getNum % NumofSlots; } }; FILE0000.CHK, FILE0001.CHK, FILE0002.CHK
Search Algorithms Sequential Search - search O(n) (fairly slow) + good when data set size is small and does have to be sorted Binary Search (sorted vector) + search O(log n) [much faster] + low cost when it comes to space - however, requires data be sorted - not good when the data set is very dynamic (sorting overhead) Binary Search Tree + search O(log n) + can scan data in order - higher cost when it comes to space (various pointers) Hashing + search O(1) [fastest] - higher cost when it comes to space (depends on method)