Download
1 / 27
270 likes | 341 Views
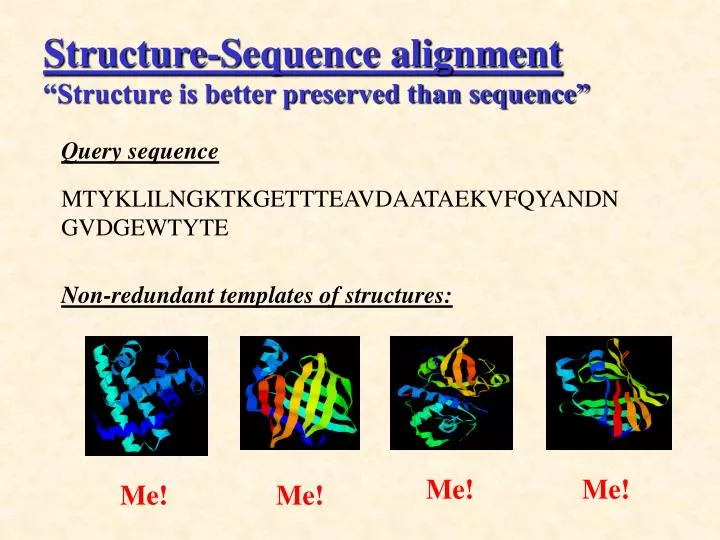
Non-redundant templates of structures:. Structure-Sequence alignment “Structure is better preserved than sequence”. Query sequence MTYKLILNGKTKGETTTEAVDAATAEKVFQYANDNGVDGEWTYTE. Me!. Me!. Me!. Me!. M VNG LILNGKTK------------------------AEKVFQYANDNGVDGEWTYTE. trp (W): probably not here!.

E N D
Non-redundant templates of structures: Structure-Sequence alignment “Structure is better preserved than sequence” • Query sequence • MTYKLILNGKTKGETTTEAVDAATAEKVFQYANDNGVDGEWTYTE Me! Me! Me! Me!
MVNGLILNGKTK------------------------AEKVFQYANDNGVDGEWTYTE trp (W): probably not here! How can we match a sequence and a structure? • MTYKLILNGKTKGETTTEAVDAATAEKVFQYANDNGVDGEWTYTE Sequence: Similar Sequences take this structure (but remember – sequence is less preserved than structure…) Pair-Interaction:How well do AAs get along (Positive hate positive? Maybe not…?) • more: • 2nd structures prediction. • 2nd structures constraints (β-strands forming β -sheets…) • etc. Solvation: which AAs are buried?
GenTHREADER “An Efficient and Reliable Protein Fold Recognition Method for Genomic Sequences”David T. Jones (1999) “What a good presentation!”B. Raveh (2003)
GenTHREADER overview: • Query sequence • MTYKLILNGKTKGETTTEAVDAATAEKVFQYANDNGVDGEWTYTE • Templates • For each template (in the Brookhaven PDB): • Construct a profile sequence • Align with query sequence • Calculate structural parameters (“to be continued…”) • send parameters to a well-trained NEURON NETWORK (like PSIPred…) • OUTPUT: match confidence & alignment
STAGE 1: Building a profile for each template • Start with sequence of template peptide:“MTPAVTTYKLVINGKTLKGETTTKAVDAETAEKAFKQYANDNGVDGVWTYDDATKTFTVTC” • Run BLASTP on OWL non-redundant protein sequence data bank, with sequence as input. • Take all sequences with E-Value < 0.01. • Align using MULTAL – multiple sequence alignment method. • Construct a sequence profile based on BLOSUM 50 matrix.
STAGE 2: Align sequence with a profile • MTYKLILNGKTKGETTTEAVDAATAEKVFQYANDNGVDGEWTYTE SCORE = ? Length of query sequence = ? Length of template profile = ? Length of alignment itself = ?
STAGE 3: calculate (some) structural parameters In stage 2, the sequence was aligned to a profile of the structure. The aligned sequence is now imposed on the 3D structure of the template, and used for ENERGY POTENTIALS calculation.
STAGE 3: structural parameters (cont.): E-Pair (pair interaction potential) • an energy potential for the probability of the interactions observed in this structure. • Distance and sequence separation between certain atoms of two different amino-acids are measured (Cβ – Cβ , Cβ - N, Cβ – O, etc.) • Statistics of known structures were gathered and weighted. • The observed interactions are compared to the statistics • An energy potential is calculated • In essence: the smaller E-Pair, the better. aa 39 aa 157
STAGE 3: structural parameters (cont.): E-Solv (solvation potential) • Degree of burial (DOB) for an amino acid: “the number of other Cβ atoms located within 10Å of the residue’s Cβ atom” • In general, hydrophobic amino acids like to be buried, safely away from water. • Hydrophilic acids might like the outside world better. • Each amino acid DOB is calculated. • It’s compared to statistical occurrence. • ΔEsolv(AA,r) = -RT ln( f(AA,r) / f(r) ) Cβ 10Å Cβ Cβ Cβ Cβ Cβ
STAGE 4: send it all to the (trained) Neuron Network Ouput is a score between 0-1 – translated to confidence level (Low, Medium, High & Certain)
Representatives were taken for different fold types in CATH (“T-Level”). Who trains the Neural network? • CAT numbers were used for comparing pairs. • 9169 chain pairs • 383 pairs shared a common domain fold (= should give a positive answer) • The network was trained with these pairs.
Confidence assignment CERTAIN LOW MEDIUM HIGH
GenTHREADER – what to do with it? • Results on a ‘classic’ test set of 68 proteins: • High true-positive rate: 73.5% correctly recognized, 48.5% with CERTAIN. • Extremely reliable:Every “CERTAIN” prediction was correct. • Fast automatic method. • For 22 of 68 proteins, alignment is over 50% accurate. • Let’s go analyze the Mycoplasma Genitalium with it!
Whole Genome Analysis with GenTHREADER Mycoplasme Genitalium genome analysis – ONE DAY ONLY!
1HGXtemplate ORF MG276 of mycoplasma gen.: spotting a remote homologue • MG276 is an “Adenine Phospho-ribosyl-transferase”(but this information is not given to GenTHREADER) • 1HGX is a template of other Phospho-ribosyl-transferase. • It has only 10% sequence identity with our MG276! • It was found by GenTHREADER as a certain match • E-Pair saved the situation! • But how do we know it’s true?
Substrate Ligand binding site of 1HGX template
Substrate binding sites preserved • Secondary structure prediction of MG276 is similar ORF MG276 of mycoplasma gen.: supporting evidence for 1HGX as a template • We cheated all along…
ORF MG353 of mycoplasma gen.: an ORF with no known function • MG353 – no homologues found in databases • 1HUE is a template of an “Histone-like” protein • Very low sequence similarity with our MG353. • It was found by GenTHREADER as a certain match • Striking similarity in DNA Binding regiondespite overall low sequence similarity
GenTHREADER improvements:(McGuffin, Jones - may 2003) • PSI-BLAST, PSI-PRED (2nd stuructures), some more… • Some Results:
AB-INITIO FOLDING - ROSETTA (Simons et al 1997, 1999, Bystroff & Baker 1998, Bonneau et al 2001) Prediction of a protein fold from scratch? Method I:physically simulate protein folding Problem:CPU time Practical for short peptides APKFFRGGNWKMNGKRSLGELIHTLGDAKLSADTEVVCGI APSITEKVVFQETKAIADNKD WSKVEVHESRIYGGSVTNCK ELASQHDVDGFLVGGASLKPVDGFLHALAEGLGVDINAKH Method II:check probability for all possible conformations Problem:infinite search space Solution: use mother nature – decrease search space
Decreasing the search space using elements from short peptides: • Take fragments of short peptides (3 residues – 9 residues long). • Join them together • Keep the 2nd structures constant. • “Play” with the angles of loop residues. • RESULT: 200,000 decoy structures
In addition - I-Sites prediction 13 local-structure 3D motifs with sequence profiles: • Strong independence of motifs (fold-initiation sites?) • complements secondary structure
Find the correct fold for a given sequence (back to threading…) • P(sequence | structure): • Solvation • 2nd structure – amino acid (proline in helix, etc.) • Pair Interaction • I–Sites prediction for this sequence(3D motifs) – did not contribute to performance • Etc. • P(structure) – sequence independant • 2nd structure packing • Strand hydrogen bonding • Strand assembly in sheets • Structure compactness • Frequency of I-Sites 3D motifs • Etc.
native structures vs. predicted models RESULTS in CASP 4 – Baker’s a winner…
We're done!