Download
1 / 1
10 likes | 153 Views
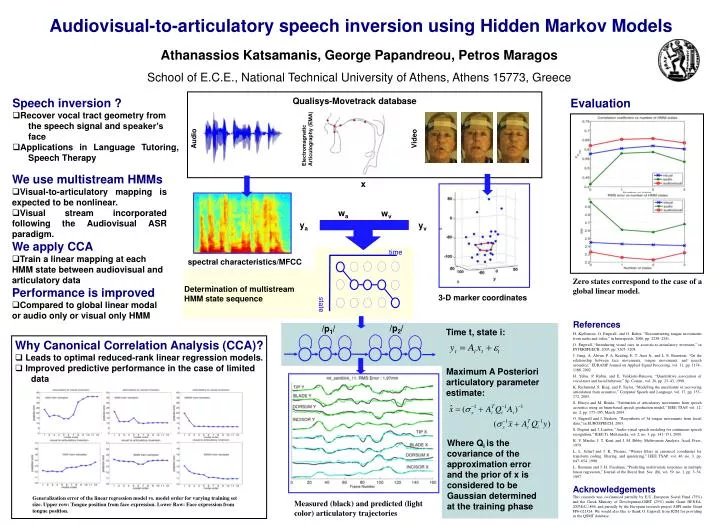
time. state. Audiovisual-to-articulatory speech inversion using Hidden Markov Models. Athanassios Katsamanis, George Papandreou, Petros Maragos School of E.C.E., National Technical University of Athens, Athens 15773, Greece. Qualisys-Movetrack database. Speech inversion ?

E N D
time state Audiovisual-to-articulatory speech inversion using Hidden Markov Models Athanassios Katsamanis, George Papandreou, Petros Maragos School of E.C.E., National Technical University of Athens, Athens 15773, Greece Qualisys-Movetrack database • Speech inversion ? • Recover vocal tract geometry from the speech signal and speaker’s face • Applications in Language Tutoring, Speech Therapy Evaluation Audio Electromagnetic Articulography (EMA) Video • We use multistream HMMs • Visual-to-articulatory mapping is expected to be nonlinear. • Visual stream incorporated following the Audiovisual ASR paradigm. We apply CCA • Train a linear mapping at each HMM state between audiovisual and articulatory data Performance is improved • Compared to global linear modal or audio only or visual only HMM x wa wv ya yv spectral characteristics/MFCC Determination of multistream HMM state sequence Zero states correspond to the case of a global linear model. 3-D marker coordinates References H. Kjellstrom, O. Engwall, and O. Balter, “Reconstructing tongue movements from audio and video,” in Interspeech, 2006, pp. 2238–2241. O. Engwall, “Introducing visual cues in acoustic-to-articulatory inversion,” in INTERSPEECH, 2005, pp. 3205–3208. J. Jiang, A. Alwan, P. A. Keating, E. T. Auer Jr., and L. E. Bernstein, “On the relationship between face movements, tongue movements, and speech acoustics,” EURASIP Journal on Applied Signal Processing, vol. 11, pp. 1174–1188, 2002. H. Yehia, P. Rubin, and E. Vatikiotis-Bateson, “Quantitative association of vocal-tract and facial behavior,” Sp. Comm., vol. 26, pp. 23–43, 1998. K. Richmond, S. King, and P. Taylor, “Modelling the uncertainty in recovering articulation from acoustics,” Computer Speech and Language, vol. 17, pp. 153–172, 2003. S. Hiroya and M. Honda, “Estimation of articulatory movements from speech acoustics using an hmm-based speech production model,” IEEE TSAP, vol. 12, no. 2, pp. 175–185, March 2004. O. Engwall and J. Beskow, “Resynthesis of 3d tongue movements from facial data,” in EUROSPEECH, 2003. S. Dupont and J. Luettin, “Audio-visual speech modeling for continuous speech recognition,” IEEE Tr. Multimedia, vol. 2, no. 3, pp. 141–151, 2000. K. V. Mardia, J. T. Kent, and J. M. Bibby, Multivariate Analysis. Acad. Press, 1979. L. L. Scharf and J. K. Thomas, “Wiener filters in canonical coordinates for transform coding, filtering, and quantizing,” IEEE TSAP, vol. 46, no. 3, pp. 647–654, 1998. L. Breiman and J. H. Friedman, “Predicting multivariate responses in multiple linear regression,” Journal of the Royal Stat. Soc. (B), vol. 59, no. 1, pp. 3–54, 1997. /p2/ /p1/ Time t, state i: • Why Canonical Correlation Analysis (CCA)? • Leads to optimal reduced-rank linear regression models. • Improved predictive performance in the case of limited data Maximum A Posteriori articulatory parameter estimate: Where Qi is the covariance of the approximation error and the prior of x is considered to be Gaussian determined at the training phase Acknowledgements This research was co-financed partially by E.U.-European Social Fund (75%) and the Greek Ministry of Development-GSRT (25%) under Grant ΠΕΝΕΔ-2003ΕΔ866, and partially by the European research project ASPI under Grant FP6-021324. We would also like to thank O. Engwall from KTH for providing us the QSMT database. Generalization error of the linear regression model vs. model order for varying training set size. Upper row: Tongue position from face expression. Lower Row: Face expression from tongue position. Measured (black) and predicted (light color) articulatory trajectories