Download
1 / 14
140 likes | 229 Views

E N D
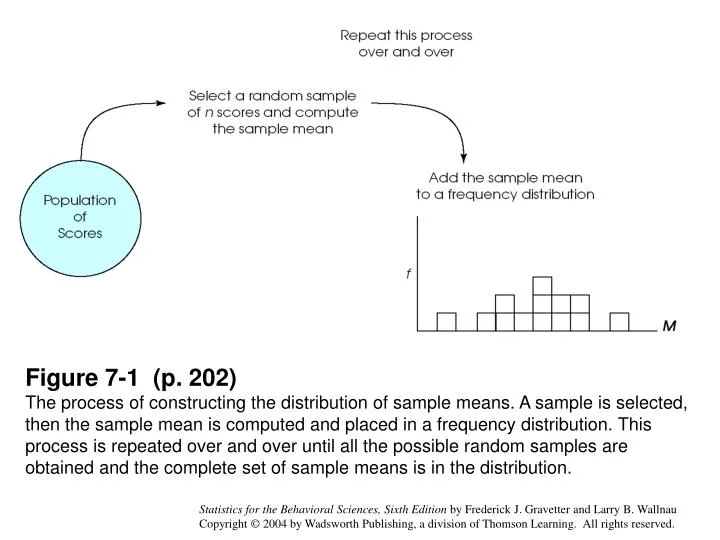
Figure 7-1 (p. 202) The process of constructing the distribution of sample means. A sample is selected, then the sample mean is computed and placed in a frequency distribution. This process is repeated over and over until all the possible random samples are obtained and the complete set of sample means is in the distribution.
Figure 7-2 (p. 203)Frequency distribution histogram for a population of 4 scores: 2, 4, 6, 8.
Table 7-1 (p. 204)All the possible samples of n = 2 scores that can be obtained from the population presented in Figure 7.2. Notice that the table lists random samples. This requires sampling with replacement, so it is possible to select the same score twice. Also note that samples are listed systematically. The first four examples are all the possible samples that have X = 2 as the first score; the next four samples all have X = 4 as the first score; etc. This way we are sure to have all the possible samples listed, although the samples probably would not be selected in this order.
Figure 7-3 (p. 205)The distribution of sample means for n = 2. The distribution shows the 16 sample means from Table 7.1.
Table 7-2 (p. 209)The relationship between standard error and sample size.
Figure 7-4 (p. 210) The distribution of sample means for n = 25. Samples were selected from a normal population with µ = 500 and σ = 100.
Figure 7-5 (p. 212) The middle 80% of the distribution of sample means for n = 25. Samples were selected from a normal population with µ = 500 and σ = 100.
Figure 7-6 (p. 214) An example of a typical distribution of sample means. Each of the small boxes represents the mean obtained for one sample.
Figure 7-7 (p.215) The distribution of sample means for random samples of size (a) n = 1, (b) n = 4, and (c) n = 100 obtained from a normal population with µ = 80 and σ = 20. Notice that the size of the standard error decreases as the sample size increases.
Table 7-3 (p. 216) The mean self-consciousness scores for participants who were working in front of a video camera and those who were not (controls).
Figure 7-8 (p. 217) The mean (±SE) score for treatment groups A and B.
Figure 7-9 (p. 217) The mean (±SE) number of mistakes made for groups A and B on each trial.
Figure 7-10 (p. 219)The structure of the research study described in Example 7.5. The purpose of the study is to determine whether or not the treatment (a growth hormone) has an effect on weight for rats.
Figure 7-11 (p. 220) The distribution of sample means for samples of n = 25 untreated rats (from Example 7.5).