Download

1 / 22
220 likes | 368 Views
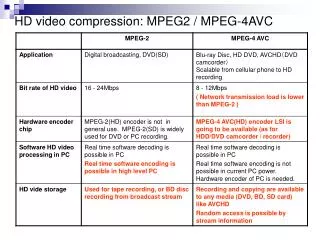
HW-Accelerated HD video playback under Linux. Zou Nan hai Open Source Technology Center. Thread Dispatcher. Video memory. Data port. Sampler. EU Kernel. Media Engine. 3D. Command Streamer. Indirect data. URB. Media (Video Front End). Thread Spawner. Thread payload. VFE or host.

E N D
HW-Accelerated HD video playback underLinux Zou Nan hai Open Source Technology Center
Thread Dispatcher Video memory Data port Sampler EU Kernel Media Engine 3D Command Streamer Indirect data URB Media (Video Front End) Thread Spawner Thread payload
VFE or host IDCT VLD IS IQ MC Mode of operation Coded data Output pixel EU Kernels
IQ MC VLD IS IDCT Current XVMC implementation coded data Host Software per slice data per macroblock data Output pixel EU Kernels
XVMC mpeg stream Media Application decode slice of macro blocks XVMC lib X Server DRI interface render , sync, resource management media commands, video memory management Graphic Hardware
media surface media surface media surface surface state surface state surface state Video Memory Layout command stream VFE state binding tables media pointer command media object command Interface descriptors selected interface flush command EU kernel Instruction
Execute Unit introduction • SIMD code (variable execute size up to 16) with prediction and control mask. • Float and integer data type • Region based direct and indirect register addressing • Support scalar and immediate source operand
EU Registers • GRF (General Register File) • 256 bits per register (g0, g1, g2, gxx) • MRF (Message Register File) • 256 bits per register (m0, m1, m2, mx), write only, • Used to pass payload from thread to shared function unit. • ARF (Architecture Register File) • e.g null, ip and flag register • Immediate • encoded in instruction
12 4 6 5 0 2 3 13 1 14 8 9 10 11 15 7 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 Register Region 2 1 0 0 g0 (256 bits) 1 origin regnum=5, subregnum=2 2 HorzStride=2 VertStride=16 Type=w Width=8 g5.2<16,8,2>w g15.3<16,16,1>UB Regnum.Subregnum<VertStride,Width, HorzStride>Type
Y Y Y Y X X X X W W W W Z Z Z Z Y X W Z Y X Z W W Y Z X Y Z X W Data operation register 0 register 1 vector register 2 register 3 vector Structure of array ( pixel shader and media code) Array of structure ( vertex shader)
Instruction sample register number VertStride prediction register subregister number (f0) add.sat(16) g28.0<2>ub g3.0<16, 16, 1>f g10.0<16, 16, 1>w {align1} HorizStride type Width Access mode execute size
Instruction set • Normal SIMD instructions • add, mul, avg, mov etc • dp3, dp4 etc • Branch control instructions • If,else, do, while, jmpi etc • branch is needed in media code • Send instructions • communicate with shared function units • media kernel use it to control thread life cycle, read and write into surface
Y X X X X X X X X X X X X X X Y X Y Y Y Y X Y Y Y Y Y Y Y Y Y Y + + + + + + + + + + + + + + + + Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Instruction example g3 g4 g10 g28 add.sat(16) g28.0<2>UB g3.0<16, 16, 1>f g10.0<16, 16, 1>W {align1}
An example Input and output payload register passed from inline data, x, y, mv, field flags etc constant data input Y0-Y3 input U Indirect data payload input V reference Y reference U media read from reference surface reference V tmp registers media write to destination surface Result registers, organized in YUV420 format
Planar data vs Packed data • Easy to handle by media kernel • Hard to apply some filters • Can not be directly used as a sampler source in hardware implementation
Work flow B I P P I P slice of macroblocks inline data Indirect data Media write message DCT Data kernel forward reference frame kernel Destination surface kernel backward reference frame Media read message
About XvMC API • Post processing missing in XvMC API design • Video output mixer.
High Level Language • Why a high level language for media kernel is preferred ? • Easy to debug • Easy to reuse code • Hide platform details, easy to understand and maintain • Possible choice • GLSL is not OK • Simple C extension ?
H.264 • Kernels became much more complex because of difference MC and DCT size combination. • Not suitable on slice level API, because of intra prediction. • Need schedule and dependency control ability for media threads because of intra prediction
VAAPI • picture level API • cover mpeg2 h264 vc1 from different entry points • post processing and video output mixer is missing
TODO • IDCT code optimize • Mpeg2 XVMC VLD extension • VAAPI for mpeg2 • VAAPI for AVC • Video post processing and mixer
Q&A Thank You!







![[ open HD video ]](https://cdn2.slideserve.com/4050249/open-hd-video-dt.jpg)