Download

1 / 62
620 likes | 769 Views
Inverted Index Compression and Query Processing with Optimized Document Ordering. 2009-07-28 SUHARA YOSHIHIKO. Today’s Paper. Hao Yan, Shuai Ding and Torsten Suel Inverted Index Compression and Query Processing with Optimized Document Ordering WWW2009. 背景知識. 背景知識 (1/2).

E N D
Inverted Index Compression and Query Processing with Optimized Document Ordering 2009-07-28 SUHARA YOSHIHIKO
Today’s Paper • Hao Yan, Shuai Ding and Torsten Suel • Inverted Index Compression and Query Processing with Optimized Document Ordering • WWW2009
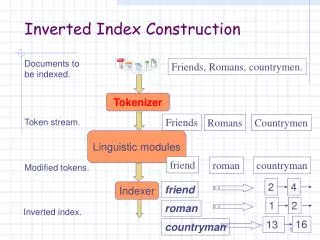
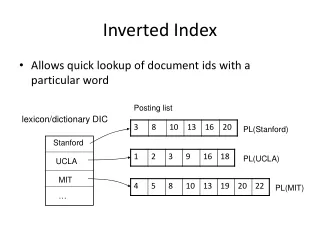
背景知識 (1/2) • 転置リストにはDocIDとTFを格納 • +位置情報など • 転置インデクスの構造 • term -> <DF; DocID:TF, DocID:TF, ... > • e.g., “hoge” -> <5; 1:3, 3:2, 7:3> • DocIDを差分値 (d-gap) に変換して圧縮 • e.g., “hoge” -> <5; 1:3, 2:2, 4:3> d-gapを小さくすれば圧縮効率が向上
背景知識 (2/2) • 同じような単語を含む文書に対して近いDocIDを付与すればよい => DocID reassignmentのモチベーション • 既存研究 • 文書内容に基づくクラスタリング • 計算コスト高 • URLのアルファベットソート [Silvestri 07] • 今のところ最良 • 分散インデクスにも親和性が高い 本研究では[Silvestri 07]に基づいてDocIDを付与
イントロダクション • 転置インデクスの圧縮の貢献 • (1) インデクスサイズ削減 • (2) クエリスループットの向上 • 本研究では • DocID assignmentが最適化された際の圧縮手法の比較分析 • 圧縮手法毎のquery processing performanceを分析
圧縮手法の評価方法 1.圧縮率 2.デコード時間 • エンコード時間はインデクス構築の際に一度かかるだけなので,あまり問題ならない
想定するインデクス構造 • 128個のDocID,128個のTFをブロックとする • 一番上のレイヤーでブロック先頭のDocIDを非圧縮で保持 • パフォーマンスが良い [Zhang 08] docIDとTFで異なる圧縮戦略が取れる [Zhang 08]から抜粋
本研究の貢献 • optimized DocID orderingにおける圧縮手法の比較(圧縮率,デコード速度) • optimized DocID orderingにおけるTF圧縮の最適化 • 従来研究では,DocIDしか考えていなかった • docID reorderingがインデクスサイズとクエリスループットに与える影響を分析 • 一般的なクエリ処理 (Document-at-a-Time; DAAT) を想定 • デコード速度と圧縮率はトレードオフの関係のため,クエリログを解析することによって,適切なハイブリッド手法を設定する方法を提案
本論文の構成 • DocIDの圧縮 • 圧縮率,デコード速度 • TFの圧縮 • 圧縮率,デコード速度 • 混合圧縮方式 • クエリスループットと圧縮効率の関係
インデクス圧縮手法 • Var-Byte coding (var-byte) • Rice coding • S9 • S16 • PForDelta (PFD) • Inetrpolative coding (IPC)
Variable-byte coding (var-byte) • byte-wiseの圧縮アルゴリズム • 8 bitsを以下のように解釈 • 1 bit: continuation bit • code ends (1) or not (0) • 7 bit: payload 00001100111000 = 824
Rice coding • ゴロム符号 (Golomb code) の特殊形 • b=2^kの制約 • ゴロム符号におけるrをバイナリ符号で表現可 • 参考:ゴロム符号 • (x – 1) / b = q … r とする • q+1をunary符号化,rを接頭符号になるよう符号化 • r = 0,1,2 -> 0, 10, 11 • 例)b=3, x=9 -> q = 2, r = 2 -> 110 11
補足:ライス符号が嬉しい理由 • 後半部分で符号化する,余り部分の候補数もb • b=3の場合,余りの候補数もまた3個 (0,1,2) • 接頭符号を生成する符号木は,以下のようになる 1 0 1 0 0 10 11 • bを2のべき乗に設定すると,余り候補も2のべき乗個 • 符号木がバランスするため,log bビットのバイナリ符号で表現可
Simple9 (S9) • 32ビット (1ワード) の分割方法を先頭4ビットで表現 [Anh 05] 0000 0001 0010 ・・・
Simple16 (S16) • せっかく4ビットあるから,32ビットの分割方法を16通り設定 [Zhang 08] • 詳細は記述されておらず • 例1){6, 6, 6, 10, 10} • 例2){2, 2, 2, 2, 2, 6, 6, 6}
PForDelta (PFD) • 分岐予測が発生しない圧縮アルゴリズム • 高速なデコードを実現するよう設計 • 圧縮率はそこそこ,速度は最高速
PForDeltaによるencode • 128個 (32の倍数) の整数を1ブロックとして圧縮 • 全体の90%の値が収まるビット数bを設定 • bビットで表現できない値は例外 (exception) とする • 例外が出現するエントリポイントには,次の例外へのオフセットを格納する <1, 2, 1, 4, 3, 2, 7, 5, ...> b=2 01 10 01 10 11 10 00 ... entry: 410 710 510 exception: bの値,例外の開始位置を保持 header:
PForDeltaによるdecode • 2-phaseに分けて復号する (1) headerに格納されたbの値に基づき,数を復号 ... 01 10 01 10 11 10 00 b=2 1 2 1 2 3 3 0 ... (2) 例外を置換して,元の数列を復元 1 2 1 2 3 3 0 ... 410 510 710 exception: <1, 2, 1, 4, 3, 2, 7, 5>
PForDeltaの問題点 • 次の例外までのオフセットをbビットで表現できない場合,例外でない値を例外と見なして対処する必要性 • bを大きくすると,今度はエントリのサイズが大きくなってしまう <7, 2, 1, 2, 3, 2, 5, 5, ...> 11 10 01 11 11 10 00 ... entry: 710 210 510 exception: 例外同士が離れているため,便宜的に例外を生成
Interpolative coding (IPC) • 差分値d-gapsではなく,docIDをそのまま圧縮 • 分割統治法を用いた処理 • 圧縮率は最高レベル,処理速度に課題 • 例) • 前後のdocIDが8と11であることがわかれば, 8 < x < 11より,x (=9) を1bitで表現可能 DocIDの最大値 = 20
Interpolative coding (IPC) binary_code (target, lo, hi) を呼び出す順番
Interpolative codingアルゴリズム (Managing Gigabytesから抜粋)
各手法の最適化 • 各手法を最適な手法に改良 • (1) New PFD (提案手法) • (2) OptPFD (提案手法) • (3) GammaDiff coding • (4) S16-128 coding • (5) Optimized IPC
00012 00102 00012 ... 210 010 (1) NewPFD • PForDeltaにおいて,例外でない値を例外として扱う問題点を改良 • (1) 例外のオフセット情報を配列に保持 • (2) 例外エントリには,次の例外へのオフセットではなく,例外の下位bビットを格納 • (3) bビットで表現できなかった値を別の配列に保持 <1, 2, 1, 4, 3, 2, 9, 5, ...> 例外の下位ビットを保持 b=2 01 10 01 00 11 10 01 01 entry: overflow bits: 任意の手法で圧縮可能 (論文ではS16を利用) offset:
(2) OptPFD • PForDeltaの最適なパラメータbを決定する改良 • 例外の許容値を元に,bを設定する方法では,最適な圧縮やデコード速度が得られないことがわかった • 後述するハイブリッドな圧縮方式を決定する戦略と同じ方法でbを最適化する • (1) 各ブロックについて,最小サイズの圧縮が得られるbを初期値に設定 • (2) サイズ増加あたりの処理時間削減が最大となるブロックのbを変更 • 目標となる処理時間を与えれば,単純なbの選択方法を導くことができる • どうやって?
(3) GammaDiff • ガンマ符号 • 1 + floor(log x) をunary符号:後半の符号長を表現 • x – 2 ^ floor(log x)をbinary符号 • 例)x = 9 -> 1 + floor(log x) = 4 • -> 1110 001 • GammaDiff: ガンマ符号の改良 • 前半部分を転置リストの平均差分値の符号長との差に置換 • 例) • 転置リストの差分値の平均=2 (log2 = 1) の場合 • x = 9 -> 1 + floor(log x) – log2 + 1 = 3 • -> 110 001 差が負の場合どうするんだろう?
(4) S16-128 • S16を,より小さい値に対応するよう改良 • 具体的なアサイン方法は記述されておらず
(5) Optimized IPC • IPC: xを<lo, hi>の範囲においてbビットのバイナリ符号に変換 • ゴロム符号と同じように接頭符号を作成することで,単純なbビットのバイナリ符号よりも削減可能 • アルゴリズム • b = ceil( r ) ただし r = log(hi – lo + 1) • rが2のべき乗でなかった場合,無駄ビットが発生 • x - lo < 2b - rの場合,b-1ビットで圧縮可能 • その他の場合,x – lo + 2b – rをbビットで表現
DocIDの差分値の分布 • 差分値をバイナリ表現した際のビット長の分布
DocIDの圧縮率比較 • TREC GOV2 datasetからランダムに選択されたクエリに対する転置リストサイズの比較
var-byteについて • Q. sortによって圧縮率の向上が見られない?おかしいんじゃねーの?? • Suel先生の回答 • A1. sortせずとも殆どのd-gapsが128未満 • var-byteは最低でも1byte (8bit) 使用してしまうbyte-wise手法ゆえの問題 • A2. インデクスサイズは下記のとおり • unsorted: docID=7501MB, TF=5823MB • sorted: docID=6646MB, TF=5823MB
DocID reorderingの効果 • DocID reorderingによるIPC手法の比較
TFの変換 • そのままTFを圧縮するのではなく,変換を行った後に圧縮することで圧縮効率を向上 • 本研究で利用する変換方法 • (1) Move-To-Front (MTF) • (2) Most-Likely-Next (MLN)
(1) Move-To-Front (MTF) • 数字をindex arrayの位置に変換し,使用したindexの値を先頭に移動 • 先頭ではなく,i/2や2i/3に移動というヒューリスティクスが有効 • 例) • a list of numbers: [5, 5, 5, 3, 2, 2] • index array: <1, 2, 3, 4, 5> • (index: <1, 2, 3, 4, 5>) • <5> (index: <5, 1, 2, 3, 4>) • <5, 1> (index: <5, 1, 2, 3, 4>) • <5, 1, 1> (index: <5, 1, 2, 3, 4>) • <5, 1, 1, 4> (index: <3, 5, 1, 2, 4>) • <5, 1, 1, 4, 1> (index: <3, 5, 1, 2, 4>)
(2) Most-Likely-Next (MLN) • ある値の次に現れる値の頻度に基づいて変換 • MTFに比べて圧縮率,デコード速度で上回る • QxQ行列を作成 (e.q., Q=16) • (i, j)成分は,値iの次に(j+1)番目の頻度で出現する値を保持 • 変換対象の値をひとつ前の値に対する順位で置換 • Q番目より大きい値については変換せず
TFの圧縮率比較 • context sensitiveな手法 (左側) はソートの効果あり • 近い値のTFがかたまることによる恩恵
TFの圧縮:PFDの比較 • PFD手法の中では,圧縮率,デコード速度ともにOptPFDが優れている
TFの圧縮:圧縮単位の比較 • ブロックごとの圧縮の方がよい