Download

1 / 29
290 likes | 465 Views
Streaming Supercomputer Strawman Architecture. November 27, 2001 Ben Serebrin. High-level Programming Model. Streams are partitioned across nodes. Programming: Partitioning. Across nodes is straightforward domain decomposition Within nodes we have 2 choices (SW) Domain decomposition

E N D
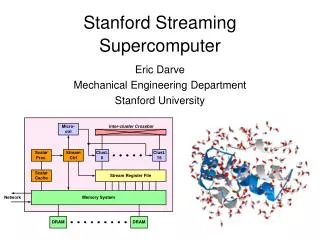
Streaming Supercomputer Strawman Architecture November 27, 2001 Ben Serebrin
High-level Programming Model • Streams are partitioned across nodes
Programming: Partitioning • Across nodes is straightforward domain decomposition • Within nodes we have 2 choices (SW) • Domain decomposition • Each cluster receives neighboring record
High-level Programming Model • Parallelism within a node
Compound operations on records Traverse operations first and records second Temporary values encapsulated within kernel Global instruction bandwidth is of kernels Group whole records into streams Gather records from memory – one stream buffer per record type Simple operations on vectors of elements First fetch all elements of all records then operate Large set of temporary values Global instruction bandwidth is of many simple operations Group like-elements of records into vectors Gather elements from memory – one stream buffer per record element type Streams vs. Vectors
t33w t23w t13w t03w t21y t00x t10x t20x t30x t01y t11y t31y t12z t02z t22z t32z w’ y’ x’ z’ w y x z Example – Vertex Transform input record result record intermediate results
encapsulate intermediate results enable small and fast LRFs large working set of intermediates must use the global RF Example
Instruction Set Architecture • Machine State • Program Counter (pc) • Scalar Registers: part of MIPS/ARM core • Local Registers (LRF): local to each ALU in cluster • Scratchpad: Small RAM within the cluster • Stream Buffers (SB): between SRF and clusters • Serve to make SRF appear multi-ported
Instruction Set Architecture • Machine state (continued) • Stream Register File (SRF): Clustered memory that sources most data • Stream Cache (SC): to make graph stream accesses efficient. With SRF or outside? • Segment Registers: A set of registers to provide paging and protection • Global Memory (M)
ISA: Instruction Types • Scalar processor • Scalar: Standard RISC • Stream Load/Store • Stream Prefetch (graph stream) • Execute Kernel • Clusters • Kernel Instructions: VLIW instructions
ISA: Memory Model • Memory Model for global shared addressing • Segmented (to allow time-sharing?) • Descriptor contains node and size information • Length of segment (power of 2) • Base address (aligned to multiple of length) • Range of nodes owning the data (power of 2) • Interleaving (which bits select nodes) • Cache behavior? (non-cached, read-only, (full?)) • No paging, no TLBs
ISA: Caching • Stream cache improves bandwidth and latency for graph accesses (irregular structures) • Pseudo read-only (like a texture cache—changes very infrequently) • Explicit gang-invalidation • Scalar Processor has Instruction and Data caches
Global Mechanisms • Remote Memory access • Processor can busy wait on a location until • Remote processor updates • Signal and Wait (on named broadcast signals) • Fuzzy barriers – split barriers • Processor signals “I’m done” and can continue with other work • When next phase is reached the processor waits for all other processors to signal • Barriers are named • can be implemented with signals and atomic ops • Atomic Remote Operations • Fetch&op (add, or, etc …) • Compare&Swap
Scan Example • Prefix-sum operation • Recursively: • Higher level processor (“thread”): • clear memory locations for partial sums and ready bits • signal Si • poll ready bits and add to local sum when ready • Lower level processor: • calculate local sum • wait on Si • write local sum to prepared memory location • atomic update of ready bit in higher level
uArch: Scalar Processor • Standard RISC (MIPS, ARM) • Scalar ops and stream dispatch are interleaved (no synchronization needed) • Accesses same memory space (SRF & global memory) as clusters • I and D caches • Small RTOS
uArch: Arithmetic Clusters • 16 identical arithmetic clusters • 2 ADD, 2 MUL, 1 DSQ, scratchpad (?) • ALUs connect to SRF via Stream Buffers and Local Register Files • LRF: one for each ALU input, 32 64-bit entries each • Local inter-cluster crossbar • Statically-scheduled VLIW control • SIMD/MIMD?
uArch: Stream Register File • Stream Register File (SRF) • Arranged in clusters parallel to Arithmetic Clusters • Accessible by clusters, scalar processor, memory system • Kernels refer to stream number (and offset?) • Stream Descriptor Registers track start, end, direction of streams
uArch: Memory • Address generator (above cache) • Creates a stream of addresses for strided • Accepts a stream of addresses for gather/scatter • Memory access: • Check: In cache? • Check: In local memory? • Else: Get from network • Network • Send and receive memory requests • Memory Controller • Talks to SRF and to Network
Feeds and Speeds: in node • 2 GByte DRDRAM local memory: 38 GByte/s • On-chip memory: 64 GByte/s • Stream registers: 256 GByte/s • Local registers: 1520 GByte/s
Feeds and Speeds: Global • Card-level (16 nodes): 20 GBytes/sec • Backplane (64 cards): 10 GBytes/sec • System (16 backplanes): 4 Gbytes/sec • Expect < 1 msec latency (500 ns?) for memory request to random address
Open Issues • 2-port DRF? • Currently, the ALUs all have LRFs for each input
Open Issues • Is rotate enough or do we want fully random access SRF with reduced BW if accessing same bank? • Rotate allows arbitrary linear rotation and is simpler • Full random access requires a big switch • Can trade BW for size
Open Issues • Do we need an explicitly managed cache (for locking root of a tree for example)?
Open Issues • Do we want messaging (probably yes) • allows elegant distributed control • allows complex “fetch&ops” (remote procedures) • can build software coherency protocols and such • Do we need coherency in the scalar part
Open Issues • Is dynamic migration important? • Moving data from one node to another • not possible without pages or COMA
Open Issues • Exceptions? • No external exceptions • Arithmetic overflow/underflow, div by 0, etc. • Exception on cache miss? (Can we guarantee no cache misses?) • Disrupts stream sequencing and control flow • Interrupts and scalar/stream sync • Interrupts from Network? • From stream to scalar? From scalar to stream?
Experiments • Conditionals Experiment • Are predications and conditional stream sufficient? • Experiment with adding instruction sequencers for each cluster (quasi-MIMD) • Examine cost and performance