Download
1 / 1
10 likes | 137 Views
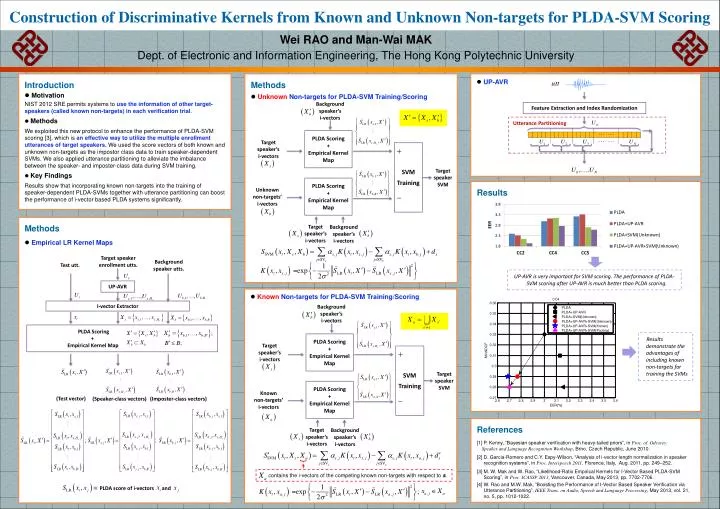
Construction of Discriminative Kernels from Known and Unknown Non-targets for PLDA-SVM Scoring. Feature Extraction and Index Randomization. Wei RAO and Man- Wai MAK Dept . of Electronic and Information Engineering, The Hong Kong Polytechnic University. Utterance Partitioning. Introduction

E N D
Construction of Discriminative Kernels from Known and Unknown Non-targets for PLDA-SVM Scoring FeatureExtraction and Index Randomization Wei RAO and Man-Wai MAK • Dept. of Electronic and Information Engineering,The Hong Kong Polytechnic University Utterance Partitioning • Introduction • Motivation • NIST 2012 SRE permits systems to use the information of other target-speakers (called known non-targets) in each verification trial. • Methods • We exploited this new protocol to enhance the performance of PLDA-SVM scoring [3], which is an effective way to utilize the multiple enrollment utterances of target speakers. We used the score vectors of both known and unknown non-targets as the impostor class data to train speaker-dependent SVMs. We also applied utterance partitioning to alleviate the imbalance between the speaker- and imposter-class data during SVM training. • Key Findings • Results show that incorporating known non-targets into the training of speaker-dependent PLDA-SVMs together with utterance partitioning can boost the performance of i-vector based PLDA systems significantly. • Methods • UnknownNon-targets for PLDA-SVM Training/Scoring • UP-AVR Background speaker’s i-vectors Background speaker’s i-vectors PLDA Scoring + Empirical Kernel Map PLDA Scoring + Empirical Kernel Map SVM Training SVM Training Target speaker’s i-vectors Target speaker’s i-vectors contains the i-vectors of the competing known non-targets with respect to s. PLDA Scoring + Empirical Kernel Map PLDA Scoring + Empirical Kernel Map Target speaker SVM Target speaker SVM Results Unknown non-targets’ i-vectors Known non-targets’ i-vectors • Methods • Empirical LR Kernel Maps Target speaker’s i-vectors Target speaker’s i-vectors Background speaker’s i-vectors Background speaker’s i-vectors Target speaker enrollment utts. Test utt. Background speaker utts. UP-AVR • KnownNon-targets for PLDA-SVM Training/Scoring I-vector Extractor PLDA Scoring + Empirical Kernel Map Results demonstrate the advantages of including known non-targets for training the SVMs (Test vector) (Speaker-class vectors) (Imposter-class vectors) References [1] P. Kenny, “Bayesian speaker verification with heavy-tailed priors”, in Proc. of Odyssey: Speaker and Language Recognition Workshop, Brno, Czech Republic, June 2010. [2] D. Garcia-Romero and C.Y. Espy-Wilson, “Analysis of i-vector length normalization in speaker recognition systems”, in Proc. Interspeech 2011, Florence, Italy, Aug. 2011, pp. 249–252. [3] M. W. Mak and W. Rao, “Likelihood-Ratio Empirical Kernels for I-Vector Based PLDA-SVM Scoring”, in Proc. ICASSP 2013, Vancouver, Canada, May 2013, pp. 7702-7706. [4] W. Rao and M.W. Mak,“Boosting the Performance of I-Vector Based Speaker Verification via Utterance Partitioning”, IEEE Trans. on Audio, Speech and Language Processing,May 2013, vol. 21, no. 5, pp. 1012-1022. PLDA score of i-vectors and EER UP-AVR is very important for SVM scoring. The performance of PLDA-SVM scoring after UP-AVR is much better than PLDA scoring.