Download

1 / 15
150 likes | 220 Views
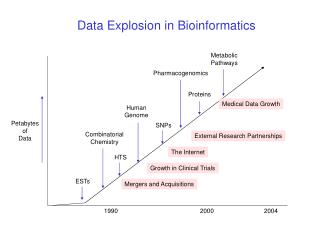
We live in an age of bioinformatics data glut. Attwood TK et al . (2009) Calling International Rescue: knowledge lost in literature and data landslide! Biochemical Journal 424:317–333. Cochrane GR, Galperin MY (2010) Nucleic Acids Research 38:D1-D4.

E N D
We live in an age of bioinformatics data glut . . . Attwood TK et al. (2009) Calling International Rescue: knowledge lost in literature and data landslide! Biochemical Journal 424:317–333. Cochrane GR, Galperin MY (2010) Nucleic Acids Research 38:D1-D4 • There are now over 1200 bioinformatics databases, between which data integration is difficult • Data integration for many researchers amounts to nothing more sophisticated than cutting and pasting into a Word document !!
Research data – Universals and Particulars • Gene sequences and protein structures represent ‘universal truths’ • The data need only be discovered once • The data are intinsically simple and form bounded data sets • Data are cheap per bit, and re-acquisition is becoming cheaper • Public databases exist for these data (GenBank, PDB, etc.) • The whole of bioinformatics is build on their free availability • Life science research data can also be ‘particulars’, for example individual assay results, disease reports, observations, electron micrographs, videos • These data are heterogeneous and form unbounded data sets – typical of ‘long tail’ science rather than ‘big science’ • Data collection is costly in human resources, and re-acquisition may be impossible, e.g. for observational data • Datasets thus often have a high intrinsic value per bit • The majority of such research datasets are never published, rotting on the abandoned hard drives of departed postdocs • In this open access age, that is little short of scandalous!
The problems of obtaining infectious disease data • I have a particular concern about infectious disease data, since I believe that timely availability of reliable datain this domain may have an important impact on global health. • Quote from Professor Angela McLean, after taking three months to amass appropriate disease incidence data for her 2007 J. Virology paper on HIV escape mutations: “When I was a graduate student, I spent long hours in libraries copying numbers from dusty journals. “Things have not improved much since ! ”
The benefits and risks of published data • The benefits of open data publication: • review and validation by others, • re-use in another contexts, and • integration with other data to create a new greater whole • Governments, funding agencies, publishers and researchers agree that the results of publicly funded research should be made publicly available • The problems of sharing data (From RIN – BL Report, November 2009 Patterns of Information Use and Exchange: Case Studies in the Life Sciences) • Ethical constraints and IPR issues • Concerns about misuse and data ownership • “As researchers, we see data as a critical part of our ‘intellectual capital’, generated by investment of time, effort and skill.” • Lack of personal attribution and credit for data publication • Difficulties in creating appropriate metadata • Appropriate repositories to archive and publish research datasets
Semantic publishing of structured research datasets Semantic publishing is the use of simple Semantic Web technologies: • to enhance the meaning of on-line published research articles • to provide access to the articles’ published data in actionableform • to facilitate the integration of semantically related data so that data, information and knowledge can more easily be found, extracted, combined and reused For research datasets to be maximally useful, they have to be: • saved in machine-processable form, in conformity with appropriate Web standards (e.g. XML, RDF, OWL) • published and made freely accessible on the Web • referenced by globally unique and resolvable identifiers (e.g. DOIs) • accompanied by useful metadata based upon minimal information standards and ontologies, including provenance information
Features of the original PLoS NTD article, relating to data Good • The article contained a rich variety of data types (geospatial, disease incidence, serological assay, and questionnaire) presented in formats amenable to semantic enrichments (maps, bar charts, tablesand graphs) Poor • While figures and table can be downloaded, they can only be so as images ! • The numerical data are not directly available inactionable form
http://dx.doi.org/10.1371/journal.pntd.0000228.x001 http://dx.doi.org/10.1371/journal.pcbi.1000361
Drosophila gene expression data exists in many databases FlyAtlas
Data from four sources combined in an OpenFlyData window Query for schuy over cached RDF data from FlyTED, BDGP, FlyAtlas and FlyBase http://openflydata.org/
In conclusion: data publishing and global warming Waiting for some international committee in Copenhagen to create the perfect solution to the data publication problem is not the way forward Just as we can each act locally to reduce our carbon footprint, so we can each do something personally to increase our data footprint Each of us, whether researcher, publisher or government agency, can take responsibility for the open publication of our own research data The important thing is to make a start !
Convergence between journals and databases PLoS Comp. Biol. 2005 1(3) e34 • In this paper, Philip Bourne, Editor-in Chief of PLoS Computational Biology and Co-Director of the Protein Data Bank, contends that the distinction between an on-line journal and an on-line database is diminishing • He calls for “seamless integration” between papers reporting results and the data used to compute those results
My critique of Philip Bourne’s ideas • We need to maintain a clear distinction between journal publications: • peer reviewed • immutable dated ‘versions of record’ – part of the history of science – • that provide the citable authorities for research datasets • and research databases: • that should present user with access to complete, impartial, up-to-date datasets, both for further exploration and automated data mining • with curators responsible for correction of errors after submission • Thus “seamless integration” is not desirable • Articles are rhetorical • Datasets are analytical • Researchers require the “seams” to be kept clearly visible, so they know which presuppositional spectacles to wear when reading • Nevertheless, both frictionless interoperabilityand reciprocal citation between papers and datasets are highly desirable