Download

1 / 54
550 likes | 665 Views
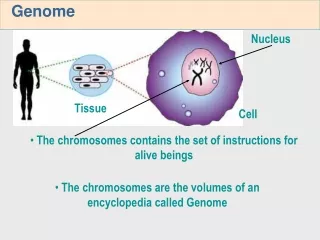
Genome Composition. Dan Graur. Genome Composition in Bacteria. Carsonella ruddii has a very low GC content. The selectionist explanation views GC content as an adaptation. G:C pairs are more stable than A:T pairs.

E N D
Genome Composition Dan Graur
The selectionist explanation views GC content as an adaptation. G:C pairs are more stable than A:T pairs. Preferential usage of amino acids encoded by GC-rich codons (e.g., ala and arg) and avoidance of amino acids encoded by GC-poor codons (e.g., ser and lys). T-T dimers are sensitive to UV radiation. No empirical evidence
The mutationist explanation Rate of substitution G/C T/A is m Rate of substitution T/A G/C is n Noboru Sueoka University of Colorado
Mycoplasma capricolum Escherichia coli Micrococcus luteus
Differences in the way the leading and lagging strands of DNA are replicated can result in strand-dependent mutation patterns. The expectation under no-strand-bias conditions is fA = fT and fC = fG
Deviations from equal mutation rates between the two strands are quantified by the skew.
The skew is a measure of inequality between the frequencies of nucleotides X and Y on a strand.
If there are no violations of the no-strand-bias conditions:
Skew values are calculated for sliding windows of predetermined lengths, and are plotted on a skew diagram.
chirochore chirochore Bacillus subtilis
Intergenomic variability GC content of bacterial genomes ranges from ~24% to ~74% GC content of vertebrate genomes ranges from ~40% to ~45%
Interspecific variation among vertebrate genomes is low. However, vertebrates seem to have a much more complex intragenomic compositional organization (internal structure) than prokaryotic genomes. TTGACCGATGACCCCGGTTCAGGCTTCACCACAGTGTGGAACGCGGTCGTCTCCGAACTTAACGGCGACCCTAAGGTTGACGACGGACCCAGCAGTGATGCTAATCTCAGCGCTCCGCTGACCCCTCAGCAAAGGGCTTGGCTCAATCTCGTCCAGCCATTGACCATCGTCGAGGGGTTTGCTCTGTTATCCGTGCCGAGCAGCTTTGTCCAAAACGAAATCGAGCGCCATCTGCGGGCCCCGATTACCGACGCTCTCAGCCGCCGACTCGGACATCAGATCCAACTCGGGGTCCGCATCGCTCCGCCGGCGACCGACGAAGCCGACGACACTACCGTGCCGCCTTCCGAGAGATTGATGACAGCGCTGCGGCACGGGGCGATAACCAGCACAGTTGGCCAAGTTACTTCACCGAGCGCCCGCACAATACCGATTCCGCTACCGCTGGCGTAACCAGCCTTAACCGTCGCTACACCTTTGATACGTTCGTTATCGGCGCCTCCAACCGGTTCGCGCACGCCGCCGCCTTGGCGATCGCAGAAGCACCCGCCCGCGCTTACAACCCCCTGTTCATCTGGGGCGAGTCCGGTCTCGGCAAGACACACCTGCTACACGCGGCAGGCAACTATGCCCAACGGTTGTTCCCGGGAATGCGGGTCAAATATGTCTCCACCGAGGAATTCACCAACGACTTCATTAACTCGCTCCGCGATGACCGCAAGGTCGCATTCAAACGCAGCTACCGCGACGTAGACGTGCTGTTGGTCGACGACATCCAATTCATTGAAGGCAAAGAGGGTATTCAAGAGGAGTTCTTCCACACCTTCAACACCTTGCACAATGCCAACAAGCAAATCGTCATCTCATCTGACCGCCCACCCAAGCAGCTCGCCACCCTCGAGGACCGGCTGAGAACCCGCTTTGAGTGGGGGCTGATCACTGACGTACAACCACCCGAGCTGGAGACCCGCATCGCCATCTTGCGCAAGAAAGCACAGATGGAACGGCTCGCGGTCCCCGACGATGTCCTCGAACTCATCGCCAGCAGTATCGAACGCAATATCCGTGAACTCGAGGCCGAGGAATTCACCAACGACTTCATTAACTCGCTCCGCGATGACCGCAAGGTCGCATTCAAACGCAGCTACCGCGACGTAGACGTGCTGTTGGTCGACGACATCCAATTCATTGAAGGCAAAG
How are nucleotides distributed along the genome? Uniform? Patchy? Clines? TTGACCGATGACCCCGGTTCAGGCTTCACCACAGTGTGGAACGCGGTCGTCTCCGAACTTAACGGCGACCCTAAGGTTGACGACGGACCCAGCAGTGATGCTAATCTCAGCGCTCCGCTGACCCCTCAGCAAAGGGCTTGGCTCAATCTCGTCCAGCCATTGACCATCGTCGAGGGGTTTGCTCTGTTATCCGTGCCGAGCAGCTTTGTCCAAAACGAAATCGAGCGCCATCTGCGGGCCCCGATTACCGACGCTCTCAGCCGCCGACTCGGACATCAGATCCAACTCGGGGTCCGCATCGCTCCGCCGGCGACCGACGAAGCCGACGACACTACCGTGCCGCCTTCCGAGAGATTGATGACAGCGCTGCGGCACGGGGCGATAACCAGCACAGTTGGCCAAGTTACTTCACCGAGCGCCCGCACAATACCGATTCCGCTACCGCTGGCGTAACCAGCCTTAACCGTCGCTACACCTTTGATACGTTCGTTATCGGCGCCTCCAACCGGTTCGCGCACGCCGCCGCCTTGGCGATCGCAGAAGCACCCGCCCGCGCTTACAACCCCCTGTTCATCTGGGGCGAGTCCGGTCTCGGCAAGACACACCTGCTACACGCGGCAGGCAACTATGCCCAACGGTTGTTCCCGGGAATGCGGGTCAAATATGTCTCCACCGAGGAATTCACCAACGACTTCATTAACTCGCTCCGCGATGACCGCAAGGTCGCATTCAAACGCAGCTACCGCGACGTAGACGTGCTGTTGGTCGACGACATCCAATTCATTGAAGGCAAAGAGGGTATTCAAGAGGAGTTCTTCCACACCTTCAACACCTTGCACAATGCCAACAAGCAAATCGTCATCTCATCTGACCGCCCACCCAAGCAGCTCGCCACCCTCGAGGACCGGCTGAGAACCCGCTTTGAGTGGGGGCTGATCACTGACGTACAACCACCCGAGCTGGAGACCCGCATCGCCATCTTGCGCAAGAAAGCACAGATGGAACGGCTCGCGGTCCCCGACGATGTCCTCGAACTCATCGCCAGCAGTATCGAACGCAATATCCGTGAACTCGAGGCCGAGGAATTCACCAACGACTTCATTAACTCGCTCCGCGATGACCGCAAGGTCGCATTCAAACGCAGCTACCGCGACGTAGACGTGCTGTTGGTCGACGACATCCAATTCATTGAAGGCAAAG
“When vertebrate genomic DNA is randomly sheared into fragments 30-100 kb in size and the fragments are separated by base composition, the fragments cluster into a small number of classes distinguished from each other by their GC content. Each class is characterized by bands of similar, but not identical, base compositions.” Equilibrium centrifugation in Cs2SO4 density gradient (Macaya et al. 1976; Thiery et al. 1976; Bernardi et al. 1985)
carp The Isochore Theory - Giorgio Bernardi
Isochores do not merit the prefix “iso.” Lander et al. (2001)
Post genomic era (2001) Objections against the isochore theory: “We can rule out a strict notion of isochores as compositionally homogeneous.” Lander et al. (2001) “There are no isochores in chromosomes 21 and 22.” Häring and Kyper (2001) Defense of the isochore theory: “The conclusion of the authors that ‘isochores’ are not ‘strict isochores’ is correct, however isochore are fairly homogeneous regions.” Bernardi (2001)
strict isochores approximate isochores
In search of isochores… Questions: • Do isochores exist? • Is the isochore theory a useful (or practical) concept?
Segmentation Models • Assumption: Sequences can be partitioned into a number of segments each with a characteristic GC content. • Each segment has a certain degree of internal homogeneity (or similarity).
In search of isochores… • Methodology: • Define rigorously 6 attributes of isochores and of the isochore theory as applied to humans • Test attributes against the human genome data
Attributes of isochores A1. Distinguishability: An isochore is a DNA segment that has a characteristic GC content that differs significantly from the GC content of adjacent isochores. A2. Homogeneity: An isochore is more homogeneous in its composition than the chromosome on which it resides. A3. Minimum length: The length of an isochore exceeds a certain cutoff value. In the literature, the most commonly mentioned value is 300 Kb.
Attributes of the isochore theory in humans A4. Genome coverage: The overwhelming majority of the human genome consists of segments abiding by A1-A3. Non-isochoric DNA takes up only a small fraction of the genome.
Attributes of the isochore theory in humans A5. Isochore families: The human genome comprises of five isochore families, each described by a particular Gaussian distribution of GC content.
Practicality of the isochore theory A6. Isochore assignment into families: It is possible to classify each isochore into its isochore family based solely on its compositional properties.
Segment length distribution The fitted regression line (solid line) indicates that the tail of the distribution exhibits power-law decay with an exponent of –2.38. P L–2.38
Isochore families Most parsimonious Gaussian fit to putative isochores 2 1 3 4
Assignment into families Classification errors reach values of 70%. Only a minute fraction of segments can be classified with an expected error under 5%.
Summary (A1) Distinguishability (A2) Homogeneity 50% (A3) Minimum length X (A1) Genome coverage 41% (A2) Isochore families 4 families (A3) Isochore assignment into families X
Conclusion: • The isochore theory may have reached the limits of its usefulness as a description of genomic compositional structures.
As of December 2004 17 genetic codes 11 mitochondrial 5 nuclear 1 nuclear + mitochondrial
Evolutionary Dead Ends Frozen accidents
The codon-capture hypothesis Thomas Jukes