Download

1 / 22
220 likes | 399 Views
A Study of the Scalability of On-Chip Routing for Just-in-Time FPGA Compilation. Roman Lysecky a , Frank Vahid a* , Sheldon X.-D. Tan b a Department of Computer Science and Engineering b Department of Electrical Engineering University of California, Riverside

E N D
A Study of the Scalability of On-Chip Routing for Just-in-Time FPGA Compilation Roman Lyseckya, Frank Vahida*, Sheldon X.-D. Tanb aDepartment of Computer Science and Engineering bDepartment of Electrical Engineering University of California, Riverside *Also with the Center for Embedded Computer Systems at UC Irvine This work was supported in part by the National Science Foundation, the Semiconductor Research Corporation, and Xilinx
SW ______ ______ ______ SW ______ ______ ______ x86 Binary Binary Standard Compiler Profiling IntroductionStandard binary - Separating Function and Architecture • Software binaries of the past • Binary reflected specific language of underlying architecture – limited portability • Current “standard binary” • Concept: separate function from detailed architecture • Develop new architectures for existing applications • Trend towards dynamic translation and optimization
SW ______ ______ ______ HW ______ ______ ______ SW ______ ______ ______ SW ______ ______ ______ SW ______ ______ ______ SW ______ ______ ______ SW Binary Binary Binary Binary Processor1 Processor1 Standard Compiler Profiling Compiler/ Synthesis Profiling Processor3 Processor3 Proc. Proc. FPGA FPGA Proc. FPGA Proc. Proc. Processor Processor2 IntroductionBut Today’s Binaries are More than just Software
VHDL/Verilog Std. HW Binary Binary Binary Standard CAD Tools Profiling JIT FPGA Comp. JIT FPGA Comp. + + * * + + MEM FPGA FPGA IntroductionJust-in-Time FPGA Compilation? • JIT FPGA compilation • Idea: standard binary for FPGA • Similar benefits as standard binary for microprocessor • Portability, transparency, standard tools • Embedded JIT compilation tools optimized for each FPGA
SW ______ ______ SW Binary Binary ARM7 ARM9 ARM10 ARM11 Processor Processor Processor Processor Feature Upgrade Feature Upgrade IntroductionOne Use of JIT FPGA Compilation CableTV Company
HW4 ______ ______ HW2 ______ ______ HW1 ______ ______ SW ______ ______ HW3 ______ ______ HW ______ ______ HW Netlist3 HW Netlist4 SW Binary HW Netlist1 SW Binary SW Binary SW Binary HW Netlist2 Binary Binary Binary Binary Binary Binary Binary Binary FPGA 1 FPGA 2 FPGA 3 FPGA 4 Processor Processor Processor Processor ARM11 ARM10 ARM9 ARM7 Processor Processor Processor Processor Feature Upgrade Feature Upgrade IntroductionOne Use of JIT FPGA Compilation CableTV Company
SW ______ ______ HW ______ ______ HW Binary SW Binary Binary Binary FPGA 4 FPGA 3 FPGA 2 FPGA 1 Processor Processor Processor Processor JIT FPGA Comp. JIT FPGA Comp. JIT FPGA Comp. JIT FPGA Comp. ARM11 ARM10 ARM9 ARM7 Processor Processor Processor Processor Feature Upgrade Feature Upgrade IntroductionOne Use of JIT FPGA Compilation CableTV Company
2 Profile application to determine critical regions 1 Initially execute application in software only 3 Profiler Partition critical regions to hardware µP I$ 5 D$ Partitioned application executes faster with lower energy consumption FPGA Dynamic Part. Module (DPM) 4 Program configurable logic & update software binary IntroductionAnother Use - Warp Processors (Dynamic HW/SW Partitioning) Profiler µP I$ D$ FPGA Dynamic Part. Module (DPM) Lysecky/Vahid, DATE’04; Stitt/Lysecky/Vahid, DAC’03; Stitt/Vahid, ICCAD’02
Binary HW Bitstream Updated Binary Std. HW Binary Binary Binary Binary Binary RT Synthesis Logic Synthesis JIT FPGA Compilation Placement Tech. Mapping/Packing Routing Binary Updater Decompilation Partitioning Profiler µP I$ D$ FPGA DPM (CAD) JIT FPGA Compilation IntroductionAnother Use - Warp Processors (Dynamic HW/SW Partitioning) Lysecky/Vahid, DATE’04; Stitt/Lysecky/Vahid, DAC’03; Stitt/Vahid, ICCAD’02
Tech. Map Log. Syn. Route Place 1 min 1-2 mins 1 min 2-30 mins 10 MB 10 MB 50 MB 60 MB IntroductionExisting FPGAs Not Suitable for JIT FPGA Compilation • Existing FPGAs require extremely complex CAD tools • Designed to handle large arbitrary circuits, ASIC prototyping, etc. • Require long execution times and very large memory usage • Not suitable for dynamic on-chip execution
Logic Synthesis Placement Tech. Mapping/Packing Routing JIT FPGA Comp. + + 1s <1s <1s 10s 3.6 MB 1 MB 1 MB FPGA .5 MB JIT FPGA CompilationCAD-Oriented FPGA • Solution: Develop a custom CAD-oriented FPGA • Careful simultaneous design of FPGA and CAD • FPGA features evaluated for impact on CAD • Enables development of fast, lean JIT FPGA compilation tools Lysecky/Vahid, DATE’04
SM SM SM CLB CLB SM SM SM SM SM SM CLB CLB SM SM SM Simple Configurable Logic FabricCAD-Oriented FPGA • Simple Configurable Logic Fabric (CLF) • Hundreds of existing commercial and research FPGA fabrics • Most designed to balance circuit density and speed • Analyzed FPGA’s features to determine their impact of CAD • Designed our CLF in conjunction with JIT FPGA compilation tools • Array of configurable logic blocks (CLBs) surrounded by switch matrices (SMs) • CLB is directly connected to a SM • Along with SM design, allows for design of lean JIT routing Lysecky/Vahid, DATE’04
e a b c d f LUT LUT Adj. CLB Adj. CLB o1 o2 o3 o4 Simple Configurable Logic Fabric Combinational Logic Block • Combinational Logic Block • Incorporate two 3-input 2-output LUTs • Equivalent to four 3-input LUTs with fixed internal routing • Allows for good quality circuit while reducing JIT technology mapping complexity • Provide routing resources between adjacent CLBs to support carry chains • Reduces number of nets we need to route Lysecky/Vahid, DATE’04
0 1 2 3 0L 1L 2L 3L 3L 3L 2L 2L 1L 1L 0L 0L 3 3 2 2 1 1 0 0 0 1 2 3 3L 0L 1L 2L Simple Configurable Logic Fabric Switch Matrix • Switch Matrix • All nets are routed using only a single pair of channels throughout the configurable logic fabric • Each short channel is associated with single long channel • Designed for fast, lean JIT FPGA routing Lysecky/Vahid, DATE’04
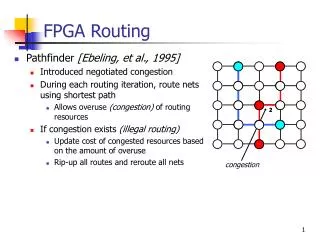
1 1 1 1 1 1 2 1 1 1 congestion JIT FPGA Compilation Routing • FPGA Routing • Find a path within FPGA to connect source and sinks of each net within our hardware circuit • Pathfinder [Ebeling, et al., 1995] • Introduced negotiated congestion • During each routing iteration, route nets using shortest path • Allows overuse (congestion) of resources • If congestion exists (illegal routing) • Update cost of congested resources • Rip-up all routes and reroute all nets • VPR [Betz, et al., 1997] • Provides various improvements over Pathfinder • Routability-driven: Use fewest tracks possible • Timing-driven: Optimize circuit speed • Many techniques are used in commercial FPGA CAD tools 2
SM SM SM Done! Route CLB CLB SM SM SM CLB CLB 0/4 SM SM SM 0/4 0/4 0/4 0/4 0/4 SM SM SM 0/4 0/4 0/4 0/4 illegal? Routing Resource Graph SM SM SM 0/4 0/4 Resource Graph yes no Rip-up 0/4 0/4 0/4 0/4 SM SM SM 0/4 0/4 JIT FPGA Compilation ROCR – Riverside On-chip Router • ROCR - Riverside On-Chip Router • Resource Graph • Nodes correspond to SMs • Edges correspond to channels between SMs • Capacity of edge equal to the number of wires within the channel • Requires much less memory as resource graph is smaller Lysecky/Vahid/Tan, DAC’04; Lysecky/Vahid, DATE’04
SM SM SM CLB CLB SM SM SM SM SM SM CLB CLB SM SM SM Scalability of On-chip RoutingExperimental Setup • Experimental Setup • 100x100 configurable logic fabric array • Routing channel width of 34 • Large enough to support all HW circuits • 123 MCNC benchmark circuits • Circuit complexity ranges from few LUTs to tens of thousands of LUTs • Performed technology mapping, packing, and placement using FlowMap, T-VPack, and VPR’s bounding box placement • Routed each HW benchmark circuit using: • VPR’s timing-driven router • VPR’s fast timing-driven router (-fast option) • Riverside On-Chip Router (ROCR)
VPR requires over 100MB of on average ROCR requires at most 8.3 MB VPR requires 18X more than ROCR on average Scalability of On-chip Routing Memory Usage
ROCR is over 40X times faster than VPR for small HW circuits ROCR is 2X-3X times faster than VPR for large HW circuits Scalability of On-chip Routing Algorithm Performance
19% longer critical path than VPR 2.6% shorter than VPR (Fast) Scalability of On-chip Routing Critical Path 30%/27% longer critical path than VPR/VPR (Fast)
ROCR requires 2%/8% fewer wire segments than VPR/VPR (Fast) for larger HW circuits Scalability of On-chip Routing Wire Segments
Conclusions and Future Work • Conclusions • Demonstrated ROCR scales well as circuit size increases • On average 2X faster than VPR’s fast timing-driven router • Requiring 18X less memory than VPR • Produces good circuit quality • Critical path 27% longer than VPR (Fast) on average • 2.6% shorter critical path for largest HW circuit • Requires on average 5% fewer wire segments • Future Work • Currently project: Major microprocessor vendor is fabricating our custom FPGA • Improvements to Riverside On-Chip Router (ROCR) • Improve ROCR’s performance for large HW circuits • Incorporating timing information to achieve • Analyze the scalability of ROCR as circuit size approaches FPGA capacity • JIT FPGA Compilation • Development of standard HW binary • Support more complex FPGA architectures JIT FPGA compilation