Download

1 / 33
340 likes | 527 Views
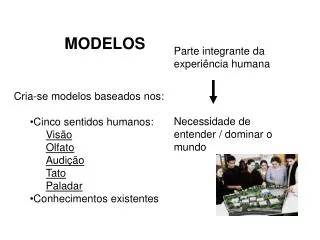
Modelos Computacionales. Memorias asociativas Dinámicas. Contenidos. Introducción El asociador lineal El asociador no lineal simple La Red BSB. Introducción. Memoria Asociativa. Patrón clave. Patrón de referencia.

E N D
Modelos Computacionales Memorias asociativas Dinámicas
Contenidos • Introducción • El asociador lineal • El asociador no lineal simple • La Red BSB
Introducción Memoria Asociativa Patrón clave Patrón de referencia • Memoria asociativa: dispositivo para almacenar información que permite recuperarla basándose sólo en un conocimiento parcial de su contenido y no en el lugar de su almacenamiento. La recuperación de la información se consigue según el grado de similitud entre el patrón de entrada(clave) y los patrones memorizados(referencias).
Introducción • Usaremos la desviación cuadrática como medida de semejanza: • xk = (xk1, xk2, xk3,..., xkN) con k = 1,2, ... ,pson los patrones de referencia • x* = (x*1, x*2, . . . , x*N) es el patrón de prueba • Si las componentes de los vectores son binarias ({0,1}), Dk coincide con la distancia de Hamming. • Si los vectores son bipolares ({-1,1}) la distancia de Hamming se calcula con Dk/4
Introducción • Tipos de memorias asociativas • Heteroasociativa: para un conjunto de pares de entradas y salidas { (x1,y1),(x2,y2), ... ,(xp,yp) }, xkN, ykM establece una correspondencia de N en M de tal manera que (xi) = yi, para i=1,2,..,p y además si x está más próximo a xique a cualquier otro xj entonces (x) = yi . • Autoasociativa establece la misma correspondencia que la memoria heteroasociativa pero siendo los patrones de entrada y de salida los mismos, es decir. (xi) = xi.
El asociador lineal • Queremos memorizar p pares de patrones (entradas y salidas), • { (x1,y1),(x2,y2), ... ,(xp,yp) }, xkN, ykM. • Los vectores de entrada (claves) son ortonormales, es decir, (xk)Txk = 1 y (xk)Txi = 0 , ki. • Un asociador lineal es una aplicación lineal de la forma • yi =(xi) = W · xi
El asociador lineal • Arquitectura • N unidades de entrada y M unidades de proceso independientes • Cada entrada se conecta a todas las unidades de proceso. • Ley de Aprendizaje: • Dinámica de la computación: • Los resultados se obtienen instantáneamente, sin evolución en los estados del sistema • La función de activación es la función identidad. yi =(xi) = W · xi
El asociador lineal • ¿Se devuelven los patrones de referencia correctos? • ¿Qué ocurre si perturbamos ligeramente la entrada? • El asociador lineal interpola la salida
El asociador lineal • Ventaja: • Simplicidad • Inconveniente: • La condición de ortogonalidad de los patrones clave • Ejercicio: Construir un asociador lineal que memorice los patrones {(1000), (00)}, {(0110), (01)}, {(111), (11)} Calcular la salida ante las siguientes entradas: (1100)
Asociador no lineal simple • Deseamos memorizar p patrones • { s1, s2, …,sp, }, skN, k=1,2,…,p • mediante una memoria asociativa dinámica no lineal. • La salida del sistema se obtendrá tras un proceso de computación. Es decir, la red comienza con la configuración determinada por la entrada y los estados de las neuronas van cambiando, hasta que llegamos a una situación estable en la que podemos leer el resultado de la computación. • La red habrá memorizado un patrón si se estabiliza en él.
Asociador no lineal simple • Arquitectura • N unidades de proceso. • Todas las neuronas conectadas con todas. • Ley de aprendizaje: • Regla de Hebb: • Aprendizaje iterativo:
Asociador no lineal simple • Dinámica de la computación • Si(k) es el estado de la neurona i en el instante k de ejecución. Será 1 si la neurona está activa y –1 si no lo está. La actualización se realiza en tiempo discreto • La entrada s=(s1, s2, ..., sN)T, sirve para inicializar el estado de las neuronas, es decir, Si(0) = si, i{1,2,...,N} • Cuando Si(k) = Si(k+1) = sik1, i{1,2,...,N}, diremos que la red se ha estabilizado.
Asociador no lineal simple • Para entender el funcionamiento de nuestro modelo neuronal consideremos el caso particular en el que queremos memorizar sólo un patrón, s=(s1, s2, ..., sN)T. • La regla de aprendizaje se particulariza a: • Con ese entrenamiento, ¿se memoriza el patrón?
Asociador no lineal simple Observación: wii = p/n pues sisi=1 Sin embargo, se suele tomar wii = 0 ya que no supone diferencia apreciable en la estabilidad de la red, ij
Asociador no lineal simple • ¿Qué ocurre ante entradas no memorizadas que difieren en n componentes del patrón memorizado?
Asociador no lineal simple • Junto al patrón que le enseñamos, la red ha aprendido por cuenta propia el patrón opuesto. • Siguiendo el criterio de semajanza planteado el patrón referencia que se recupera será uno u otro.
Asociador no lineal simple • ¿Funciona igual de bien cuando queremos memorizar varios patrones? Estado inicial: ¿Cuál sería el siguiente estado Si(1)=sgn[hi(0)]?
Asociador no lineal simple • Si los patrones se escogieron ortogonales, el estado de la neurona se mantiene. Por tanto, la red se estabiliza y nos devuelve el patrón correcto. • Otra posibilidad es utilizar un número de neuronas (N) muy elevado en comparación con el número de patrones que queremos memorizar (p). Esto no nos asegura resultados esentos de error, pero sí “aceptables”. • Capacidad de almacenamiento de la red: cantidad de información que se puede almacenar de tal forma que se recupere sin error o con error despreciable.
Capacidad de un asociador no lineal • Indicadores de la capacidad de una red: • Considerando patrones almacenados (p) y total de neuronas (N) • En base a los patrones (p) y al número de conexiones (NW) • Teorema: La capacidad máxima de una red de Hopfield está acotada por
Asociador no lineal simple • ¿Qué ocurre si almacenamos p patrones y la entrada difiere en n componentes de alguno de los patrones memorizados? • Cuanto menores sean n y p con respecto a N, más fiable será la red en su función de memoria asociativa.
Asociador no lineal simple (-1 1 1) (-1 -1 1) (1 -1 1) (1 1 1) (-1 -1 –1) (-1 1 –1) (1 -1 –1) (1 1 –1) • Ejemplo: Diseño de un asociador lineal que memorice los patrones (1 -1 1) y (-1 1 -1). Probarla con la entrada (1 1 1).
Asociador no lineal simple • Nuestra red tendrá 3 unidades de proceso. Cada una de ellas se encargará de procesar una componente del vector de entrada. • La dinámica de la computación es la definida. • Empleando la regla de Hebb, calculamos la interacción entre las neuronas wii = 1/3(1+1) = 2/3
Asociador no lineal simple 2/3 2/3 -2/3 1 2 2/3 -2/3 3 2/3 Asociador no lineal
Asociador no lineal simple (-1 -1 1) (-1 1 1) (1 -1 1) (1 1 1) (-1 -1 –1) (-1 1 –1) (1 -1 –1) (1 1 –1) • Estado inicial: (1 1 1) • Computamos hasta que se estabiliza la red. • Estado final: (1 –1 1)
La red BSB • La red BSB(Brain-State-in-a-Box) se suele emplear como memoria autoasociativa de conjuntos de patrones { s1, s2, …,sp, }, skN, k=1,2,…,p • Arquitectura • N unidades de proceso. • Cada unidad está conectada a todas las demás. • Ley de aprendizaje • Regla de Hebb • Se suele fijar el peso sináptico wii=1, i=1,2,...,N
La red BSB • Dinámica de la computación: • Actualización en unidades de tiempo discretas. • La función de transferencia es la función rampa
La red BSB • La ley de aprendizaje puede especificarse de forma iterativa: • es la tasa de aprendizaje. Determina la facilidad para aprender. • El entrenamiento se mantiene hasta que se produzcan salidas con un error aceptable • Con esos pesos la red se estabiliza en los patrones memorizados.
La Memoria Asociativa Bidireccional (BAM) Teorema 1. Si seguimosuna actualización paralela la función de energía computacional decrece, o no cambia, en cada actualización, y la red alcanza un estado estable (estado de equilibrio) después de un número finito de actualizaciones.
La Memoria Asociativa Bidireccional (BAM) Determinación de los pesos sinápticos: Regla de Hebb Ejemplo: Memorizar los patrones y códigos siguientes: (1 -1 -1) (-1 -1 1) (1 1 1 -1 1 -1 -1 1 -1) (1 -1 -1 1 -1 -1 1 1 1)
La Memoria Asociativa Bidireccional (BAM) Determinación de los pesos sinápticos: Regla de Hebb Actualización: (-1 -1 1) Patrón a reconocer:
La Memoria Asociativa Bidireccional (BAM) Actualización: Patrón a reconocer: (-1 -1 1) Actualización: (1 -1 -1 1 -1 -1 1 1 1)
La Memoria Asociativa Bidireccional (BAM) Actualización: (1 -1 -1 1 -1 -1 1 1 1) (-1 -1 1) Resultado final: (-1 -1 1) Patrón a reconocer: