Download

1 / 37
370 likes | 518 Views
The Significance of Precision and Recall in Automatic Metrics for MT Evaluation. Alon Lavie , Kenji Sagae, Shyamsundar Jayaraman Language Technologies Institute Carnegie Mellon University. Outline. Similarity-based metrics for MT evaluation

E N D
The Significance of Precision and Recall in Automatic Metrics for MT Evaluation Alon Lavie, Kenji Sagae, Shyamsundar Jayaraman Language Technologies Institute Carnegie Mellon University
Outline • Similarity-based metrics for MT evaluation • Weaknesses in Precision-based MT metrics (BLEU, NIST) • Simple unigram-based MT evaluation metrics • METEOR • Evaluation Methodology • Experimental Evaluation • Recent Related Work • Future Directions AMTA 2004
Similarity-based MT Evaluation Metrics • Assess the “quality” of an MT system by comparing its output with human produced “reference” translations • Premise: the more similar (in meaning) the translation is to the reference, the better • Goal: an algorithm that is capable of accurately approximating the similarity • Wide Range of metrics, mostly focusing on word-level correspondences: • Edit-distance metrics: Levenshtein, WER, PIWER, … • Ngram-based metrics: Precision, Recall, F1-measure, BLUE, NIST, GTM… • Main Issue: perfect word matching is very crude estimate for sentence-level similarity in meaning AMTA 2004
Desirable Automatic Metric • High-levels of correlation with quantified human notions of translation quality • Sensitive to small differences in MT quality between systems and versions of systems • Consistent – same MT system on similar texts should produce similar scores • Reliable – MT systems that score similarly will perform similarly • General – applicable to a wide range of domains and scenarios • Fast and lightweight – easy to run AMTA 2004
Weaknesses in BLEU (and NIST) • BLUE matches word ngrams of MT-translation with multiple reference translations simultaneously Precision-based metric • Is this better than matching with each reference translation separately and selecting the best match? • BLEU Compensates for Recall by factoring in a “Brevity Penalty” (BP) • Is the BP adequate in compensating for lack of Recall? • BLEU’s ngram matching requires exact word matches • Can stemming and synonyms improve the similarity measure and improve correlation with human scores? • All matched words weigh equally in BLEU • Can a scheme for weighing word contributions improve correlation with human scores? • BLEU’s Higher order ngrams account for fluency and grammaticality, ngrams are geometrically averaged • Geometric ngram averaging is volatile to “zero” scores. Can we account for fluency/grammaticality via other means? AMTA 2004
Roadmap to a Desirable Metric • Establishing a metric with much improved correlations with human judgment score at the sentence-level will go a long way towards our overall goals • Our Approach: • Explicitly align the words in the MT translation with their corresponding matches in the reference translation, allowing for: • Exact matches, stemmed word matches, synonym and semantically-related word matches • Combine unigram Precision and Recall to account for the similarity in “content” (translation adequacy) • Weigh the contribution of matched words based on a measure related to their importance • Estimate translation fluency/grammaticality based on explicit measure related to word-order, fragmentation and/or average length of matched ngrams AMTA 2004
METEOR vs. BLEUSentence-level Scores(CMU System, 2003 Data) R=0.2466 R=0.4129 BLEU METEOR AMTA 2004
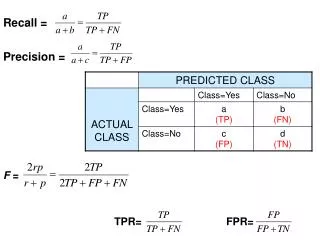
Unigram-based Metrics • Unigram Precision: fraction of words in the MT that appear in the reference • Unigram Recall: fraction of the words in the reference translation that appear in the MT • F1= P*R/0.5*(P+R) • Fmean = P*R/(0.9*P+0.1*R) • With and without word stemming • Match with each reference separately and select the best match for each sentence AMTA 2004
The METEOR Metric • Matcher explicitly aligns matched words between MT and reference • Multiple stages: exact matches, stemmed matches, (synonym matches) • Matcher returns fragment count – used to calculate average fragmentation (frag) • METEOR score calculated as a discounted Fmean score • Discounting factor: DF = 0.5 * (frag**3) • Final score: Fmean * (1- DF) AMTA 2004
Evaluation Methodology • Correlation of metric scores with human scores at the system level • Human scores are adequacy+fluency [2-10] • Pearson correlation coefficients • Confidence ranges for the correlation coefficients • Correlation of score differentials between all pairs of systems [Coughlin 2003] • Assumes a linear relationship between the score differentials AMTA 2004
Evaluation Setup • Data: DARPA/TIDES 2002 and 2003 Chinese-to-English MT evaluation data • 2002 data: • ~900 sentences, 4 reference translations • 7 systems • 2003 data: • ~900 sentences, 4 reference translations • 6 systems • Metrics Compared: BLEU, NIST, P, R, F1, Fmean, GTM, B&H, METEOR AMTA 2004
Recent Related Work • [Lin & Hovy 2003] • [Turian Shen & Melamed 2003] • [Babych & Hartley 2004] • [Soricut & Brill 2004] AMTA 2004
Current and Future Directions AMTA 2004
METEOR:Metric for Evaluation of Translation with Explicit OrderingAn Improved Automatic Metric for MT Evaluation Faculty: Alon Lavie, Jaime Carbonell Student: Rachel Reynolds
Automatic Metrics for MT Evaluation • Human evaluations are costly and time consuming • Automatic evaluation is cheap and fast • Can support both objective comparison between systems and incremental development of systems based on performance effects • Essential to have a “good” metric: • Metric scores that correlate as closely as possible to human judgments AMTA 2004
The BLEU Metric • Proposed by IBM [Papineni et al, 2002] • First serious metric proposed, used extensively over last couple of years (DARPA/TIDES, various other groups) • Main concepts in BLEU: • Compare system output with a set of reference translations • Calculate score based on n-grams matches (length 1-4) between the translation and the reference translations • Aggregate Precision = # n-gram matches / total # of n-grams in system output (for each length n-gram) • Weighed geometric averaging of the n-gram orders • Brevity Penalty if system output is too short • Compensation for not taking recall into account • Recall = # n-gram matches / total # n-grams in reference translations (for each length n-gram) AMTA 2004
BLEU: Main Problems • Recall is not explicitly accounted for • Brevety Penalty is not effective compensation for lack of recall • Notion of Grammaticality (particularly word-order) indirectly measured via higher order n-grams (2,3,4) • No explicit matching between words in translation and reference, so order cannot be explicitly compared • Matching is only on exact words (no morphological variants, synomyms, etc.) Result: metric is crude, not sensitive to anything excect for major differences between systems Correlation with human judgements is not very high AMTA 2004
METEOR Metric: Characteristics • Explicitly word matching of translation with one or more reference translations • Calculate unigram precision/recall/F1 of each match • Calculate an explicit penalty based on how out-of-order are the matched words in the translation • Sentence score [0,1] is the score of the best match with the best reference translation • Aggregate scores for entire set similar to BLEU AMTA 2004
METEOR: Algorithm • Align translation with references • Find the reference translation with the most matches • Calculate precision, recall and F1 based using the best reference translation • Precision = # matches / length of translation • Recall = # matches / length of reference • F1 = 2 * P * R / (P + R) AMTA 2004
METEOR: Algorithm • Calculate reordering penalty factor • sort matched words in hypothesis to match the order of words in the reference • Sort factor = # flips required for sort / maximum number of flips • Max = k * (k-1) / 2, where k is the number of matched words • Final Score = F1 * (1- sort factor) • For aggregate score, keep track of total hyp length, ref length, # matches, and # flips and calculate aggregate P/R/F1 and Final-score AMTA 2004
Example • Sentences: • Hyp: Iraq to army work came to ones weapons charge for 2 weeks • Ref: the weapons in hands of Iraq that will be used by the army are to be handed over within 2 weeks • Alignment: • Hyp matches: Iraq army to weapons 2 weeks • Ref matches: weapons Iraq army to 2 weeks • Flips: weapons must be shifted 3 places • Sort factor: 3/(6*5/2) = 3/15 = 0.2 • Precision = 6/12 = 0.5 • Recall = 6/21 = 0.2857 • F1 = 0.2857/0.7857 = 0.3636 • Score = (1 – 0.2) * 0.3636 = 0.2909 AMTA 2004
Extensions to the Basic Metric • Exponential Penalty • Linear sorting penalty appeared to be very harsh – want at least a minimal credit for getting all the words right • Switch to an exponential factor penalty, currently 1/2penalty • Completely correct order: penalty-factor = 1 • Completely opposite order: penalty-factor = 0.5 • Greater distinction between systems with small penalties • We are still working on fine tuning the penalty to find the base with the best properties AMTA 2004
Extensions to the Basic Metric • Grouping of Phrases • Consecutive words in the right order are grouped together during sorting • The groups are treated as units that are moved together and can be jumped over with one flip • Sentences that are mostly in the correct order are not penalized severely for one word that is far out of place – no longer penalized for jumping over each word in the group • Overall penalty is much less harsh than before AMTA 2004
Methods for Evaluating and Comparing Metrics • Several different experimental designs for assessing the correlation between the metric scores and human judgments • System score correlations: plot metric scores vs. human scores for collection of systems tested on same data and obtain correlation coefficient • Pairwise comparison of systems: for each pair of systems plot diff. in metric score vs. diff. in human score, and calculate correlation coefficient • Sentence score correlations: plot metric scores vs. human score at the sentence-level for a particular system, and obtain correlation coefficient • Score human (reference) translations against other refs and compare the distributions of metric scores: high scores with low variance indicate a better metric AMTA 2004
Comparative Evaluation of METEOR vs. BLEU • Two data sets: 2002 and 2003 Chinese-to-English TIDES MT system evaluations • Human Evaluators • 11 Evaluators • Documents randomly distributed among evaluators • Each document graded by 2 evaluators • Human Scores • Each sentence given a fluency and adequacy score • Both scores range from 1 to 5 (5 = highest) • Quality of human evaluation is somewhat questionable (relatively low intergrader agreement) AMTA 2004
METEOR vs. BLEU: 2002 Data, System Scores R^2=0.1827 R^2=0.2081 METEOR BLEU AMTA 2004
METEOR vs. BLEU: 2002 Data, Select Systems R^2=0.7793 R^2=0.9998 METEOR BLEU AMTA 2004
METEOR vs. BLEU: 2003 Data, System Scores R^2=0.6717 R^2=.8039 BLEU METEOR AMTA 2004
METEOR: F1 vs. Full Metric 2002 Data, System Scores R^2=0.2051 R^2=0.1853 F1 Only Full METEOR AMTA 2004
METEOR vs. BLEU: 2003 Data, Pairwise System Scores R^2=0.6818 R^2=0.8320 METEOR BLEU AMTA 2004
METEOR vs. BLEUHistogram of Scores of Reference Translations2003 Data Mean=0.6504 STD=0.1310 Mean=0.3727 STD=0.2138 BLEU METEOR AMTA 2004
Summary of Results • METEOR has significantly better correlation with human judgments: • System Level, 2002 Data, select systems: +28% relative improvement (METEOR has perfect correlation) • System Level, 2003 Data: +20% relative improvement • Sentence Level, 2003 Data: 10 times better correlation • Scores of Reference Translations: dramatically higher and with far less variance AMTA 2004
Work in Progress • Tuning the exponential penalty for the right degree of differentiation and maximum penalty • Using a lattice to create new “synthetic” reference translations so that the best reference can be a combination of references • Weighing matches based on part of speech so that content words can influence the score more than function words • Matching with partial credit for words similar in meaning to a word in the reference translation: morphological variants, synonyms AMTA 2004