Download

1 / 44
440 likes | 1.14k Views
Learn about the characteristics of the Normal Probability Curve, including symmetry, asymptotic behavior, mean, median, mode, points of inflection, and distribution of standard deviations. Discover how skewness affects data analysis. Contact Dr. Lalit M. Tiwari at +91-9012761130 for more insights.

E N D
Normal Distribution Dr. Lalit M. Tiwari +91-9012761130
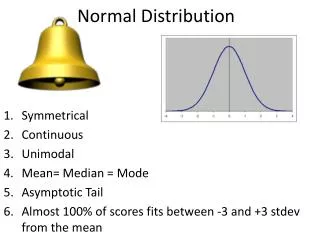
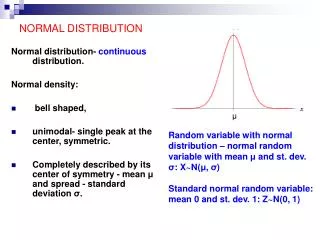
This bell shaped curve is called as the ‘Normal Probability Curve’. Thus the “graph of the probability density function of the normal distribution is a continuous bell shaped curve, symmetrical about the mean” is called normal probability curve. Dr. Lalit M. Tiwari
Characteristics of Normal Probability Curve: • 1. The curve is bilaterally symmetrical. • The curve is symmetrical to its ordinate of the central point of the curve. It means the size, shape and slope of the curve on one side of the curve is identical to the other side of the curve. If the curve is bisected then its right hand side completely matches to the left hand side. Dr. Lalit M. Tiwari +91-9012761130
The curve is asymptotic: • The Normal Probability Curve approaches the horizontal axis and extends from-∞ to + ∞. Means the extreme ends of the curve tends to touch the base line but never touch it. Dr. Lalit M. Tiwari +91-9012761130
The Mean, Median and Mode: • The mean, Median and mode fall at the middle point and they are numerically equal. Dr. Lalit M. Tiwari +91-9012761130
The Points of inflection occur at ± 1 Standard deviation unit: • The points of influx in a NPC occur at ± 1σ to unit above and below the mean. Thus at this point the curve changes from convex to concave in relation to the horizontal axis. Dr. Lalit M. Tiwari +91-9012761130
The total area of NPC is divided in to ± standard deviations: • The total of NPC is divided into six standard deviation units. From the center it is divided in to three +ve’ standard deviation units and three —ve’ standard deviation units. Dr. Lalit M. Tiwari +91-9012761130
Thus ± 3σ of NPC include different number of cases separately. Between ± 1σ lie the middle 2/3rd cases or 68.26%, between ± 2σ lie 95.44% cases and between ± 3σ lie 99.73% cases and beyond + 3σ only 0.37% cases fall. Dr. Lalit M. Tiwari +91-9012761130
It is unimodal: • The curve is having only one peak point. Because the maximum frequency occurs only at one point. • The height of the curve symmetrically declines: • The height of the curve decline to both the direction symmetrically from the central point. Means the M + σ and M — σ are equal if the distance from the mean is equal. Dr. Lalit M. Tiwari +91-9012761130
The Mean of NPC is µ and the standard deviation is σ: • As the mean of the NPC represent the population mean so it is represented by the µ (Meu). The standard deviation of the curve is represented by the Greek Letter, σ. Dr. Lalit M. Tiwari +91-9012761130
In Normal Probability Curve the Standard deviation is the 50% larger than the Q: • In NPC the Q is generally called the probable error or PE. • The relationship between PE and a can be stated as following: • 1 PE = .6745σ • 1σ = 1.4826PE. Dr. Lalit M. Tiwari +91-9012761130
THE NORMAL CURVE HAS A MEAN = 0 AND A STANDARD DEVIATION = 1 Dr. Lalit M. Tiwari +91-9012761130
Dr. Lalit M. Tiwari +91-9012761130
Dr. Lalit M. Tiwari +91-9012761130
Dr. Lalit M. Tiwari +91-9012761130
Dr. Lalit M. Tiwari +91-9012761130
Dr. Lalit M. Tiwari +91-9012761130
Dr. Lalit M. Tiwari +91-9012761130
Dr. Lalit M. Tiwari +91-9012761130
Dr. Lalit M. Tiwari +91-9012761130
Dr. Lalit M. Tiwari +91-9012761130
Dr. Lalit M. Tiwari +91-9012761130
skewness • Some distributions of data, such as the bell curve are symmetric. This means that the right and the left of the distribution are perfect mirror images of one another. Not every distribution of data is symmetric. Sets of data that are not symmetric are said to be asymmetric. The measure of how asymmetric a distribution can be is called skewness. Dr. Lalit M. Tiwari +91-9012761130
skewness • The mean, median and mode are all measures of the center of a set of data. The skewness of the data can be determined by how these quantities are related to one another. Dr. Lalit M. Tiwari +91-9012761130
Skewed to the Right • Data that are skewed to the right have a long tail that extends to the right. An alternate way of talking about a data set skewed to the right is to say that it is positively skewed. In this situation, the mean and the median are both greater than the mode. As a general rule, most of the time for data skewed to the right, the mean will be greater than the median. In summary, for a data set skewed to the right: Dr. Lalit M. Tiwari +91-9012761130
Always: mean greater than the mode • Always: median greater than the mode • Most of the time: mean greater than median • Positive Skewness means when the tail on the right side of the distribution is longer or fatter. The mean and median will be greater than the mode. Dr. Lalit M. Tiwari +91-9012761130
Skewed to the Left • The situation reverses itself when we deal with data skewed to the left. Data that are skewed to the left have a long tail that extends to the left. An alternate way of talking about a data set skewed to the left is to say that it is negatively skewed. In this situation, the mean and the median are both less than the mode. As a general rule, most of the time for data skewed to the left, the mean will be less than the median. In summary, for a data set skewed to the left: Dr. Lalit M. Tiwari +91-9012761130
Always: mean less than the mode • Always: median less than the mode • Most of the time: mean less than median • Negative Skewness is when the tail of the left side of the distribution is longer or fatter than the tail on the right side. The mean and median will be less than the mode. Dr. Lalit M. Tiwari +91-9012761130
Measures of Skewness • One measure of skewness, called Pearson’s first coefficient of skewness, is to subtract the mean from the mode, and then divide this difference by the standard deviation of the data. This explains why data skewed to the right has positive skewness. If the data set is skewed to the right, the mean is greater than the mode, and so subtracting the mode from the mean gives a positive number. A similar argument explains why data skewed to the left has negative skewness. Dr. Lalit M. Tiwari +91-9012761130
skewness • Pearson’s second coefficient of skewness is also used to measure the asymmetry of a data set. For this quantity, we subtract the mode from the median, multiply this number by three and then divide by the standard deviation. Dr. Lalit M. Tiwari +91-9012761130
where: • Sk1 is Pearson's first coefficient of skewness and Sk2 the second; • s is the standard deviation for the sample; • x̄ is the mean value; • Mo is the modal (mode) value; and • Md is the median value Tripthi M. Mathew, MD, MPH
skewness • The rule of thumb seems to be: • If the skewness is between -0.5 and 0.5, the data are fairly symmetrical. • If the skewness is between -1 and -0.5(negatively skewed) or between 0.5 and 1(positively skewed), the data are moderately skewed. • If the skewness is less than -1(negatively skewed) or greater than 1(positively skewed), the data are highly skewed. Dr. Lalit M. Tiwari +91-9012761130
Kurtosis • Kurtosis is all about the tails of the distribution — not the peakedness or flatness. It is used to describe the extreme values in one versus the other tail. It is actually the measure of outliers present in the distribution. Dr. Lalit M. Tiwari +91-9012761130
High kurtosis in a data set is an indicator that data has heavy tails or outliers. If there is a high kurtosis, then, we need to investigate why do we have so many outliers. It indicates a lot of things, maybe wrong data entry or other things. Investigate! Dr. Lalit M. Tiwari +91-9012761130
Low kurtosis in a data set is an indicator that data has light tails or lack of outliers. If we get low kurtosis(too good to be true), then also we need to investigate and trim the dataset of unwanted results. Dr. Lalit M. Tiwari +91-9012761130
Dr. Lalit M. Tiwari +91-9012761130
Mesokurtic • : This distribution has kurtosis statistic similar to that of the normal distribution. It means that the extreme values of the distribution are similar to that of a normal distribution characteristic. This definition is used so that the standard normal distribution has a kurtosis of three. Dr. Lalit M. Tiwari +91-9012761130
Leptokurtic (Kurtosis > 3): • Distribution is longer, tails are fatter. Peak is higher and sharper than Mesokurtic, which means that data are heavy-tailed or profusion of outliers. Outliers stretch the horizontal axis of the histogram graph, which makes the bulk of the data appear in a narrow (“skinny”) vertical range, thereby giving the “skinniness” of a leptokurtic distribution. Dr. Lalit M. Tiwari +91-9012761130
Platykurtic: (Kurtosis < 3): • Distribution is shorter, tails are thinner than the normal distribution. The peak is lower and broader than Mesokurtic, which means that data are light-tailed or lack of outliers.The reason for this is because the extreme values are less than that of the normal distribution. Dr. Lalit M. Tiwari +91-9012761130
Dr. Lalit M. Tiwari +91-9012761130
Dr. Lalit M. Tiwari +91-9012761130
Dr. Lalit M. Tiwari +91-9012761130