Download

1 / 28
280 likes | 366 Views
Ontology support. For the Semantic Web. The big picture. Diagram, page 9 h tml5 xml can be used as a syntactic model for RDF and DAML/OIL RDF, RDF Schema (with data modeling) – RDF takes object specifications and flattens them into triples

E N D
Ontology support For the Semantic Web
The big picture • Diagram, page 9 • html5 • xml can be used as a syntactic model for RDF and DAML/OIL • RDF, RDF Schema (with data modeling) – RDF takes object specifications and flattens them into triples • DAML/OIL – used to specify the details of UPML components • UPML – architectural description language for components, adapters, connection configurations
DAML & OIL • DAML examples, pages 69 to 77 • OIL examples, pages 99 • OIL constraints 101 to 103 • Intriguing diagram, page 113
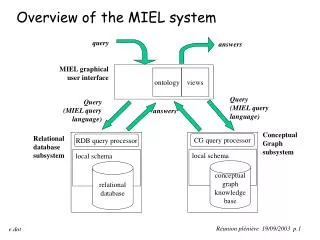
UPML • Diagram of UPML’s role, page 144 • Key function: “component markup” • UPML diagram, page 147 – a PSM is a “problem solving method” • Protégé is a free editor for ontology-related languages, page 160 & 162
Another Big view of the semantic web • Diagram, page 173 • Intriguing comparison diagram, page 175 • Extra capabilities of ontologies over lower level specifications • Consistency • Filling in semantic details • Interoperability support • Validation and verification • Configuration support • Support for structured searches • Generalization/specialization meta information
Interesting twist on how databases should be built • Old way – page 266 • New way – page 268 • The smarter DB architecture, page 273 • What are we adding? • Used to be data, schema, then sql, then transaction manager, then apps, then UI • Now we are introducing more metadata? More schema? • Or is this a completely different kind of database? • Where data consists of assertions?
A “semantic portal” • Page 320 • Both humans and “agents” can access semantic portals • But how do humans interact with a semantic portal via a browser? • Comparison between ontologies and knowledge – page 322 • The idea of extensibility as a critical aspect of the semantic web • Not just new data, not just new metadata, but new inferences as well • Big picture diagram, page 333
Semantic Gadgets concept • Making smarts ubiquitous • The Internet of Things and Ambient Intelligence • For learning, mobile activities, using remote services • Mobile computing and mobile-based queries • Devices that can interact with our devices • Museum locations and user with sound device • Hand held devices and grocery store shopping and congnitivelydisabled
Semantic annotation concept • Diagram – page 406 • Detailed diagram – page 415 • Example – pages 417 and 418 • We see the use of parallel databases that hold metadata that is searchable • And metadata can be applied in a personalized way to provide specific results to specific users • See page 420……..
Task-achieving agents notion • Diagram, page 434 • Kinds of tasks • Automated planning • Computer-supported cooperative work • Multi-agent mixed-initiative planning • Workflow support • Example diagram, page 442 • This is a common way of viewing the new web • Smart agents replace browsers
A concrete component: SPARQL • Query language modeled after SQL • It can walk through semantic websites and across semantic websites • SPARQL thus creates new knowledge by creating inferences that can cross website boundaries
From - http://www.cambridgesemantics.com/2008/09/sparql-by-example/ • A SPARQL query comprises, in order: • Prefix declarations, for abbreviating URIs • Dataset definition, stating what RDF graph(s) are being queried • A result clause, identifying what information to return from the query • The query pattern, specifying what to query for in the underlying dataset • Query modifiers, slicing, ordering, and otherwise rearranging query results
What can sparql do? • It can extend an ontology by adding new inferences as assertions • Retrieve triples that describe something • Ask true or false questions based on assertions
Another view: The open semantic framework • Layered architecture • Modular software • It is part of a four component approach: • Software • Structure • Documentation • Methods
Goals • Leverage existing data and apps • Build and validate incrementally • Use open software, standards, protocols • Link data • Use RDF as a unifying data model • Address high level IT management issues • Assumptions and techniques • Use URIs to identify information • All data is equal – text, media, relational dbs
Big picture – from:http://openstructs.org/open-semantic-framework/overview
layers • Existing assets • Databases of all kinds • Web pages • Documents • Information Transformation (scones/irON) • Extraction of data and metadata • Scones – subject concept or named entities • Conversions – via irON (instance record Object Notation)
Layers continued • structWSF layer • The “workhorse” • Web services framework • Provides a common interface layer by which existing info assets can be mediated • Include CRUD, browse, search, export, import primitives • Supports sparql • Rights and permissions controls • Each structWSF instance has a unique Web address that allow easy use/reuse and reconfiguration
Layers continued • Semantic Components layer • Takes computed results generated via queries from one or more structWSF instances and presents data visually using “semantic components” • Components include • Filter • Tabular templates • Bar, pie, other charts • Relationship browser • Annotator
Layers continued • Ontologies layer • Content Management System layer (conStruct) • Thin • Endpoints • Portals • Collaborative environments • Media rich
Hmm… you can download it • http://techwiki.openstructs.org/index.php/Open_Semantic_Framework_Installer
Another view of ontologies:http://www.cems.uwe.ac.uk/amrc/seeds/ModellingSemanticWeb.htm
What is it? • DBpedia is a community effort to extract structured information from Wikipedia and to make this information available on the Web. DBpedia allows you to ask sophisticated queries against Wikipedia, and to link other data sets on the Web to Wikipedia data. We hope this will make it easier for the amazing amount of information in Wikipedia to be used in new and interesting ways, and that it might inspire new mechanisms for navigating, linking and improving the encyclopaedia itself.
Facts:http://dbpedia.org/About • The DBpedia knowledge base currently describes more than 3.64 million things • 416,000 persons, 526,000 places, 106,000 music albums, 60,000 films, 17,500 video games, 169,000 organisations, 183,000 species and 5,400 diseases • The DBpedia knowledge base allows you to ask quite surprising queries against Wikipedia, for instance “Give me all cities in New Jersey with more than 10,000 inhabitants” or “Give me all Italian musicians from the 18th century” • The DBpedia data set is interlinked with various other datasets on the Web.