Download
1 / 1
10 likes | 136 Views
COSTA: Adaptive Indexing for Terms in a Large-scale Distributed System. # $. #. *. $. Aoying Zhou , Rong Zhang , Quang Hieu Vu , Weining Qian. # Department of Computer Science and Engineering, Fudan University, Shanghai, China; { ayzhou,rongzh }@ fudan.edu.cn

E N D
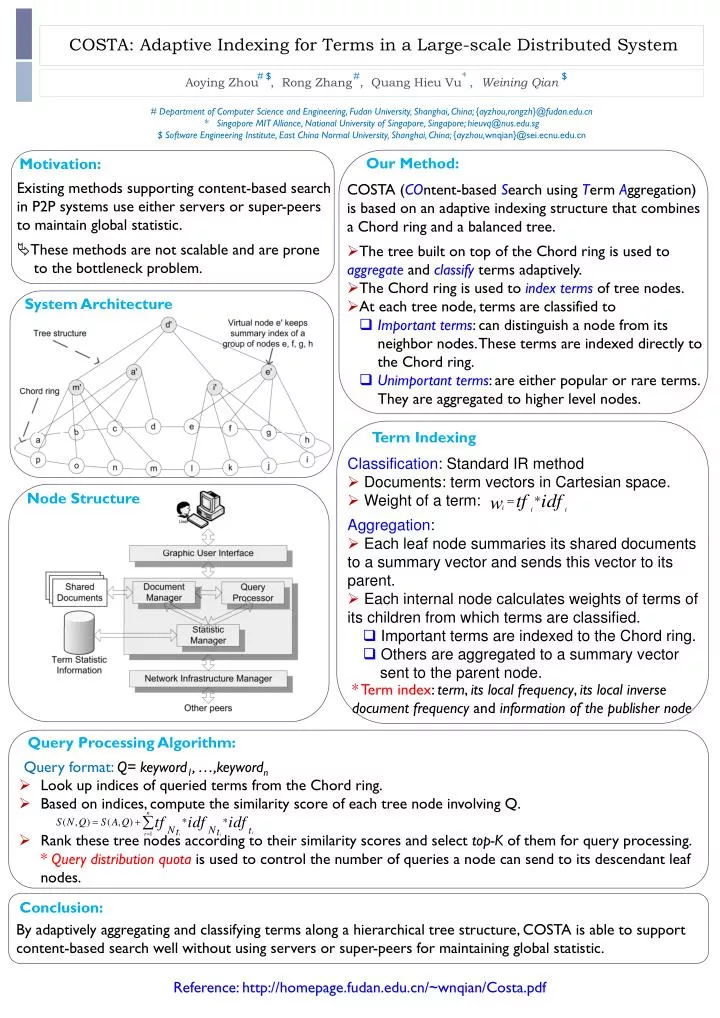
COSTA: Adaptive Indexing for Terms in a Large-scale Distributed System # $ # * $ Aoying Zhou , Rong Zhang , Quang Hieu Vu , Weining Qian # Department of Computer Science and Engineering, Fudan University, Shanghai, China; {ayzhou,rongzh}@fudan.edu.cn * ¤Singapore MIT Alliance, National University of Singapore, Singapore; hieuvq@nus.edu.sg $ Software Engineering Institute, East China Normal University, Shanghai, China; {ayzhou,wnqian}@sei.ecnu.edu.cn Our Method: Motivation: Existing methods supporting content-based search in P2P systems use either servers or super-peers to maintain global statistic. These methods are not scalable and are prone to the bottleneck problem. • COSTA (COntent-based Search using Term Aggregation) is based on an adaptive indexing structure that combines a Chord ring and a balanced tree. • The tree built on top of the Chord ring is used to aggregate and classify terms adaptively. • The Chord ring is used to index terms of tree nodes. • At each tree node, terms are classified to • Important terms: can distinguish a node from its neighbor nodes. These terms are indexed directly to the Chord ring. • Unimportant terms: are either popular or rare terms. They are aggregated to higher level nodes. System Architecture Term Indexing • Classification: Standard IR method • Documents: term vectors in Cartesian space. • Weight of a term: • Aggregation: • Each leaf node summaries its shared documents to a summary vector and sends this vector to its parent. • Each internal node calculates weights of terms of its children from which terms are classified. • Important terms are indexed to the Chord ring. • Others are aggregated to a summary vector sent to the parent node. Node Structure *Term index: term, its local frequency, its local inverse document frequency and information of the publisher node Query Processing Algorithm: Query format: Q= keyword1, …,keywordn • Look up indices of queried terms from the Chord ring. • Based on indices, compute the similarity score of each tree node involving Q. • Rank these tree nodes according to their similarity scores and select top-K of them for query processing. • * Query distribution quota is used to control the number of queries a node can send to its descendant leaf nodes. Conclusion: By adaptively aggregating and classifying terms along a hierarchical tree structure, COSTA is able to support content-based search well without using servers or super-peers for maintaining global statistic. Reference: http://homepage.fudan.edu.cn/~wnqian/Costa.pdf






















