Download

1 / 24
240 likes | 248 Views
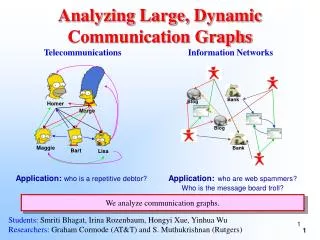
Monitoring Properties of Large, Distributed, Dynamic Graphs (IPDPS 2017) Gal Yehuda Daniel Keren. Graphs of interest used to be static and centralized.

E N D
Monitoring Properties of Large, Distributed, Dynamic Graphs (IPDPS 2017) Gal Yehuda Daniel Keren
Graphs of interest used to be static and centralized. • For some time, dynamic graphs (edges arrive and are deleted) have been a focus of research. It is almost always assumed that the graph is centralized. • However, many graphs which are prevalent in real-life applications are both dynamic and distributed (Youtube, Google, Internet…).
S2 S1 • We assume that: • Vertices are fixed and known to all servers. • Edges can appear and disappear; each server knows only about the edges it inserted or deleted. Edges are not duplicated between servers.
It follows that, at any time step, the global adjacency matrix is the sum of the local ones (i.e. held at the distinct servers). • We are interested in computing, approximating, or bounding some global function over the graph, but w/o continuously centralizing it. • An instance of the distributed monitoring problem – i.e. G. Cormode, 2013. • Solution: define conditions which can be checked locally and efficiently, and imply the global condition. These conditions should be resilient, so as to have a minimal number of “false alarms”. • For some problems, this is quite difficult… e.g. distinct count.
Taking a step back… simpler example: detecting spam in a distributed e-mail server. Reminder: given a feature-category contingency table its mutual information is defined as If : SPAM, if : NOT SPAM
Need to infer on global threshold crossing from the local threshold crossings… that’s NOT always easy. For general functions, what does the average of the values tell us about the value at the average?
The general architecture we consider As common in distributed monitoring, we forgo exact computation of , and settle for threshold queries.
How then to define “good” LOCAL conditions? • GM – the Geometric Method. Work since 2006. Is NP-Complete, even for one-dimensional data (under appropriate definitions of optimality). SIGMOD 2016, VLDB 2013+2015, KDD 2015, TODS 2014, ICDE 2014… • Good results, general solution. Improved state-of-the-art for previously studied functions, and solved for functions which previous methods could not handle. • However, a major difficulty for some problems: a geometric constraint needs to be checked at each server, which can be exceedingly difficult. For monitoring cosine similarity, running time for a single check, using state-of-the-art software, was in the minutes.
An alternative solution (Lazerson/Keren/Schuster, KDD 2016): convex functions. Reminder: a function is convex iff the value at the average is smaller than the average of the values: So they are beautifully suited to monitoring: if the threshold condition locally holds at every node, it automatically holds globally!
Another reminder – a function is convex iff it lies above all its tangent planes (this will soon prove useful).
What about non-convex functions? • Solution – tightly boundthe monitored function with a larger convex function (CB, for convex/concave bound), and monitor the CB. Our previous work used approximations with convex sets; see also Lipman, Yagev, Poranne, Jacobs, Basri: Feature Matching with Bounded Distortion. Need different functions for different initial points WLG, assume that the data at all nodes starts at a fixed point and drifts from it.
In a nutshell System problem (minimize communication) Mathematical problem (good convex bound)
Some simple examples… • If is convex, the optimal bound is of course… • If is concave, the optimal bound at is… • If is neither, for example the optimal bound is… ??? You’re probably guessing… and you’re correct to some extent.
Ideally, an optimal (upper) convex bound, , for at the point should satisfy: • If is a convex bound for satisfying the above two requirements, it must hold that • Turns out that such a bound is impossible to achieve (except for the trivial cases, in which is either convex or concave): Theorem: for , the family of convex quadratics defined by are all minimal upper bounds for , however, no pair of them can be compared –i.e. given two of them, , then Neither nor holds
Two members of the family of bounding functions (green) for (blue). The two bounds super-imposed – non is larger than the other.
This is bad news… since every function which is not convex nor concave contains a “copy” of ! One can argue that is optimal in some sense, as it is the “slowest changing” in the family of bounds. But… MORE bad news! How to find an even “reasonable” convex bound? Guess: expand to a second-order Taylor series, truncate the terms of order >= 3, and remove the “negative part” of the Hessian. BUT – this is not guaranteed to be a bound!
So… “There is a town in North Ontario…” Seems like a rather difficult problem. Recall that min of convex is not convex.
Still, we hacked some solutions. This is how the bounds look for the Pearson Correlation Coefficient (KDD 2016): Concave lower bound CB p p Convex upper bound PCC Also: PCA (effective) dimension, inner product, cosine similarity.
For the distributed, dynamic graphs, we looked at two popular functions: eigenvalue gap and number of triangles. Both can be expressed as homogenous functions (of degrees 1 and 3) of the adjacency matrix eigenvalues, so we can reduce to the case in which the global matrix is the average of the local ones. It remains to find good convex bounds. Remark: since all local matrices are initially set to the average of the global matrix, the monitoring can commence even if some of the local graphs do NOT abide by the monitored condition, e.g. have a gap smaller than the threshold.
Why is it necessary? Generally, impossible to infer on the global values from the local ones. Erdős–Rényi Scale Free
Concave (lower) bound for eigenvalue gap Assume a matrix is known at time 0. Find a “good” (tight) concave lower bound for Note that is convex, alas is neither convex nor concave. Use a variational definition of (Min-max): Now define , where Is the Leading eigenvector at time 0. Finally, define , where is the tangent plane to at time 0.
Two (rather technical) theorems: • The bound is optimal to second order. • It can be computed very fast by a modification of power methods. Works better for denser graphs (under the change of the same percentage of edges). Ratio of bound to actual value. Works well for real graphs as well (Youtube and Flickr).
Number of triangles = sum of cubes of eigenvalues. Let’s start by bounding a cubic in one variable. Optimal convex bound around 0 is simply . Use the following beautiful theorem to extend to sum of cubes of the eigenvalues: (Davis, 1957): any symmetric convex function of the eigenvalues of a symmetric matrix is a convex function of that matrix. To handle general matrices (i.e. not around the zero matrix but a general one, ), use
Future work • Improve these results, esp. for number of triangles (complexity is high, need to compute many eigenvalues). Use sketches and other tools of the trade. • Further investigate how to proceed when a local violation occurs – can we do something more efficient than centralizing the data. • Drop the sum-of-local-models assumption, e.g study decision trees in which the nodes are “horizontally partitioned” between the servers. Thank you! Questions?