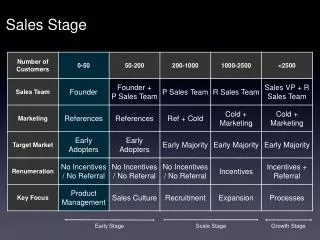
Download

1 / 46
460 likes | 477 Views
Learn about the potential of data science in audit, including the questions it can answer and how it is carried out. Gain insights from real-world use cases and understand the value of data in enhancing customer experience and decision-making.

E N D
Agenda 1. Introduction to what data science can accomplish 2. Understand what questions data science can answer 3. Overview of how data science is carried out 4. Use cases in Audit Disclaimer : This talk will not make you an expert. It will give you an overview so you can learn more on your own.
What Are Data Science and Machine Learning? • Data science is a "concept to unify statistics, data analysis and their related methods" in order to "understand and analyze actual phenomena" with data. - Chikio Hayashi • Machine learning is a “field of study that gives computers the ability to learn without being explicitly programmed” - Arthur Samuel • We use data science and machine learning to enable computers to help us understand or make predictions about the world.
Why Use Data Science? • To delight our customers • To help aid in understanding of complex phenomena • To make predictions and classify the world for us
Data Empowers Us To Delight Our Customers • What would change if you understand how your features are being used by customers? • How they are *actually* used not how you intend them to be used? • Could you… • plan better? • fix the right bugs? • Customers tell us in their actions what they want. • Are we listening?
Data Helps Us Understand Why Things Happen • Given a set of outcomes and potential contributing factors, data science and machine learning can help us understand which factors most determine the outcome.
Data Can Help Classify the World • Computers can be trained to recognize items and predict what a new item is likely to be. • Example:
Analysis Starts with the Right Question • What do you want to know? • What action will you take when you know the answer? • Begin with your business questions • Let the questions inform the necessary data and type of analysis • Do not start with data and ask what questions you might answer • The question starts the process…
What Is Happening? Counting & Summarizing
Counting isn’t easy Audit: • How many people have access to a system? • Not as easy as it looks • Do we count only FTE or vendors? • Do we count people that left yesterday? • Do we count people who have left our company way before? • … Consider: • How many machines were running Windows 10 yesterday? • Not as easy as it looks • Do we count virtual machines? • Do we count machines that uninstalled yesterday? • Do we count machines that were off all day? • …
Summarizing • More than 8 million devices sampled in Windows telemetry • Cannot reason over all of them • Represent with a summary (Typically some measure of centrality) • Mean/Average • Median • Standard Deviation
Is There a Difference? Inference
Comparing Groups • Often we want to understand if one population is different from another in some respect • We may hypothesize that they are the same • Men and women use our product the same way • Or that one is better/worse than the other • People under 30 spend more money on video games • We can do this with Inference and Hypothesis Testing
Calculating Significance of Results • When running a test, we want to know if the effect we observed was due to random chance or if it was significant. • A result is typically said to be significant if it wouldn’t happen by random chance more than 5% of the time. • Examples: • We made fixes to the notification system. Lost messages fell by 3%. • Is that because of our fix or was it merely chance? • Users of our new ink smoothing algorithm spent 3 more minutes using ink than users of the old system. • Is that significant?
More Inference Examples • Are the user access patterns similar this month to last month? • Do women and men have the same valuation of our product?
Why Are Things Happening? RegressionAnalysis
Whichfactors contribute to an observed outcome? • We know some effect is taking place. Considering all possible causes, which one(s) contribute and by how much? • Domain expertise provides many of the factors to consider • How do we quantify the effect of each feature/factor? Example Are all partners risky when we are selecting samples? If so, how many should we select? • Which factors affect partner risk? • Can we quantify?
Correlation vs Causation • Correlation does not imply causation • Do space launches encourage people to get sociology degrees? • Was Internet Explorer Responsible for a high murder rate? • Only experiments can establish causation • Random assignment • A/B Testing
Confounding Variables • Causal Variable: • Confounding Variable: Low App Reliability API Crashes a lot Murder Rate Warm Weather Ice Cream
More Regression Examples • Area Audits - What activities are connected with corruption? • Areas with more issues/red audits may have behavior in common • IT Audits • What activities (code reviews, tests, self hosting) contribute to successful code integrations? • What activities are connected with security breaches? • Groups with breaches may have behavior in common
What will be the value? Prediction
Predictions • What is the user is likely to do next (TnE fraud)? • How many other cases like this can happen in the given geography? • Is a particular result is unexpected? • These type of questions are answered with machine learning
Machine Learning Isn’t An Exact Science Learn over time ML
Machine Learning • Many different machine learning methods • Each is tailored to different kinds of data • Typical examples: Support Vector Machines, Decision Trees, Logistic Regression, Neural Networks, Arima • All accomplish same basic task: • Given data rows with known values: predict values for new rows. Weather
Two Types of Outcomes • If we want to predict a numeric value, we use regression. • If we want to predict a class, we use classification.
Fraud Detection Xbox, Windows Store, etc. use ML models to detect fraud • Gather data about existing transactions • Label transactions as fraud or not fraud • Train a model to recognize the difference • Model generates likelihood of fraud for each new transaction • Investigate Helps in finding a scenario Active Listening
More Classification Examples • Which apps were broken by this build? • We can predict how much use we expect and compare to what it really was. • Which bug is this user feedback talking about? • Predict which existing bug a new UIF is likely an occurrence of. • Is this access request legitimate? • Predict whether a particular access is likely legitimate or a breach.
What are the groupings? Clustering/ Cluster Analysis
What groupings exist in this data? • Given a set of data, do they naturally divide into groups based on features? • No outcome labels (“Unsupervised” machine learning) • Some groups may be interesting to humans, others may not be • Humans must interpret the groups • Groups may later be labeled for use in prediction models Examples • How similar are our audit issues based on their issue description? • How similar are websites based on the APIs they implement?
Clustering Grouping based on distance metric (distance between pairs of observations) Multiple options for approach • Hierarchical • Agglomerative approach: • find two closest points and merge them • Then merge next two closest points or groups • Produces a tree called a dendrogram • K-means • Must choose number of groups beforehand • Computer assigns points, minimizing distance within the group Cut line for 10 clusters (Top 1000 websites, by API “similarity”)
Diving Deeper… • Watch some videos • WDG Data Club talks: https://aka.ms/DataClub • Read more about data science • Data Science Teams or Demand for Data Scientists • Wikipedia • Get a certificate • Johns Hopkins Coursera or Microsoft Professional Program for Data Science • Get a Masters degree • Berkeley, University of Illinois, and others offer online Masters in Data Science
Tips and Best Practices • Prepare to make mistakes and iterate • Finding the appropriate features, questions and data can be challenging • Do not be afraid to explore and follow your curiosity about what is going on • Pick your question before you collect your data • Good: “What question do I want to answer?” • Not Good: “What question can I answer with my data?” • Processing data can be complex and time-consuming • Add plenty of time for this part of the process • Experimental results can hinge on seemingly minor assumptions • Consult a Data Scientistearly to get advice and avoid costly do overs or lost opportunities • If you cannot measure what you want, look for or define proxies to approximate
Key Takeaways • Your first query is rarely enough in big data; there is more to the story machine learning, analytics & data science • Supervised uses ground truth vs unsupervised does not have ground truth • Data matters (labeling, feature engineering); dataqualitymatters even more • There are many resources available to help! Find your local Data Scientists!
Your Turn… Which approach would you choose?
What type of question is this? What are the similar areas in terms of audit risk? • What is happening? (Summarizing and Counting) • Is there a difference that matters? (Inference) • Why is it happening? (Regression) • What are the groups? (Clustering) Answer: What are the groups?
What technique would you use? Given an organization’s risk assessment features (for each sub-domain), what is the overall risk? • Summarizing and Counting • Inference • Prediction • Clustering Answer: Prediction
Which predictive method would you use? Given an organization’s risk assessment features (for each sub-domain), what is the overall risk? • Regression • Classification • Clustering Answer: Classification. In this case, we would be predicting the risk quadrant or class(Improve, Monitor, Tolerate, or Operate)
What technique would you use? Are the rates of unauthorized access for one group different from the other group in your company? • Summarizing and Counting • Inference • Prediction • Clustering Answer: Inference. Summarizing will tell you they are different, but not if that is (statistically) significant.
PROCESS CHANGE Migrated the Audit Group TECA*– a finance team-built-and-owned data warehouse application that provides data for audit group (audit, risk, investigations, compliance) and Board of Director Audit Committee reports to MSIT** hosting and support. Audit Finance and MSIT Partnership • PAIN POINTS • Servers and system maintenance • Data loads refreshed monthly/quarterly • Harder to recover from failure • Less time available for Data Analytics • Old version of SQL server • Reactive resolution instead of proactive TECA MSIT OnboardingProject TECHNOLOGY • SOLUTION • Audit Group TECA infrastructure, data loads, and reports migrated to MSIT hosting • Always-on secondary environment for faster failover recovery • Power BI Report Telemetry Dashboard Azure IaaS VM SQL Server 2016 SSRS TCM Incident Ticketing Power BI OMS System Monitoring TIME TO IMPLEMENT Q2 – Q4 FY17 • RESULTS • 93% reduction in user driven support tickets • All data sources for TECA refreshed daily & accurately • Audit TECA team can focus time fulfilling their core mission instead of IT related tasks