Download
1 / 22
220 likes | 418 Views
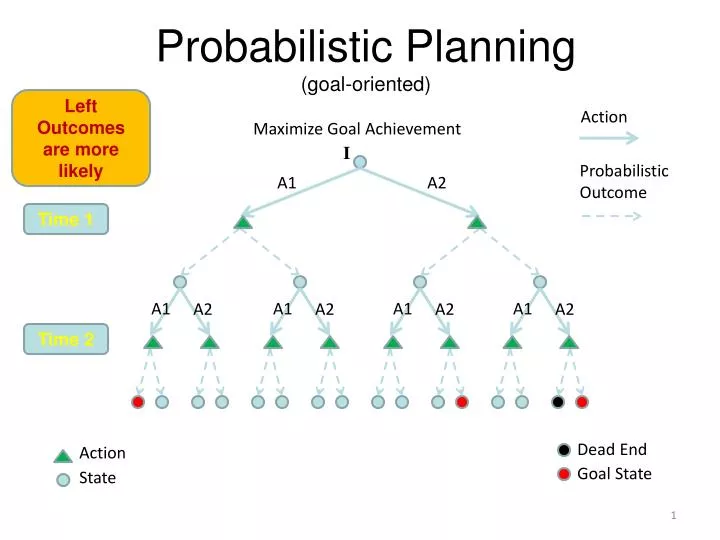
Probabilistic Planning (goal-oriented). Left Outcomes are more likely. Action. Maximize Goal Achievement. I. Probabilistic Outcome. A1. A2. Time 1. A1. A1. A1. A1. A2. A2. A2. A2. Time 2. Dead End. Action. Goal State. State. 1. FF-Replan. Simple replanner

E N D
Probabilistic Planning(goal-oriented) Left Outcomes are more likely Action Maximize Goal Achievement I Probabilistic Outcome A1 A2 Time 1 A1 A1 A1 A1 A2 A2 A2 A2 Time 2 Dead End Action Goal State State 1
FF-Replan • Simple replanner • Determinizes the probabilistic problem • Solves for a plan in the determinized problem a3 G a5 a4 a2 a1 a2 a3 a4 S G
All Outcome Replanning (FFRA) ICAPS-07 Effect 1 Action1 Effect 1 Probability1 Action Probability2 Effect 2 Action2 Effect 2 3
Probabilistic PlanningAll Outcome Determinization Action Find Goal I Probabilistic Outcome A1 A2 Time 1 A1-1 A1-2 A2-1 A2-2 A1 A1 A1 A1 A2 A2 A2 A2 Time 2 A1-1 A1-2 A2-1 A2-2 A1-1 A1-2 A2-1 A2-2 A1-1 A1-2 A2-1 A2-2 A1-1 A1-2 A2-1 A2-2 Dead End Action Goal State State 4
Probabilistic PlanningAll Outcome Determinization Action Find Goal I Probabilistic Outcome A1 A2 Time 1 A1-1 A1-2 A2-1 A2-2 A1 A1 A1 A1 A2 A2 A2 A2 Time 2 A1-1 A1-2 A2-1 A2-2 A1-1 A1-2 A2-1 A2-2 A1-1 A1-2 A2-1 A2-2 A1-1 A1-2 A2-1 A2-2 Dead End Action Goal State State 5
Problems of FF-Replan and better alternative sampling FF-Replan’s Static Determinizations don’t respect probabilities. We need “Probabilistic and Dynamic Determinization” Sample Future Outcomes and Determinization in Hindsight Each Future Sample Becomes a Known-Future Deterministic Problem 6
Hindsight Optimization • Probabilistic Planning via Determinization in Hindsight • Adds some probabilistic intelligence • A kind of dynamic determinization of FF-Replan
Implementation FF-Hindsight Constructs a set of futures • Solves the planning problem using the H-horizon futures using FF • Sums the rewards of each of the plans • Chooses action with largest Qhs value
Probabilistic Planning(goal-oriented) Left Outcomes are more likely Action Maximize Goal Achievement I Probabilistic Outcome A1 A2 Time 1 A1 A1 A1 A1 A2 A2 A2 A2 Time 2 Dead End Action Goal State State 9
Sample Time! Start Sampling Note. Sampling will reveal which is better A1? Or A2 at state I 10
Hindsight Sample 1 Left Outcomes are more likely Action Maximize Goal Achievement I Probabilistic Outcome A1 A2 Time 1 A1 A1 A1 A1 A2 A2 A2 A2 Time 2 A1: 1 A2: 0 Dead End Action Goal State State 11
Hindsight Sample 2 Left Outcomes are more likely Action Maximize Goal Achievement I Probabilistic Outcome A1 A2 Time 1 A1 A1 A1 A1 A2 A2 A2 A2 Time 2 A1: 2 A2: 1 Dead End Action Goal State State 12
Hindsight Sample 3 Left Outcomes are more likely Action Maximize Goal Achievement I Probabilistic Outcome A1 A2 Time 1 A1 A1 A1 A1 A2 A2 A2 A2 Time 2 A1: 2 A2: 1 Dead End Action Goal State State 13
Hindsight Sample Left Outcomes are more likely Action Maximize Goal Achievement I Probabilistic Outcome A1 A2 Time 1 A1 A1 A1 A1 A2 A2 A2 A2 Time 2 A1: 3 A2: 1 Dead End Action Goal State State 14
Action Selection • We can now choose the action with the greatest Qhs value (A1) A1: 3 A2: 1 • Better action selection than FF-Replan • Reflects probabilistic outcomes of the actions
Constraints on FF-Hop • Number of futures limits exploration • Many plans need to be solved per action in action selection • Max depth of search is static and limited (horizon)
Improving Hindsight Optimization • Scaling Hindsight Optimization for Probabilistic Planning • Uses three methods to improve FF-Hop • Zero-step look ahead (Useful action detection, sample and plan reuse) • Exploits determinism • All-outcome determinization • Significantly improves the scalability of FF-Hop by reducing the number of plans solved by FF
Deterministic Techniques for Stochastic Planning No longer the Rodney Dangerfield of Stochastic Planning?
Solving stochastic planning problems via determinizations • Quite an old idea (e.g. envelope extension methods) • What is new is that there is increasing realization that determinizing approaches provide state-of-the-art performance • Even for probabilistically interesting domains • Should be a happy occasion..
To compute the conditional branches Robinson et al. To seed/approximate the value function ReTraSE,Peng Dai, McLUG/POND, FF-Hop Use single determinization FF-replan ReTrASE (use diverse plans for a single determinization) Use sampled determinizations FF-hop [AAAI 2008; with Yoon et al] Use Relaxed solutions (for sampled determinizations) Peng Dai’s paper McLug [AIJ 2008; with Bryce et al] Ways of using deterministic planning Determinization = Sampling evolution of the world Would be good to understand the tradeoffs…
Comparing approaches.. • ReTrASE and FF-Hop seem closely related • ReTrASE uses diverse deterministic plans for a single determinization; FF-HOP computes deterministic plans for sampled determinizations • Is there any guarantee that syntactic (action) diversity is actually related to likely sample worlds? • Cost of generating deterministic plans isn’t exactly too cheap.. • Relaxed reachability style approaches can compute multiple plans (for samples of the worlds) • Would relaxation of samples’ plans be better or worse in convergence terms..?
Mathematical Summary of the Algorithm Each Future is a Deterministic Problem Done by FF • H-horizon future FH for M = [S,A,T,R] • Mapping of state, action and time (h<H) to a state • S × A × h → S • Value of a policy π for FH • R(s,FH, π) • VHS(s,H) = EFH [maxπ R(s,FH,π)] • Compare this and the real value • V*(s,H) = maxπ EFH [ R(s,FH,π) ] • VFFRa(s) = maxFV(s,F) ≥ VHS(s,H) ≥ V*(s,H) • Q(s,a,H) = (R(a) + EFH-1 [maxπ R(a(s),FH-1,π)] ) • In our proposal, computation of maxπ R(s,FH-1,π) is approximately done by FF [Hoffmann and Nebel ’01] 29




















