Download
1 / 32
330 likes | 440 Views
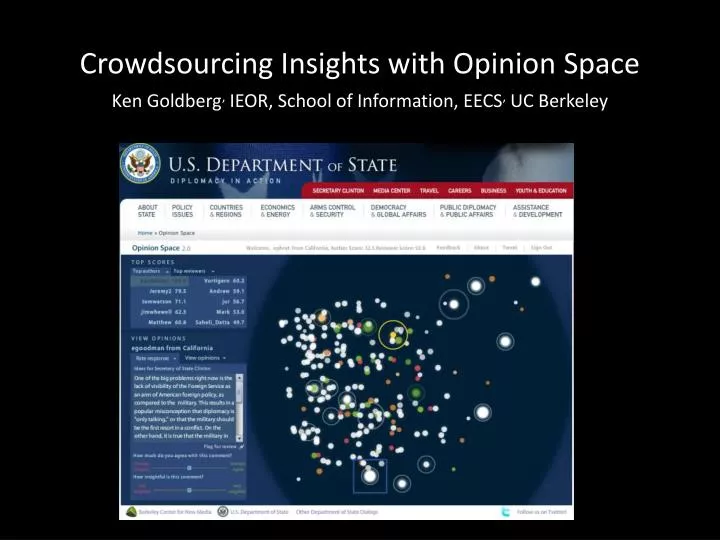
Crowdsourcing Insights with Opinion Space. Ken Goldberg , IEOR, School of Information, EECS , UC Berkeley. “We’re moving from an Information Age to an Opinion Age.” - Warren Sack, UCSC. Motivation. Goals Engage community Understand community Solicit input

E N D
Crowdsourcing Insights with Opinion Space Ken Goldberg, IEOR, School of Information, EECS, UC Berkeley
“We’re moving from an Information Age to an Opinion Age.” - Warren Sack, UCSC
Motivation Goals • Engage community • Understand community • Solicit input • Understand the distribution of viewpoints • Discover insightful comments Goals of Community Members • Understand relationship to other community members • Participate, express ideas, and be heard • Encounter a diversity of viewpoints
Motivation Classic approach: surveys, polls Drawbacks: limited samples, slow, doesn’t increase engagement Modern approach: online forums, comment lists Drawbacks: data deluge, cyberpolarization, hard to discover insights
Related Work: Visualization Clockwise, starting from top left: Morningside Analytics, MusicBox, Starry Night
Related Work: Politics Clockwise, starting from top left: EU Profiler, Poligraph, The How Progressive Are You? quiz
Related Work: Opinion Sharing • Polling & Opinion Mining • Fishkin, 1991: deliberative polling • Dahlgren, 2005: Internet & the public sphere • Berinsky, 1999: understanding public opinion • Pang & Lee, 2008: sentiment analysis • Increasing Participation • Bishop, 2007: theoretical framework • Brandtzaeg & Heim: user study • Ludford et al, 2004: uniqueness & group dissimilarity
Related Work: Info Filtering • K. Goldberg et al, 2001: Eigentaste • E. Bitton, 2009: spatial model • Polikar, 2006: ensemble learning
Opinion Space: Live Demonstration
Six 50-minute Learning Object Modules, preparation materials, slides for in-class lectures, discussion ideas, hand-on activities, and homework assignments.
To try it: google: “opinion space” contact us: http://goldberg.berkeley.edu
Dimensionality Reduction low variance projection maximal variance projection
Dimensionality Reduction Principal Component Analysis (PCA) • Assumes independence and linearity • Minimizes squared error • Scalable: compute position of new user in constant time
Canonical Correlation Analysis z • 2-view PCA • Assume: • Each data point has a latent low-dim canonical representation z • Observetwo different representations of each data point (e.g. numerical ratings and text) • Learn MLEs for low-rank projections A and B • Equivalently, pick projection that maximizes correlation between views x y Graphical model for CCA x = Az + ε y = Bz + ε z = A-1x = B-1y
CCA on Opinion Space z • Each user is a data point • xi = user i’s responses to propositions • yi = vector representation of textual comment • Run CCA to find A and B, use A-1 to find 2D representation • Position of users reflects rating vector and textual response • Ignores ratings that are not correlated with text, and vice versa • Given text, can predict ratings (using B) x y Graphical model for CCA x = Az + ε y = Bz + ε z = A-1x = B-1y
Multidimensional Scaling • Goal: rearrange objects in low dim space so as to reproduce distances in higher dim • Strategy: Rearrange & compare solns, maximizing goodness of fit: • Can use any kind of similarity function • Pros • Data need not be normal, relationships need not be linear • Tends to yield fewer factors than FA • Con: slow, not scalable j δij i j dij i
Kernel-based Nonlinear PCA • Intuition: in general, can’t linearly separate n points in d < n dim, but can almost always do so in d ≥ n dim • Method: compute covariance matrix after transforming data into higher dim space • Kernel trick used to improve complexity • If Φ is the identity, Kernel PCA = PCA
Kernel-based Nonlinear PCA Input data KPCA output with Gaussian kernel • Pro: Good for finding clusters with arbitrary shape • Cons: Need to choose appropriate kernel (no unique solution); does not preserve distance relationships
Stochastic Neighbor Embedding • Converts Euclidean dists to conditional probabilities • pj|i = Pr(xi would pick xj as its neighbor | neighbors picked according to their density under a Gaussian centered at xi) • Compute similar prob qj|i in lower dim space • Goal: minimize mismatch between pj|i and qj|i: • Cons: tends to crowd points in center of map; difficult to optimize
Six 50-minute Learning Object Modules, preparation materials, slides for in-class lectures, discussion ideas, hand-on activities, and homework assignments.
Opinion Space: Crowdsourcing Insights Scalability: n Participants, n Viewpoints n2 Peer to Peer Reviews Viewpoints are k-Dimensional Dim. Reduction: 2D Map of Affinity/Similarity Insight vs. Agreement: Nonlinear Scoring Ken Goldberg, UC Berkeley Alec Ross, U.S. State Dept
Opinion Space Wisdom of Crowds: Insights are Rare Scalable, Self-Organizing, Spatial Interface Visualize Diversity of Viewpoints Incorporate Position into Scoring Metrics Ken Goldberg UC Berkeley