Download
1 / 62
620 likes | 650 Views
Arexis leverages bioinformatics and genetic analysis to link genes to biological functions, driving drug target discovery for metabolic and inflammatory diseases. The organization's research and development strategy includes animal models, disease modeling, target validation, and drug discovery leading to clinical development. Arexis focuses on comparative biology using human patient materials and offers biotechnology expertise, medicinal chemistry, and clinical pharmacology for functional genomics. The company's R&D projects encompass innovative approaches for tackling conditions like Type 2 diabetes, obesity, rheumatoid arthritis, and multiple sclerosis.

E N D
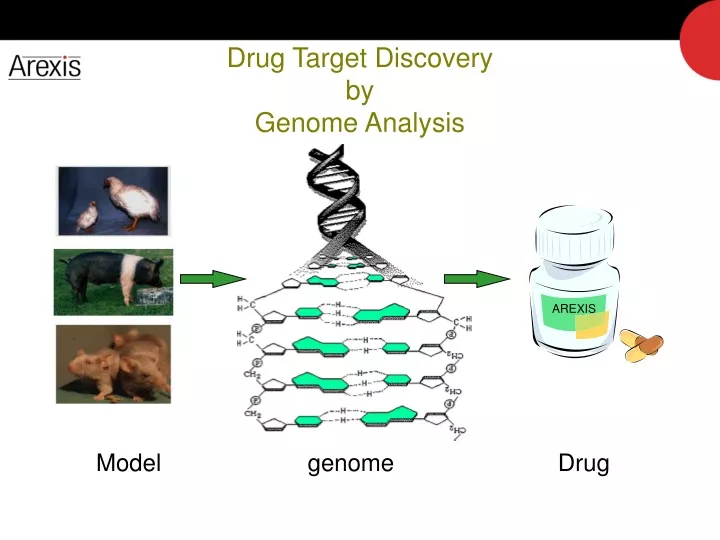
AREXIS Drug Target DiscoverybyGenome Analysis Model genome Drug
97% total 67% finished
x106 Species # of genes %known function E. coli 4.289 62 S. cerevisie 6.217 65 C. elegans 19.000 ? M. musculus 30-50.000 ≈10 H. sapiens 30-50.000 ≈15 1 Link genes to biological functions gap 0.5 time 1990 2000 1995
Bioinformatik? • Bioinformatik - det forskingsområde som behandlar och analyserar “bioinformation” • Bioinformation - den information som finns lagrad i: • genom-data (gener, genuttryck, genfunktion, etc i relation till den organism som härbärgerar genomet i fråga) • biologiska sekvenser och, • relationer mellan biologiska sekvenser, med avseende på biologiska organismers funktion (metabolism, hälsa, etc) • Bioinformatik skall ge idéer och förslag till nya våta experiment • Forskare med bioinformatik som experimentellt verktyg (in silico biologi)
Why animal models? • Genetically homogeneous • Controlled environmental influence • Large family sizes give optimal statistical power • Tools to define and characterise disease causative genes and mechanisms • In vivo validation and in vivo pharmacology • Increase productivity • Higher resolution
Research and development strategy Marketing of new products Disease models Genetic analysis Target discovery Target validation Drug discovery Clinical development Industrial partners Academic partners Arexis Arexis Integrated biology-driven discovery Comparative biology Human patient materials Medicinal chemistry Bioinformatics Biotechnology expertise Clinical science In vivo pharmacology Functional genomics
R&D project overview Exploratoryresearch Pre-clinical development Clinical development Metabolic diseases X Type 2 diabetes AMPK X Obesity Inflammatory diseases X Rheumatoid arthritis X Multiple sclerosis Skin inflammation SCCE Immunotherapy X Muc. A Prioritised projects
Business model Input to the Arexis pipeline and portfolio Revenue sources Commercialisation process Research collaborations Sub-contracts Partnerships Targeted In-licensing Target and Drug discovery Drug development/ commercialisation Target and Drug discovery Spin-off opportunities Access fees Research funding Milestone payments Royalties Early Mid Late
Board of Directors • Anders Vedin, Chairman of the Board • Professor, Senior Advisor InnovationsKapital AB • Henry Geraedts, Deputy Chairman of the Board • PhD, Independent director, 3i • Carl Christensson • CEO SEB Företagsinvest • Rikard Holmdahl • Professor of Medical inflammation, founder • Lennart Hansson • PhD, Chief Executive Officer • Leif Andersson • Professor of Animal Genetics, founder • Curt Lönnström • Chief Executive Officer of Ryda Bruk
Expression profiling Genetic approaches in silico approaches Ensembl Affymetrix aGDB experiment, and experimental data auto-annotated genomes genetic/linkage data pointers to disease loci pointers to phenotype-related genes curated gene structures database with annotated experiments relevant genes integration phenotype-related pathways Target database
Research System Architecture aGDB tools for sequence analysis Academic partners tools for expression data analysis DAS DAS DAS DAS Arexis- users Arexis- users GIM business dev economy Commercial partners vpn LDAP mail documents Arexis intranet IT System Architecture
project B AMPK project C common ancestor common ancestor common ancestor mouse homo mouse mouse homo rat homo pig ? ?
Tissue section of skeletal muscle fiber from Hampshire pigs Normal rn+/rn+ Mutant RN-/rn+ or RN-/RN- AMPK
A skeletal muscle-specific variant of AMPK g Tissue distribution of AMPK -chains AMP-activated kinase (AMPK) - a heterotrimeric enzyme g 1 g a 1 g 1 a a g 2 2 g 2 g b 3 b b 1 2 g 3 Heart Brain Placenta Lung Liver Muscle Kidney Pancreas Spleen Thyroid gland Prostate Testis Ovary Small intestine Colon Peripheral Blood AMPK
Pathways regulating glucosetransport in muscle cells AMPK AMPK Modified from Shepherd et al. NEJM 1999
genetic mapping Experimental validation chr. 5 mouse chr. 7 human Link to patophysiology? Pathway analysis!
P P P AMPK Protein Phosphatase 2C AMPKK AMPK Acetyl-CoA Carboxylase Protein Phosphatase 2A Increased glucose uptake Acetyl-CoA Carboxylase inactive Malonyl CoA Fatty acid Acetyl CoA Increased amount of GLUT4 Malonyl-CoA Decarboxylase Malonyl-CoA Decarboxylase Decreased glycogen degradation active
Pristane induced arthritis in the rat Susceptible DA rat Resistant E3 rat
position of mouse gene duplicated genomic segments mouse (1 Mbp) human (2.4 Mbp)
Genomics data Expression data integrate / analyse / visualise Reconstruction of Pathway
Drug Target NOVEL
Database resources European Bioinformatics Institute National Center for Biotechnology Information DNA Databank of Japan NCBI EBI DDBJ Pfam Blocks ProSite Swissprot MGI EMBL PubMed PIR MIPS DNA AceDB protein GenBank GDB motifs families genomes bibliography
genomic sequence • Directed / small-scale • Large-scale : BAC, YACs cDNA sequence • Directed / small-scale • Random / large-scale • Expressed Sequence Tag [EST] protein sequence • Directed, very little Where do sequences come from? DNA mRNA protein
EMBL GenBank DDBJ Sequence databasesNucleotide databases International Nucleotide Sequence Database Collaboration
Seq 1 ACGTTT Seq 3 TTCTGA Seq 2 CTAGAC Sequence databasesPrimary vs secondary databases • Primary database = sequence database • eg EMBL, GenBank, SWISSPROT • Each record describes individual sequence • Can be contain either nucleotide or protein sequences
Pattern 1 accagtgtacgactct Pattern 3 ttcgatgtcattcgatcgcatccgatcgtc Pattern 2 tacgtagctacctacctaggtagc Sequence databasesPrimary vs secondary databases • Secondary database = pattern database • eg PROSITE, PRINTS, BLOCKS, Pfam • Each record describes a set of sequences • Set can be expressed as a motif, multiple sequence alignment or probabilistic model
Sequence databasesNucleotide databases • How do the databases compare? • Three databases are 99.99% identical • Annotations can be slightly different • How often are they updated? • New release of databases every 3 months • Interim releases - EMBL-new • Can the annotations be trusted? • Not always - some estimates suggest 25% are incorrect
EST vrt mam Non-EST hum rod Sequence databasesNucleotide databases • EMBL is subdivided into EST and non-EST sequences
GenBank EMBL GenPept TrEMBL PIR SWISSPROT Sequence databasesProtein databases
EMBL • Coding sequences automatically translated TrEMBL • 558,150 entries REM SP • Sequences manually moved to SWISSPROT • 106,602 entries SWISSPROT • Because it is manually curated, annotations are reliable! Sequence databasesProtein databases • 13,700,000 entries • TrEMBL split into: • SP-TrEMBL - Sequences destined for SWISSPROT • REM-TrEMBL - Remaining sequences
Sequence databasesSummary • EMBL is main nucleotide sequence database (Europe) • TrEMBL is an automated translation of EMBL • SWISSPROT is main curated protein database • Between main releases, interim releases are made • eg EMBL-new, TrEMBL-new, SWISSPROT-new • EMBL is subdivided into EST / non-EST then by species • Annotations can be trusted in SWISSPROT, not in EMBL • Accession numbers uniquely identify a sequence and remain constant when entries are updated
Basics of sequence searchingMethods Method Accuracy Duration Example Rigorous +++++ +++++ Smith-Waterman Heuristic ++ + BLAST, FASTA Probabilistic ++++ +++ HMM • Probabilistic methods are best, but can be slow and difficult to use • Rigorous are good when used on a small subset of sequences, but too slow to search large sequence database • Heuristic methods are the best place to start
Basics of sequence searchingTerminology • Sensitivity vs Selectivity • Sensitivity searching will find weaker hits • Selectivity searching less likely to find unrelated hits • Increased sensitivity means more true positives • Increased selectivity means fewer false positives
Query sequence Find identical stretches of nucleotides in two sequences Sequence in database HSP Extend regions of similarity as far as possible HSP1 HSP 2 Identify all regions of similarity Searching with BLASTHow it works
Local vs global comparisonsThe nature of proteins • Proteins consist of functional and structural units - domains
Global comparison attempts to match all of one sequence against another Local comparison attempts to match short stretches of one sequence with another Local vs global comparisonsWhat is a local and global comparison?
Local vs global comparisonsWhen should each technique be used? • Global comparisons • Closely related sequences • Same general structure of sequence • Roughly equal lengths • Local comparisons • Sequences not closely related • Sequence fragments • Interested in identifying common domains






















