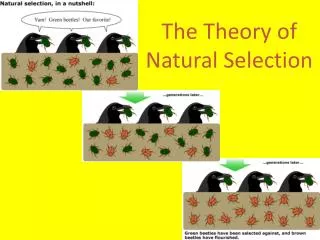
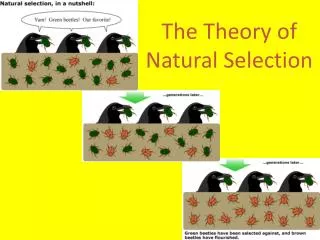
Download

1 / 23
240 likes | 260 Views
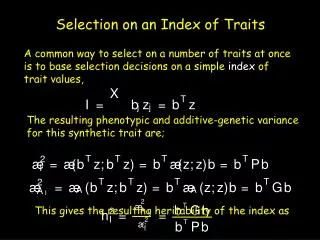
A few Simple Applications of Index Selection Theory. Focus is on using multiple sources ff information to improve a single trait. In this case, the vector of weights has a simple form and Ga simplifies to the the vector g 1 of genetic covariances of all traits with trait 1.

E N D
A few Simple Applications of Index Selection Theory Focus is on using multiple sources ff information to improve a single trait
In this case, the vector of weights has a simple form and Ga simplifies to the the vector g1 of genetic covariances of all traits with trait 1 We measure n traits, but our goal is to improve the response of trait one only. Hence, the Smith-Hazel weights and resulting index are just (using g to denote g1)
The expected response using this index is The expected increase in response over mass selection The increase in accuracy in predicting BV using the index vs. phenotype alone
Here, the repeatability r = Smith-Hazel weights become Application: Repeated records Model: repeated measures on an individual include their common genetic variance plus a common permanent environmental effect,
Accuracy Response
Accuracy Response Indices with information from relatives With n traits, need to estimate (n+1)(n+4)/2 parameters. With relatives only need trait variance components We can express g and P in terms of correlations,
Index Improve of response Simple case: Individual + one relative
Within-family selection: selection on (z - zf) Between-family selection: selection zf Combined Selection of both individual and family information Individual selection: selection on z Note that individual selection places equal weight on within- and between-family components What is the optimal allocation of selection?
In an index-selection framework, we can phrase this as the amount b1 of within- family vs. the amount of between-family selection b2. Equivalently, we can express this as the relative weights on individual (b1) vs. family (b2 - b1) selection
Let t denote the phenotypic correlations among sibs in an infinite population: With n sibs in a family, the finite-size corrections are Likewise, the rA = 1/2 (FS), 1/4 (HS) denote the genetic correlation.
The resulting weights become The Lush index Lush (1947) applied the Smith-Hazel index to this problem. Here, the two traits are an individual’s value and their family mean.
The resulting index can be expressed as either the weights on within vs. between family components, Or on individual vs. family selection, Improvement of Response:
Relative weight on between-family vs. within- family selection under Lush Index
Under general weighting of individual vs. family or within- vs. -between family Response under general combined selection
MAS - Marker Assisted Selection One very popular application of index selection is MAS, or marker assisted selection. The idea to use genetic markers to improve selection is not new, going back to Neimann-Sorensen and Robertson (1961) and Smith (1967). We now have a very rich set of dense molecular markers and so can actually apply some of the theory, developed by Smith (1967) for single markers and by Lande and Thompson (1990) for n markers Idea: we have k molecular markers that show marker- trait associations. Define a marker score m = Siaimi
- ) µ ∂ µ ∂ ( ( ) - 2 1 ° Ω 1 ° h T ° 1 T 2 - - I = b z = g P z = h ¢ z + ¢ m µ ∂ ) ( s - s 2 2 1 ° h Ω 1 ° h Ω 2 1 ° h I = z + ¢ m * s 2 h (1 ° Ω ) s 2 2 R (1 ° h ) Ω = æ h ¢ 1 + A 2 2 i h (1 ° h Ω ) We wish to construct a Smith-Hazel index to maximize response in a trait given trait value z and the marker score m for an individual. That is, we wish to find the weights b for I = b1z + b2m that maximize response. The result weights can be found to be (see notes) which reduces to Where r= fraction of s2A accounted for by the marker score m The resulting response becomes