Download

1 / 42

E N D
1. 1 Extract, Transform and Load Lecture 2
2. 2 Objectives Describe the key design considerations for transformation and load
Describe a recommended process for designing and coding and testing the ETL process.
4. 4 Data Engineering Considerations for Design
Standardization
Cleaning
Denormalization
Data mapping and type conversion
Derivation
Aggregation(s)
Integration � assigning surrogate keys
Managing Slowly Changing Dimensions
Audit
Loading
5. 5 Standardization Often, data extracted from the source system needs to be cleaned and standardized. Best way to understand is through some examples
Standardization:
Consider the following names:
Bob Jones
Rob Jones
Bobby Jones
Robert Jones
These can all be standardized as Robert Jones
6. 6 Standardization Consider the following addresses:
These should be standardized as:
123 Main, Antigonish, Nova Scotia, B2G 2A1
7. 7 Standardization Standardization is a key step in the process of integrating data.
Using the previous example, assume we get a customer record from 2 different sources.
8. 8 Standardization In the previous example, it is probably safe to assume that the individual referenced and is in fact the same person
As such, we would only want one record for this individual in our data warehouse
Assuming we use different primary keys in each system (a pretty safe assumption) we would need to match on name and address to determine that this is the same person
Standardization of name and address will give us the ability to match the individual records from multiple systems and integrate into a single customer record
9. 9 Cleaning Cleaning is a process used to remove unwanted �noise� from data and to make data more presentable
Consider the following shipping address:
Address 1: 123 Main * deliver to rear entrance *
City: Antigonish
Postal Code: B2G 2A1
Province: NS
Cleaning process would remove the * comment * in the address field
10. 10 Cleaning Consider the following name:
BOB JONES
Many tools provide a �nice name� function that will turn above into: Bob Jones
Consider the following phone number:
9028630440
Many tools provide the ability to turn this into: (902) 863-0440
11. 11 Cleaning Disney example:
Disney provided kiosks in Epcot that allowed visitors to sign up to receive information regarding Disney vacations (great marketing tool)
Got a high % of bogus sign ups, like:
Goofy, 123 Main St
Mickey Mouse, etc.
Built rules (using a tool) to exclude these records from DW)
Also, obscenity checking was done and records eliminated
12. 12 Cleaning and standardization tools Required primarily for cleaning and standardizing the customer and to a lesser extent the product dimension.
Provide lots of functionality for cleaning and standardizing names and addresses
Key functionality: the ability to match records based on very sophisticated heuristic rules
Provide users the ability to define own rules
Allow matching on a percentage match or score � users define what constitutes a match � 80%, 90%, 100%?
13. 13 Cleaning and Standardization tools Example of advanced functionality for business name/address matching
Are the following companies in fact the same company?
Cleaning and standardization tools provide the ability to find that A=B and B=C so A=B=C
14. 14 Cleaning and Standardization Vendors Leading Vendors:
Id Centric from FirstLogic
Trillium from Harte Hanks
Code 1 from Group 1 software
IDR from Vality
Typical cost of software: $250,000 US and up
15. 15 Denormalization Denormalization is the process of �flattening� dimension and fact tables from multiple tables to (in most cases) a single table.
Consider the following order (fact) data from a production system
16. 16 Denormalization - Dimensions Consider the employee to branch relationship
We would probably denormalize that into something like a �location� dimension
17. 17 Derivation We often need to derive data items. Simple example is for measures on fact table. Consider the order fact:
18. 18 Derivation - Households More complex example.
Often, marketers are interesting in understanding the households that customers live in and the relationships that exist (husband, wife, kids, etc.). Typically, this information is not available from any source system and needs to be derived.
Household may have more than 1 addresses (if for example, a family has a permanent and summer address
19. 19 Derivation � Household example Typically, household derivation is done using cleaning/standardization tools like id centric and Trillium.
These tools look to match individuals into households based on standardized names and addresses
Examples:
20. 20 Derivation - examples
21. 21 Derivation � Households - Conclusions Deriving households can be tricky and organizations tend to be pretty conservative in their approach
Don�t want to assume a relationship that does not exist � may be offensive
Balanced with the desire not to (for example) make the same marketing offer (for credit cards, as example) multiple times to the same household
22. 22 Aggregation Often, we need to generate aggregated fact data for 2 main reasons:
Speed up queries
Generate �snapshot� facts
Speed up query processing.
The DBA is continuously monitoring the the performance of queries and will create aggregate fact when atomic facts are often rolled up a certain way
The most common rollup: date.
Assuming we keep atomic fact data, it is very common that we want to do analysis of orders by a time period such as week and month.
If we build aggregate fact tables, these can be used in place of atomic level facts and speed query processing as they contain many fewer records.
23. 23 Aggregation Speed up queries
Note that aggregate fact tables retain reference to other dimension tables
Many query tools are �aggregate aware�. This means that they can detect when an aggregate table exists for a fact and automatically select that table in query. This is transparent to the user
Snapshot facts
As discussed in a previous lecture, organizations typically want both a transactional and snapshot view of data.
Generation of snapshot facts requires a significant amount of aggregation of data.
24. 24 Aggregation When calculating aggregates, the following is typically true. Assume we are building an aggregate order fact where we want products ordered by customer by location by month.
The data for the current month would not be available until the end of the month
The FKs to other relevant dimensions are the same as the atomic level fact
The FK to the date dimension needs to be to a month, not a day. To achieve this, we need to specify �levels� in the date dimension so that each unique month has its own unique key. So, in the date dimension, we have records that represent unique days 3/19/02 AND unique months 3/02. Makes things more complex for users.
25. 25 Data Mapping and Type conversions Need to implement logic to choose values to map into fields (e.g., different gender codes from systems)
Need to implement IF � THEN - ELSE (or CASE) logic to determine how individual fields will be populated.
Often need to convert data types from one form to another
Example: date field stored in a CHAR field, convert to DATE.
Example: time of day stored as part of date � parse out and store as integer
ETL tools are really good at mapping and converting from one data type to another
26. 26 Surrogate Key Processing Design needs to consider two aspects of surrogate key processing:
Assigning and maintaining the keys associated with dimension records
Assigning surrogate keys to fact records
27. 27 Surrogate Keys For a given dimension table, the initial set up involves two steps:
Create a �sequence� that will provide the surrogate keys to the dimension table. The sequence generates a sequential set of integers that will be assigned to each row in the dimension table
Create a �key map� table that will map product key(s) to the surrogate key assigned.
28. 28 Surrogate keys � Key Map table Assume we have products coming from 2 systems and there is overlap in the products in the systems
Assume we have a method to tell us X2334R is the same as STDHMMR
29. 29 Surrogate Keys � key map table The role of the key map table is to create and maintain a record of the production key(s) that map to the surrogate key assigned to a given dimension row.
Simple Format, using previous example:
30. 30 Surrogate Key assignment Surrogate key assignment is a two step process:
Manage assignment of keys to dimension records as primary keys
Manage assignment of surrogate keys to fact records
Key map table is critical to this process as a lookup table
31. 31 Surrogate Key Assignment Process - Dimensions
32. 32 Surrogate key assignment - facts
33. 33 Slowly changing dimensions We need to build the logic for processing slowly changing dimensions, and this can be challenging.
Note that for a complex dimension like customer, depending on the type of change, we may implement multiple change strategies, depending on what data is changing!!
Type 1
Type 2
Type 3
Demographics
34. 34 Audit As with extract, its important to build audit and error handling logic into the process
35. 35 Load Process Always use the bulk loader for ALL inserts � even those from within a database
Most DBMS� provide a bulk loader function
Basically, the bulk loader provides the ability to load data more quickly as it takes a number of shortcuts
For example, the bulk loader does not insert records into recovery log on a record by record basis.
Presort what is to be loaded by primary key.
DBMS provides capabilitiies
Can also purchase tools like SynchSort which sorts data very quickly.
36. 36 Load Process Many DBMS� allow simple transformations (e.g., aggregation of data) during load process
Rule of thumb: stay away from any transformations using load facilities
Index management � need to determine whether or not to drop the index(es) on a table before load, then rebuild
Rule of thumb: If loading more than 10% of table, drop and recreate
Parallel capabilities of DBMS, OS and hardware to do as much processing simultaneously as possible.
37. 37 Design Process Overview Step 1. Environment Setup
Test, choose, and implement tools
- ETL
- Cleaning/Standardization
- Sort utilities
- Code management
- Metadata
Define documentation standards
Ensure all design documentation is saved as metadata
38. 38 Design Process Overview Step 2. High-Level Plan
Create a very high-level, one-page schematic of the source-to-target flow
Identify starting and ending points
Label known data sources
Label targets
Include notes about known gotchas
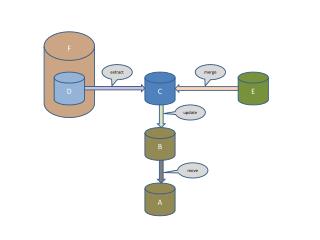
39. 39 Example � Process Overview
40. 40 Design Process Overview Step 3. Detailed Design
Drill down by target table or logical group of target tables, graphically sketching any complex data restructuring or transformations
Graphically illustrate the surrogate-key generation process
Develop a preliminary job sequencing
41. 41 Design Process Overview Step 4: Design ETL for a simple dimension
Start with static extract transform and load
Step 5: Add change logic for dimension
Design and implement the logic required for incremental extract and processing
Design and implement logic to manage slowly changing dimensions
Step 6: Design ETL for initial (historical) load of facts
Step 7: Design ETL for incremental ETL of facts
�Tune� fact table load to take advantage of parallelism, bulk load, etc.
42. 42 Design Process Overview Step 8: Design and build process for aggregates and for moving data from data warehouse to data marts:
Special consideration required for design of MDDB-based marts
Step 9: Build ETL automation, including:
Job scheduling
Statistics generation
Error handling