Download

1 / 16
160 likes | 462 Views
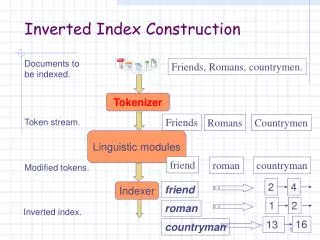
Index construction. Chap. 4. Manning et al., Introduction to Information Retrieval. Contents. Hardware basics. IR 시스템 구축을 위해 생각해 볼 하드웨어 고려사항 우리는 가급적 더 많은 데이터를 메모리에 두기를 원한다 . 특히 , 빈번히 접근하는 데이터의 경우 더욱 더 그렇다 . 이런 데이터를 메모리상에 관리하는 기술을 caching 이라 부른다 . 메모리의 데이터 가져오기 : 5×10 -9 초

E N D
Index construction Chap. 4 Manning et al., Introduction to Information Retrieval
Hardware basics • IR 시스템 구축을 위해 생각해 볼 하드웨어 고려사항 • 우리는 가급적 더 많은 데이터를 메모리에 두기를 원한다. 특히, 빈번히 접근하는 데이터의 경우 더욱 더 그렇다. 이런데이터를 메모리상에 관리하는 기술을 caching이라 부른다. • 메모리의 데이터 가져오기: 5×10-9초 • 디스크의 데이터 가져오기: 2×10-8 초 • Extraction of textual parts from document • 디스크의 데이터를 가져올 때는, 디스크상에 물리적으로 모여 있는 경우 데이터 전송 소요시간을 줄일 수 있다. • OS는 Block 단위로데이터를 쓰고 가져온다. 이런 블록 데이터가 저장되는 주메모리 영역을 buffer라 부른다. • 압축기술의 적절한 활용은, 데이터를 읽는 데에 소요되는 시간을 줄인다. • IR 시스템을 가동시키는 서버는 대체로 수~수십 GB 단위의 주메모리를 갖는다.
Hardware basics Typical system parameters in 2007
Blocked sort-based indexing • BSBI • Indexing 기본 과정 • 입력자료: Term-docID pair • Sorting • dominant key: term • Secondary key: docID • 각 term 들에 대한 postings list 구성 • Term – Term ID mapping • Postings list구성시term 대신 unique한 term id를 사용 • Term – term ID mapping 정보 생성 관리 • External sorting algorithm: collection의 크기가 너무 커서 메인메모리가 부족할 때 활용 • Blocked sort-based indexing • 컬렉션을 같은 크기의 segment들로 분할 • 메모리 각 부분 속에서 TermID-DocID쌍을 sort • 중간단계 sorting 결과 디스크에 저장 • 중간단계 결과를 합쳐(merge) 최종 index 구성
Blocked sort-based indexing • 효율적인 BSBI를 위한 고려사항 • 메모리상에서 sorting 작업을 효과적으로 할 수 있도록 메모리 영역 확보 • Inversion • Step 1: sorting • TermID-DocID형태 데이터를 sort • Step 2: Postings list 작성 • TermID-DocID자료에서 Term이DocumentIDnode들과 연결돼 있는 linked list 형태 BSBIndexConstruction() 1 n←0 2 while (all documents have not been processed) 3 do n←n+1 4 block←ParseNextBlock() 5 BSBI-Invert(block) 6 WriteBlockToDisk(block, fn) MergeBlocks(f1, ..., fn; fmerged) f: file
Block sorted-base indexing • Reuter-RCV1 collection을 indexing할 경우의 예제 • 10개의 block으로 분할하여 processing, 각 파일에 저장 • 10개의 결과 파일을 merge • Priority queue를 활용하여 우선순위에따른 프로세싱 • BSBI의 비용 • Timecomplexity: Θ(T logT) • 실제 indexing time은 parsing 소요시간과 final merge 소요시간에 좌우됨
Single-pass in-memory indexing • BSBI의 단점 • Term과 termID를 연관짓기 위한 자료구조가필요 • 대형 컬렉션 처리에는 부적합 • 대안으로서의 SPIMI • TermID대신에 Term 사용 • Block별로 dictionary 작성해 disk에 저장 • 새 block에서 새 dictionary 시작 SPIMI-Invert(token_stream) 1 output_file = NEWFILE() 2 dictionary = NEWHASH() 3 while (free memory available) 4 do token ←next(token_stream) 5 if term(token) ∉ dictionary 6 thenpostings_list = AddToDictionary(dictionary, term(token)) 7 elsepostings_list = GetPolstingsList(dictionary, term(token)) 8 if full(postings_list) 9 thenpolstings_list = DoublePostingsList(dictionary, term(token)) 10 AddToPostingsList(PostingsLst, docID(token)) 11 sorted_terms←SortTerms(dictionary) 12 WriteBlockToDisk(sorted_terms, dictionary, output_file) 13 returnoutput_file
Single-pass in-memory indexing • SPIMI의장점 • BSBI가 처음에 모든 term-docID를 망라해 sort했던 것과 달리 SPIMI는 term-DocID를 하나씩 읽어 Postings list에 직접 저장한다. • Sorting할 필요 없으므로 빠르다. • Postings list가 속하는 어휘를 추적하므로 termID를 필요로 하지 않는다. • Postings list 크기 초기값 설정 • 최초에 postings list 크기의 기본값을 설정해 두고, 이 크기를 넘게 정보가 발생하면 2배 확대함 • 메모리 낭비 발생 • TermID를 사용하는 BSMI보다 효율적 • Last step • 각 block 단위로 생성된 inverted index 합치기 • Compression후 disk 저장하면 더 효율적 • Time complexity • Θ(T): sorting이 필요하지 않기 때문
Distributed indexing • Indexing large collection like web… • 한 대의 컴퓨터로 indexing되지 않는 경우, 분산 인덱싱(distributed indexing) 알고리즘적용 • MapReduce • 일반적으로사용되는 분산 시스템 아키텍쳐 • 소규모 저사양 컴퓨터들에 연산을 분산시키는 방법으로 Computing problem을해결 • Master node의 역할 • Assign • Reassign: 특정 컴퓨터 작동오류에 대비 • Splitting • 대규모 연산작업을 개별 key-value 쌍의 처리로 분할(termID, docID) • 빈발하는 term에 대해서는 공통의 termID를생성해 모든 node가 공유 • 빈발하지 않는 term의 경우 ID 대신 term 직접 사용 • Map phase • 분할된 input data를 key-value 쌍에 mapping시키는 작업으로 구성 • Parsing task • 각 parser는 자신의 연산결과를 segment file에 포함해자신의 local disk에 저장
Distributed indexing • Reduce phase • Key를 j term partition으로 분할하고, 각 parser가 각 term partition에 대한 key-value 쌍을 segment file에 저장하게 함 • Inverter의 역할: 특정 key에 대한 모든 value를 하나의 list로 통합함 • 각 term 에 대해서 취합된 value들을 sort • 최종 postings list 생성 • 각 inverter는 segment file들이 저장된 machine과 저장된 주소들을 전달받아 data에 access
Dynamic indexing • Dynamic collections • 대부분의 collection들은 dynamic하다. • 예외: 성경, 셰익스피어 전집, … • 새로운 문서의 추가, 기존문서 제거 • 정기적으로 index 갱신? → 비효율적 • Auxiliary index • 두 개의 index 사용 • Main index: 디스크에저장 • Auxiliary index: 추가 또는 제외될 문서 정보 포함, 메모리에 저장 • 두 개의 index를 활용한 search 결과를 합쳐 최종결과 도출 • Auxiliary index가 일정 크기 이상으로 커지면 main index에 합침 • Time complexity • Θ(T2/n) • T: term 전체 개수, n: Auxiliary index의 length • Auxiliary index가 꽉 찼을 때 기존 index에 대한 merge가 발생하므로, T/n회의 merge 발생
Dynamic indexing • Logarithmic merging to lower cost • Θ(T * log2(T/n))으로만들기 • Index size 조정(not constant): • Indexes: I0, I1, I2, ... • Index size들: 20×n, 21×n, 22×n, … • 필요한 index 개수는 log2(T/n)개 LMergeAddToken(indexes, Z0, token) 1 Z0←Merge(Z0, {token}) 2 if |Z0| = n 3 then for i←0 to ∞ 4 do if Ii∈ indexes 5 then Zi+1←Merge(Ii, Zi) 6 (Zi+1 is a temporary index on disk) 7 indexes←indexes-{Ii} 8 else Ii ←Zi (Zi becomes the permanent index Ii) 9 indexes←indexes∪{Ii} 10 Break 11 Z0← ∅
Other types of indexes • Ranked retrieval에서의 문제 • Sorting order • Boolean retrieval과 달리 ranked retrieval에서는 DocID순서가 아니라 weight와 같은 impact 순서대로 sorting돼야 하는 경우 있다. • 새로운 문서가 추가될 때 • 문서순서 ordering: 맨 마지막에 추가 • Impact ordering: Impact 값에 따라 적정한 위치에 삽입, index update가 더 복잡 • Security • Access control list • 각 user별 접근권한 있는 문서와 없는 문서의 postings list 구성