Download

1 / 20
230 likes | 666 Views
Natural Gradient Works Efficiently in Learning S Amari. 11.03.18.(Fri) Computational Modeling of Intelligence Summarized by Joon Shik Kim. Abstract. The ordinary gradient of a function does not represent its steepest direction, but the natural gradient does.

E N D
Natural Gradient Works Efficiently in LearningS Amari 11.03.18.(Fri) Computational Modeling of Intelligence Summarized by JoonShik Kim
Abstract • The ordinary gradient of a function does not represent its steepest direction, but the natural gradient does. • The dynamical behavior of natural gradient online learning is analyzed and is proved to be Fisher efficient. • The plateau phenomenon, which appears in the backpropagation learning algorithm of multilayer perceptron, might disappear or might not be so serious when the natural gradient is used.
Introduction (1/2) • The stochastic gradient method is a popular learning method in the general nonlinear optimization framework. • The parameter space is not Euclidean but has a Riemannian metric structure in many cases. • In these cases, the ordinary gradient does not give the steepest direction of target function.
Introduction (2/2) • Barkai, Seung, and Sompolisky (1995) proposed an adaptive method of adjusting the learning rate. We generalize their idea and evaluate its performance based on the Riemannian metric of errors.
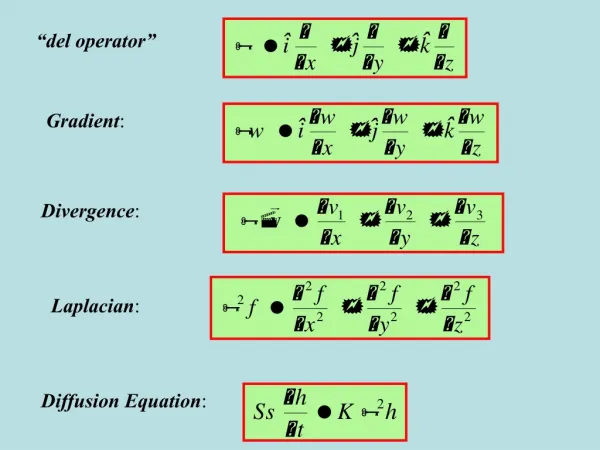
Natural Gradient (1/5) • The squared length of a small incremental vector dw, • When the coordinate system is nonorthogonal, the squared length is given by the quadratic form,
Natural Gradient (2/5) • The steepest descent direction of a function L(w) at w is defined by the vector dwhas that minimizes L(w+dw) where |dw| has a fixed length, that is, under the constant,
Natural Gradient (3/5) • The steepest descent direction of L(w) in a Riemannian space is given by,
Natural Gradient Learning • Risk function or average loss, • Learning is a procedure to search for the optimal w* that minimizes L(w). • Stochastic gradient descent learning
Statistical Estimation of Probability Density Function (1/2) • In the case of statistical estimation, we assume a statistical model {p(z,w)}, and the problem is to obtain the probability distribution that approximates the unknown density function q(z) in the best way. • Loss function is
Statistical Estimation of Probability Density Function (2/2) • The expected loss is then given by Hz is the entropy of q(z) not depending on w. • Riemannian metric is Fisher information
Fisher Information as the Metric of Kullback-Leibler Divergence (1/2) • p=q(θ+h)
Fisher Information as the Metric of Kullback-LeiblerDivergence (2/2) I: Fisher information
Multilayer Neural Network (2/2) c is a normalizing constant
Natural Gradient Gives Fisher-Efficient Online Learning Algorithms (1/4) • DT = {(x1,y1),…,(xT,yT)} is T-independent input-output examples generated by the teacher network having parameter w*. • Minimizing the log loss over the training data DT is to obtain that minimizes the training error
Natural Gradient Gives Fisher-Efficient Online Learning Algorithms (2/4) • The Cramér-Rao theorem states that the expected squared error of an unbiased estimator satisfies • An estimator is said to be efficient or Fisher efficient when it satisfies above equation.
Natural Gradient Gives Fisher-Efficient Online Learning Algorithms (3/4) • Theorem 2. The natural gradient online estimator is Fisher efficient. • Proof
Natural Gradient Gives Fisher-Efficient Online Learning Algorithms (4/4)