Download
1 / 1
10 likes | 60 Views
Explore the learning mechanism of word referents through a fast mapping procedure that locks into word meanings with confirming evidence, rather than statistical inference. The study delves into the adaptive hypothesis and memory challenges during word learning.

E N D
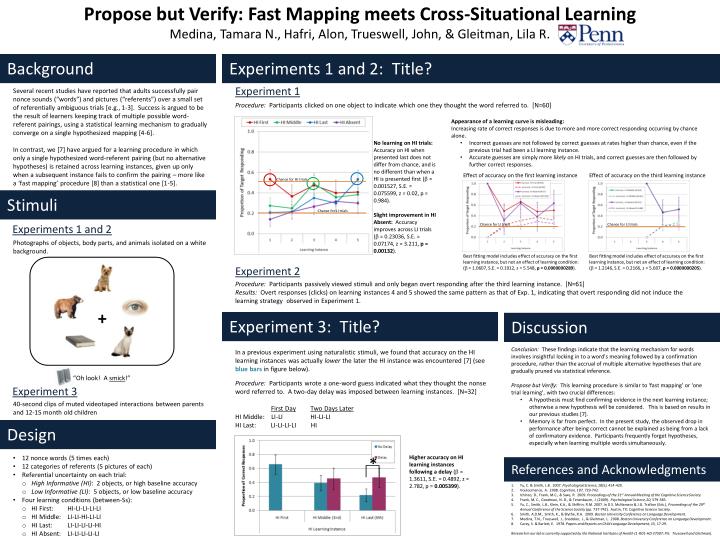
Background Experiments 1 and 2: Title? Experiment 1 Several recent studies have reported that adults successfully pair nonce sounds (“words”) and pictures (“referents”) over a small set of referentially ambiguous trials [e.g., 1-3]. Success is argued to be the result of learners keeping track of multiple possible word-referent pairings, using a statistical learning mechanism to gradually converge on a single hypothesized mapping [4-6]. In contrast, we [7] have argued for a learning procedure in which only a single hypothesized word-referent pairing (but no alternative hypotheses) is retained across learning instances, given up only when a subsequent instance fails to confirm the pairing – more like a ‘fast mapping’ procedure [8] than a statistical one [1-5]. Procedure: Participants clicked on one object to indicate which one they thought the word referred to. [N=60] • Appearance of a learning curve is misleading: • Increasing rate of correct responses is due to more and more correct responding occurring by chance alone. • Incorrect guesses are not followed by correct guesses at rates higher than chance, even if the previous trial had been a LI learning instance. • Accurate guesses are simply more likely on HI trials, and correct guesses are then followed by further correct responses. • No learning on HI trials: Accuracy on HI when presented last does not differ from chance, and is no different than when a HI is presented first ( = 0.001527, S.E. = 0.075599, z = 0.02, p = 0.984). • Slight improvement in HI Absent: Accuracy improves across LI trials ( = 0.23036, S.E. = 0.07174, z = 3.211, p = 0.00132). Propose but Verify: Fast Mapping meets Cross-Situational LearningMedina, Tamara N., Hafri, Alon, Trueswell, John, & Gleitman, Lila R. Effect of accuracy on the first learning instance Effect of accuracy on the third learning instance Chance for HI trials Stimuli Chance for LI trials Experiments 1 and 2 Chance for LI trials Chance for LI trials Photographs of objects, body parts, and animals isolated on a white background. Best fitting model includes effect of accuracy on the first learning instance, but not an effect of learning condition: ( = 1.0607, S.E. = 0.1912, z = 5.548, p = 0.0000000289). Best fitting model includes effect of accuracy on the first learning instance, but not an effect of learning condition: ( = 1.2146, S.E. = 0.2166, z = 5.607, p = 0.0000000205). Experiment 2 Procedure: Participants passively viewed stimuli and only began overt responding after the third learning instance. [N=61] Results: Overt responses (clicks) on learning instances 4 and 5 showed the same pattern as that of Exp. 1, indicating that overt responding did not induce the learning strategy observed in Experiment 1. Experiment 3: Title? Discussion + • Conclusion: These findings indicate that the learning mechanism for words involves insightful locking in to a word’s meaning followed by a confirmation procedure, rather than the accrual of multiple alternative hypotheses that are gradually pruned via statistical inference. • Propose but Verify: This learning procedure is similar to ‘fast mapping’ or ‘one trial learning’, with two crucial differences: • A hypothesis must find confirming evidence in the next learning instance; otherwise a new hypothesis will be considered. This is based on results in our previous studies [7]. • Memory is far from perfect. In the present study, the observed drop in performance after being correct cannot be explained as being from a lack of confirmatory evidence. Participants frequently forget hypotheses, especially when learning multiple words simultaneously. In a previous experiment using naturalistic stimuli, we found that accuracy on the HI learning instances was actually lower the later the HI instance was encountered [7] (see blue bars in figure below). “Oh look! A smick!” Procedure: Participants wrote a one-word guess indicated what they thought the nonse word referred to. A two-day delay was imposed between learning instances. [N=32] First DayTwo Days Later HI Middle: LI-LI HI-LI-LI HI Last: LI-LI-LI-LI HI Experiment 3 40-second clips of muted videotaped interactions between parents and 12-15 month old children Design * • 12 nonce words (5 times each) • 12 categories of referents (5 pictures of each) • Referential uncertainty on each trial: • High Informative (HI): 2 objects, or high baseline accuracy • Low Informative (LI): 5 objects, or low baseline accuracy • Four learning conditions (between-Ss): • HI First: HI-LI-LI-LI-LI • HI Middle: LI-LI-HI-LI-LI • HI Last: LI-LI-LI-LI-HI • HI Absent: LI-LI-LI-LI-LI Higher accuracy on HI learning instances following a delay ( = 1.3611, S.E. = 0.4892, z = 2.782, p = 0.005399). References and Acknowledgments Yu, C. & Smith, L.B. 2007. Psychological Science, 18(5), 414-420. Vouloumanos, A. 2008. Cognition, 107, 729-742. Ichinco, D., Frank, M.C., & Saxe, R. 2009. Proceedings of the 31st Annual Meeting of the Cognitive Science Society. Frank, M. C., Goodman, N. D., & Tenenbaum, J. (2009). Psychological Science, 20, 579-585. Yu, C., Smith, L.B., Klein, K.A., & Shiffrin, R.M. 2007. In D.S. McNamara & J.G. Trafton (Eds.), Proceedings of the 29th Annual Conference of the Science Society (pp. 737-742). Austin, TX: Cognitive Science Society. Smith, A.D.M., Smith, K., & Blythe, R.A. 2009. Boston University Conference on Language Development. Medina, T.N., Trueswell, J., Snedeker, J., & Gleitman, L. 2008. Boston University Conference on Language Development. Carey, S. & Barlett, E. 1978. Papers and Reports on Child Language Development, 15, 17-29. Research in our lab is currently supported by the National Institutes of Health (1-RO1-HD 37507; PIs: Trueswell and Gleitman).