Download
1 / 28
300 likes | 657 Views
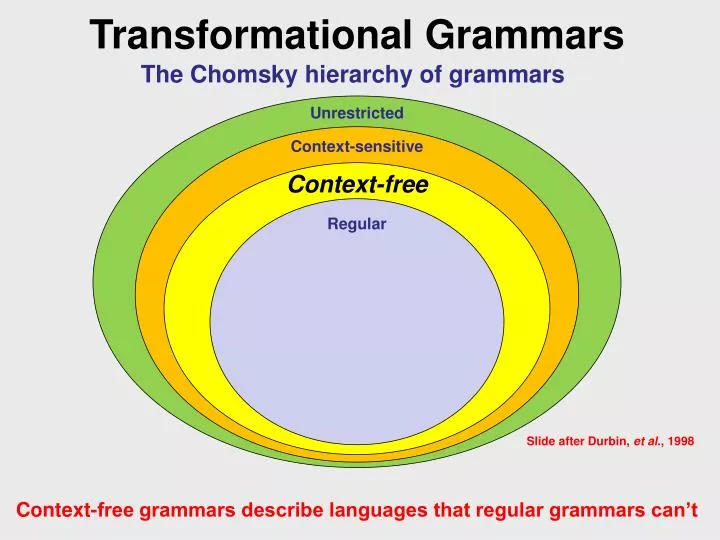
Transformational Grammars. The Chomsky hierarchy of grammars . Unrestricted. Context-sensitive. Context-free. Regular. Slide after Durbin, et al ., 1998. Context-free grammars describe languages that regular grammars can’t . Limitations of Regular Grammars.

E N D
Transformational Grammars The Chomsky hierarchy of grammars Unrestricted Context-sensitive Context-free Regular Slide after Durbin, et al., 1998 Context-free grammars describe languages that regular grammars can’t
Limitations of Regular Grammars Regular grammars can’t describe languages where there are long-distance interactions between the symbols! two classic examples are palindrome and copy languages: Regular language: a b a aa b Palindrome language: a a b b a a Copy language: a a b a a b Illustration after Durbin, et al., 1998 Yes, OK. Regular grammars can produce palindromes. But you can’t design one that produces only palindromes!
Context-Free Grammars Symbols and Productions (A.K.A “rewriting rules”) Like regular grammars are defined by their set of symbols and the production rules for manipulating strings consisting of those symbols • There are still only two types of symbols: • Terminals (generically represented as “a”) • these actually appear in the final observed string (so imagine nucleotide or amino acid symbols) • Non-terminals (generically represented as “W”) • abstract symbols – easiest to see how they are used through example. The start state (usually shown as “S”) is a commonly used non-terminal The difference arises from the allowable types of production
Context-free Grammars Symbols and Productions (A.K.A “rewriting rules”) The left-hand side must still be just a non-terminal, but the right-hand side can be any combination of terminals and non-terminals W→aW W→abWa W→abW W→WW W→aWa W→aWb W→aabb W→e These are just examples of some possible valid productions
Context-free Grammars Symbols and Productions (A.K.A “rewriting rules”) Here’s the minimal CFG that produces palindromes: S→aSa S→bSb S→aa S→ bb W = {S = “Start”} a = {a,b} As before, we start with S then repeatedly choose any of the valid productions, with the non-terminal S being replaced each time by the string on the right hand side of the production we’ve chosen…
Context-free Grammars Symbols and Productions (A.K.A “rewriting rules”) Here’s the minimal CFG that produces palindromes: S→aSa|bSb|aa|bb Or, with an explicit end state: S→aSa|bSb|e W = {S = “Start”} a = {a,b,e} Here’s one possible sequence of productions: S ⇒ aSa⇒ aaSaa⇒ aabSbaa⇒ aabaabaa Note that the sequence now grows from outside in, rather than from left to right!!
A CFG for RNA stem-loops Seq1 Seq2 Seq3 A A C A C A G A G A G A G•C U•A GxC A•U C•G CxU C•G G•C GxG Seq1 C A G G A AA C U G Seq2 G C U G C A AA G C Figure after Durbin, et al., 1998 RNA secondary structure imposes nested pairwise constraints similar to those of a palindrome language
A CFG for RNA stem-loops Seq1 Seq2 Seq3 A A C A C A G A G A G A G•C U•A GxC A•U C•G CxU C•G G•C GxG Seq3 G C G G C A A C U G Figure after Durbin, et al., 1998 Sequences that violate the constraints would be rejected
A CFG for RNA stem-loops Seq1 Seq2 Seq3 A A C A C A G A G A G A G•C U•A GxC A•U C•G CxU C•G G•C GxG S→ aW1u | cW1g| gW1c | uW1a W1→aW2u | cW2g| gW2c | uW2a W2→aW3u | cW3g| gW3c | uW3a W3→gaaa | gcaa W = {S = “Start”, W1, W2, W3} a = {a,c,g,u} A context-free grammar specifying stem loops with a three base-pair stem and either a GAAA or GCAA loop
Context-free grammars are parsed with push-down automata Grammar Parsing automaton Regular grammar Context-free grammar Context-sensitive grammar Unrestricted grammar Finite State automaton Push-down automaton Linear bounded automaton Turing machine Proviso: Push-down automata generally only practical with deterministic CFG!! The PDA faces a combinatorial explosion if confronted with a non-deterministic CGF with non-trivial problem size… but we can brute-force small N
A Push-Down Automaton An RNA stem-loop considered as a sequence of states? e S W1 W2 W3 S→ aW1u | cW1g| gW1c | uW1a W1→aW2u | cW2g| gW2c | uW2a W2→aW3u | cW3g| gW3c | uW3a W3→gaaa | gcaa The regular grammar / finite state automaton paradigm will not work!!
Push-Down Automaton Parse trees are the most useful way to depict PDA S→ aW1u | cW1g| gW1c | uW1a W1→aW2u | cW2g| gW2c | uW2a W2→aW3u | cW3g| gW3c | uW3a W3→gaaa | gcaa S W1 W2 W3 • G C C G C A A G G C This depiction suggests a stack based method for parsing…
Python focus – stacks Python lists have handy stack-like methods! myStack = [] # creates an empty list myStack.append(someObject) # “push” otherObject = myStack.pop() # “pop” Remember, the stack is a “First-In, Last-Out” (FILO) data structure How is FILO relevant to context-free grammars?
Errors of various sorts each have their own internal error type. These are objects too! Python focus – stacks Python exception handling may be convenient: try: otherObject = myStack.pop() # “pop” exceptindexError: # means myStack was empty! # accepting the input sequence return self.return_string We’ll introduce exception handling on an “as-needed” basis, but it is a very powerful and useful feature of Python
For non-deterministic, we need to consider each possible production! Algorithm for PDA parsing Initialization: • Set cur_position in sequence under test (“input sequence”) to zero • Push the start state “S” onto the stack • Pop a symbol off the stack • stack empty? Accept!! Return string • Is the symbol from the stack a terminal or non-terminal? • Terminal? • stack symbol matches symbol at cur_position? • Yes! – accept symbol and increment cur_position • No? – reject sequence, return False • Non-terminal? • Does symbol at cur_position + 1 have a valid production? • No? – reject sequence, return False • Yes! Push right side of production onto stack, rightmost symbols first Iteration:
PDA parsing – an example Input string: • GCCGCAAGGC Stack: • S Valid production: • S→gW1c
PDA parsing – an example Input string: • GCCGCAAGGC Remember, the previous production is added to the stack right-to-left!! Stack: • cW1g Action: • Accept G, move right
PDA parsing – an example Input string: • GCCGCAAGGC Stack: • cW1 Valid production: • W1 →cW2g
PDA parsing – an example Input string: • GCCGCAAGGC Stack: • cgW2c Action: • Accept C, move right
PDA parsing – an example Input string: • GCCGCAAGGC Stack: • cgW2 Valid production: • W2 →cW3g
PDA parsing – an example Input string: • GCCGCAAGGC Stack: • cggW3c Action: • Accept C, move right
PDA parsing – an example Input string: • GCCGCAAGGC Stack: • cggW3 Valid production: • W3 →gcaa
PDA parsing – an example Input string: • GCCGCAAGGC Stack: • cggaacg Action: • Accept G, move right
PDA parsing – an example • An interlude…. • If the stack has no non-terminals and corresponds to the input string.. • GCCGCAAGGC • cggaacg • ..we would accept several symbols in a row. • let’s skip ahead a few steps!!
PDA parsing – an example Input string: • GCCGCAAGGC Stack: • c Action: • Accept C, move right
PDA parsing – an example Input string: • GCCGCAAGGC Stack: • Empty ore Action: • Accept input string!
Push-down Automata Our stem-loop context-free grammar as a Python data structure states = { "Start":[("A","W1","U"),("C","W1","G"),("G","W1","C"), ("U","W1","A")], "W1":[("A","W2","U"),("C", "W2", "G"), ("G", "W2", "C"),("U", "W2","A")], "W2":[("A","W3","U"),("C","W3", "G"), ("G", "W3", "C"),("U", "W3", "A")], "W3" : [("G", "A", "A", "A"),("G", "C", "A", "A")] } This dict has keys that are states corresponding to the left-hand side of valid productions, and values that are lists corresponding to the right-hand side of valid productions. These again are encapsulated as tuples As with our regular grammar this is just one possible way…
Python focus Some possibly useful Python • The in keyword can be used to test membership in a list: • if my_symbol in mylist_of_terminals: • # do something • Reverse iterate through a list or tuple with reversed(): • for element in reversed(cur_tuple): • # do something • Iterate by both index and item with enumerate(): • for i,NT in enumerate(list_of_nucleotides): • print I # first will be 0, then 1, etc. • print NT # first will be A, then C, etc.