Download

1 / 46
460 likes | 471 Views
Submit locally and run globally – The GLOW and OSG Experience. 1992. Leads to a “bottom up” approach to building and operating grids. My jobs should run …. … on my laptop if it is not connected to the network … on my group resources if my grid certificate expired

E N D
Submit locally and run globally –The GLOW and OSGExperience
Leads to a “bottom up”approach tobuilding andoperating grids
My jobs should run … • … on my laptop if it is not connected to the network • … on my group resources if my grid certificate expired • ... on my campus resources if the meta scheduler is down • … on my national grid if the trans-Atlantic link was cut by a submarine
The search for SUSY* • Sanjay Padhi is a UW Chancellor Fellow who is working at the group of Prof. Sau Lan Wu located at CERN (Geneva) • Using Condor Technologies he established a “grid access point” in his office at CERN • Through this access-point he managed to harness in 3 month (12/05-2/06) more that 500 CPU years from the LHC Computing Grid (LCG) the Open Science Grid (OSG) the Grid Laboratory Of Wisconsin (GLOW) resources and local group owned desk-top resources. *Super-Symmetry
What is OSG? The Open Science Grid is a US national distributed computing facility that supports scientific computing via an open collaboration of science researchers, software developers and computing, storage and network providers. The OSG Consortium is building and operating the OSG, bringing resources and researchers from universities and national laboratories together and cooperating with other national and international infrastructures to give scientists from a broad range of disciplines access to shared resources worldwide.
The OSG Project • Co-funded by DOE and NSF at an annual rate of ~$6M for 5 years starting FY-07. • 16 institutions involved – 4 DOE Labs and 12 universities • Currently main stakeholders are from physics - US LHC experiments, LIGO, STAR experiment, the Tevatron Run II and Astrophysics experiments • A mix of DOE-Lab and campus resources • Active “engagement” effort to add new domains and resource providers to the OSG consortium
FTEs Facility operations 5.0 Security and troubleshooting 4.5 Software release and support 6.5 Engagement 2.0 Education, outreach & training 2.0 Facility management 1.0 Extensions in capability and scale. 9.0 Staff 3.0 Total FTEs 33 OSG Project Execution Plan (PEP) - FTEs
Part of the OSG Consortium Contributors Project
OSG Principles • Characteristics - • Provide guaranteed and opportunistic access to shared resources. • Operate a heterogeneous environment both in services available at any site and for any VO, and multiple implementations behind common interfaces. • Interface to Campus and Regional Grids. • Federate with other national/international Grids. • Support multiple software releases at any one time. • Drivers - • Delivery to the schedule, capacity and capability of LHC and LIGO: • Contributions to/from and collaboration with the US ATLAS, US CMS, LIGO software and computing programs. • Support for/collaboration with other physics/non-physics communities. • Partnerships with other Grids - especially EGEE and TeraGrid. • Evolution by deployment of externally developed new services and technologies:.
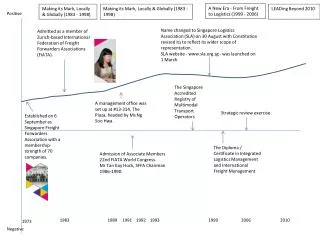
Grid of Grids - from Local to Global National Campus Community
Who are you? • A resource can be accessed by a user via the campus, community or national grid. • A user can access a resource with a campus, community or national grid identity.
32 Virtual Organizations - participating Groups 3 with >1000 jobs max. (all particle physics) 3 with 500-1000 max. (all outside physics) 5 with 100-500 max (particle, nuclear, and astro physics)
NSF Middleware Initiative (NMI): Condor, Globus, Myproxy OSG Middleware Layering CMSServices & Framework ATLAS Services &Framework CDF, D0SamGrid & Framework LIGOData Grid Applications OSG Release Cache: VDT + Configuration, Validation, VO management Virtual Data Toolkit (VDT) Common Services NMI + VOMS, CEMon (common EGEE components), MonaLisa, Clarens, AuthZ Infrastructure
OSG Middleware Deployment Domain science requirements. Condor, Globus, Privilege, EGEE etc OSG stakeholders and middleware developer (joint) projects. Test on “VO specific grid” Integrate into VDT Release. Deploy on OSG integration grid Provision in OSG release & deploy to OSG production.
Inter-operability with Campus grids At this point we have three operational campus grids – Fermi, Purdue and Wisconsin. We are working on adding Harvard (Crimson) and Lehigh. FermiGrid is an interesting example for the challenges we face when making the resources of a campus (in this case a DOE Laboratory) grid accessible to the OSG community
What is FermiGrid? • Integrates resources across most (soon all) owners at Fermilab. • Supports jobs from Fermilab organizations to run on any/all accessible campus FermiGrid and national Open Science Grid resources. • Supports jobs from OSG to be scheduled onto any/all Fermilab sites. • Unified and reliable common interface and services for FermiGrid gateway - including security, job scheduling, user management, and storage. • More information is available at http://fermigrid.fnal.gov
Job Forwarding and Resource Sharing • Gateway currently interfaces 5 Condor pools with diverse file systems and >1000 Job Slots. Plans to grow to 11 clusters (8 Condor, 2 PBS and 1 LSF) • Job scheduling policies and in place agreements for sharing allow fast response to changes in resource needs by Fermilab and OSG users. • Gateway provides single bridge between OSG wide area distributed infrastructure and FermiGrid local sites. Consists of a Globus gate-keeper and a Condor-G • Each cluster has its own Globus gate-keeper • Storage and Job execution policies applied through Site-wide managed security and authorization services.
OSG General Users Fermilab Users OSG “agreed” Users DZero Condor pool CDF Condor pool CMS Condor pool Shared Condor pool Access to FermiGrid FermiGrid Gateway GT-GK Condor-G Condor-G Condor-G Condor-G GT-GK GT-GK GT-GK GT-GK
The Crimson Grid is • a Scalable collaborative computing environment for research at the interface of science and engineering • a Gateway/Middleware release service to enable campus/community/national/global computing infrastructures for interdisciplinary research • a Test bed for faculty & IT-industry affiliates within the framework of a production environment for integrating HPC solutions for higher education & research • a Campus Resource for skills & knowledge sharing for advanced systems administration & management of switched architectures
Homework? CrimsonGrid ATLAS Campus Grids OSG OSG Tier II
Grid Laboratory of Wisconsin 2003 Initiative funded by NSF/UW at ~ $1.5M Six Initial GLOW Sites • Computational Genomics, Chemistry • Amanda, Ice-cube, Physics/Space Science • High Energy Physics/CMS, Physics • Materials by Design, Chemical Engineering • Radiation Therapy, Medical Physics • Computer Science Diverse users with different deadlines and usage patterns.
UW Madison Campus Grid • Condor pools in various departments, made accessible via Condor ‘flocking’ • Users submit jobs to their own private or department Condor scheduler. • Jobs are dynamically matched to available machines. • Crosses multiple administrative domains. • No common uid-space across campus. • No cross-campus NFS for file access. • Users rely on Condor remote I/O, file-staging, AFS, SRM, gridftp, etc.
Housing the Machines • Condominium Style • centralized computing center • space, power, cooling, management • standardized packages • Neighborhood Association Style • each group hosts its own machines • each contributes to administrative effort • base standards (e.g. Linux & Condor) to make easy sharing of resources • GLOW has elements of both, but leans towards neighborhood style
The value of the big G • Our users want to collaborate outside the bounds of the campus (e.g. Atlas and CMS are international). • We also don’t want to be limited to sharing resources with people who have made identical technological choices. • The Open Science Grid gives us the opportunity to operate at both scales, which is ideal.
condor_submit schedd (Job caretaker) startd (Job Executor) Submitting Jobs within UW Campus Grid UW HEP User HEP matchmaker CS matchmaker GLOW matchmaker flocking • Supports full feature-set of Condor: • matchmaking • remote system calls • checkpointing • MPI • suspension VMs • preemption policies
HEP matchmaker GLOW matchmaker CS matchmaker condor_submit Globus gatekeeper schedd (Job caretaker) flocking schedd (Job caretaker) startd (Job Executor) condor gridmanager Submitting jobs through OSG to UW Campus Grid Open Science Grid User
condor_submit schedd (Job caretaker) globus gatekeeper condor gridmanager Routing Jobs fromUW Campus Grid to OSG HEP matchmaker CS matchmaker GLOW matchmaker Grid JobRouter • Combining both worlds: • simple, feature-rich local mode • when possible, transform to grid job for traveling globally
GLOW Architecture in a Nutshell One big Condor pool • But backup central manager runs at each site (Condor HAD service) • Users submit jobs as members of a group (e.g. “CMS” or “MedPhysics”) • Computers at each site give highest priority to jobs from same group (via machine RANK) • Jobs run preferentially at the “home” site, but may run anywhere when machines are available
Adding High Availability to Condor Central Manager Artyom SharovTechnion – Israel Institute of Technology, Haifa
Design highlights (HAD) • Modified version of Bully algorithm • For more details: H. Garcia-Molina. Elections in a Distributed Computing System., IEEE Trans. on Computers, C-31(1):48.59, Jan 1982. • One HAD leader + many backups • HAD as a state machine • “I am alive” messages from leader to backups • Detection of leader failure • Detection of multiple leaders (split-brain) • “I am leader” messages from HAD to replication
HAD-enabled pool • Multiple Collectors run simultaneously on each Central Manager (CM) machine • All submission and execution machines must be configured to report to all CMs • High Availability • HAD runs on each CM • Replication daemon runs on each CM (if enabled) • HAD makes sure a single Negotiator runs on one of the CMs • Replication daemon makes sure the up-to-date accountant file is available
Accommodating Special Cases • Members have flexibility to make arrangements with each other when needed • Example: granting 2nd priority • Opportunistic access • Long-running jobs which can’t easily be checkpointed can be run as bottom feeders that are suspended instead of being killed by higher priority jobs • Computing on Demand • tasks requiring low latency (e.g. interactive analysis) may quickly suspend any other jobs while they run
Example Uses • Chemical Engineering • Students do not know where the computing cycles are coming from - they just do it - largest user group • ATLAS • Over 15 Million proton collision events simulated at 10 minutes each • CMS • Over 70 Million events simulated, reconstructed and analyzed (total ~10 minutes per event) in the past one year • IceCube / Amanda • Data filtering used 12 CPU-years in one month • Computational Genomics • Prof. Shwartz asserts that GLOW has opened up a new paradigm of work patterns in his group • They no longer think about how long a particular computational job will take - they just do it
GLOW Usage 4/04-9/05 Leftover cycles available for “Others” Takes advantage of “shadow” jobs Take advantage of check-pointing jobs Over 7.6 million CPU-Hours (865 CPU-Years) served!
Elevating from GLOW to OSG Job 1 Job 2 Job 3 Job 4 Job 5 … Schedd On The Side Job 4* job queue Schedd
Gatekeeper Random Seed Random Seed Random Seed Random Seed Random Seed Random Seed Random Seed Random Seed Random Seed Random Seed Random Seed Random Seed Random Seed Negotiator Schedd X Random Seed Random Seed Random Seed Startds The Grid Universe vanilla site X • easier to live with private networks • may use non-Condor resources • restricted Condor feature set(e.g. no std universe over grid) • must pre-allocating jobsbetween vanilla and grid universe
Random Seed Z Random Seed Random Seed Random Seed Random Seed Random Seed Random Seed Random Seed Random Seed Random Seed Random Seed Random Seed Random Seed Random Seed Random Seed Random Seed Random Seed Random Seed Random Seed Schedd On The Side Negotiator Gatekeeper Schedd X Random Seed Random Seed Random Seed Local Startds Y Dynamic Routing Jobs • dynamic allocation of jobsbetween vanilla and grid universes. • not every job is appropriate fortransformation into a grid job. vanilla site X site Y site Z
What About Flow Control? • May restrict routing to jobs which have been rejected by negotiator. • May limit maximum actively routed jobs on a per site basis. • May limit maximum idle routed jobs per site. • Periodic remove of idle routed jobs is possible, but no guarantee of optimal rescheduling. • Routing table may be reconfigured dynamically. • Multicast? Might be interesting to try.
What About I/O? • Jobs must be sandboxable (i.e. specifying input/output via transfer-files mechanism). • Routing of standard universe is not supported. • Additional restrictions may apply, depending on site network and disk.
Random Seed Random Seed Random Seed Random Seed Schedd On The Side Negotiator Schedd Schedd X Random Seed Random Seed Random Seed What Types of Grids? • Routing table may contain any combination of grid types supported by the grid universe. • Example: Condor-C site X • for two Condor sites, schedd-to-scheddsubmission requires no additional software • however, still not as trivial to use as flocking