Download

1 / 14
140 likes | 287 Views
Phone Recognition using Sphinx. Chia-Ho Ling Sunya Santananchai. Objective. Use speech data corpora to build a model using CMU Sphinx. Apply a built model to decode a test speech data corpora. Use the built model in real time. Introduction.

E N D
Phone Recognition using Sphinx Chia-Ho Ling Sunya Santananchai
Objective • Use speech data corpora to build a model using CMU Sphinx. • Apply a built model to decode a test speech data corpora. • Use the built model in real time.
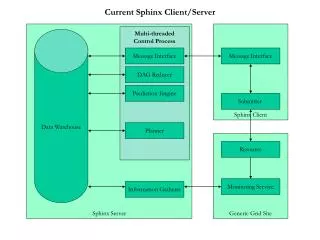
Introduction • CMU Sphinx is the Sphinx Group at Carnegie Mellon University. • The Sphinx Group is committed to releasing Sphinx projects in order to stimulate the creation of speech-using tools and applications in speech recognition • CMU Sphinx provides a basic level of technology to anyone interested in creating speech-using applications.
Requirements for CMU Sphinx • GNU/Linux, Unix variants, and Windows NT or later • Cygwin with perl and tcsh shell for windows • SPHINX system: Sphinxbase, Sphinx3, and SphinxTrain • Perl to run the provided scripts, and a C compiler to compile the source code
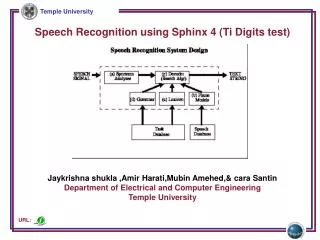
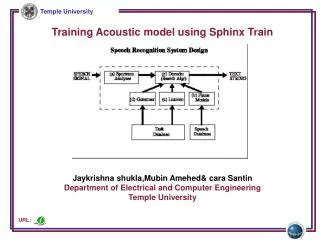
Setting up the data Set up system Setting up the trainer Setting up the decoder Training corpora Test corpora Make features Build a model Training corpora Word error rate Test corpora Live to decode Live recording Result for decoding
Training Corpora • The ICSI Meeting corpus Training 532 samples from 580 whole samples • CCW17 corpus Training 500 samples form 602 whole samples
Testing Corpora • The ICSI Meeting corpus Testing 14 samples from the rest 48 samples • CCW17 corpus Testing 6 samples from the rest 102 samples • Project corpus Testing 10 samples
Make Features • Configuration file • Extension file format: RAW or NIST
Build A Model • Dictionary file • Phone file • Training identity file • Transcription file
Conclusion • Each sample in mrd_data corpus includes around 60 words so each sentence is not easy to recognize all words correct. Therefore sentence error rate is 100%. • For mrd_data corpus, the word error rate is 25%. • For project corpus, we get very high error rate. There are several factors may effect it: pronunciation of speakers, the environment, and the quality of hardware and software.
References • [1] The Sphinx Group at Carnegie Mellon University. CMU Sphinx provides a basic level of technology to anyone interested in creating speech-using applications. http://cmusphinx.sourceforge.net/html/cmusphinx.php • [2] The ICSI Meeting Corpus. Including simultaneous multi-channel audio recordings, word-level orthographic transcriptions, and supporting documentation -- collected at the International Computer Science Institute in Berkeley during the years 2000-2002. http://www.icsi.berkeley.edu/Speech/mr/ • [3] CCW17.