Download
1 / 12
120 likes | 225 Views
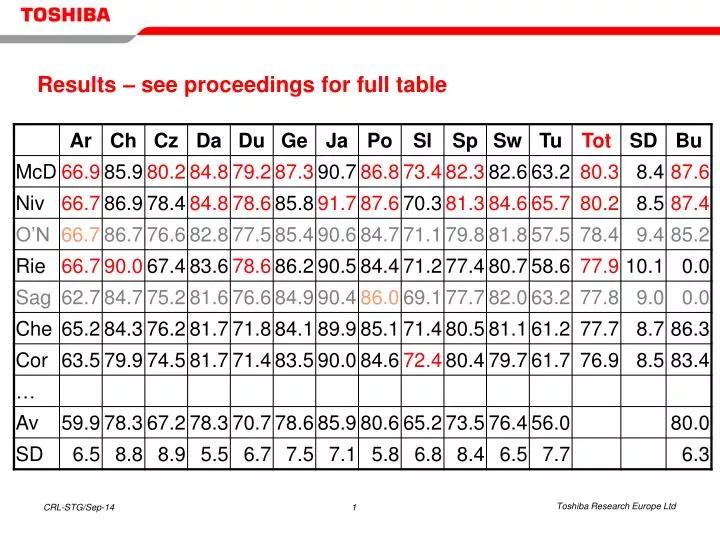
Results – see proceedings for full table. Results — continued. “Good” parsers good on all languages Best overall scores achieved by two very different approaches Little difference in ranking (mostly just +/ −1) when using UAS or label accuracy metric instead of LAS

E N D
Results — continued • “Good” parsers good on all languages • Best overall scores achieved by two very different approaches • Little difference in ranking (mostly just +/−1) when using UAS or label accuracy metric instead of LAS • except: Two groups with special emphasis on DEPREL values score +2/+3 ranks for label accuracy; one group with bug in HEAD assignment scores +4 ranks for UAS • Very little difference in scores as well as rankings when scoring all tokens (i.e. including punctuation) • But some outliers in ranking for individual languages • Turkish: Johansson and Nugues +7, Yuret +7, Riedel et al. −5 • Dutch: Canisius et al. +6, Schiehlen and Spranger +8
The future — Using the resources — Parsed test sets • Parser combination • Check test cases where parser majority disagrees with treebank • Possible reasons • Challenge for current parser technology • Treebank annotation wrong • Conversion wrong • (Non-sentence) • for German test data: checked cases where 17 out of 18 parsers said DEPREL=X but gold standard had DEPREL=Y (11 cases) • 4: challenge: distinguishing PP complements from adjuncts • 1: treebank PoS tag wrong • 1: non-sentence • 5: either treebank or conversion wrong (to be investigated)
The future — Using the resources — Parsers • Collaborate with treebank providers or other treebank experts • To semi-automatically enlarge or improve the treebank • To use automatically parsed texts as input for other NLP projects • Please let us know if you are willing to help: • Arabic: Otakar Smrž, Jan Hajič; also general feedback • Bulgarian: Petya Osenova, Kiril Simov • Czech: Jan Hajič • German: Martin Forst, Michael Schiehlen, Kristina Spranger • Portuguese : Eckhard Bick • Slovene: Tomaž Erjavec • Spanish: Toni Martí,Roser Morante • Swedish: Joakim Nivre • Turkish: Gülşen Eryiğit • Gertjan van Noord (Dutch Alpino treebank) interested in general feedback
The future — Improving the resources • http://nextens.uvt.nl/~conll/ is a static web page • But hopefully many other people will continue this line of research • They need a platform to exchange (information about) • Experience with/bug reports about/patches for treebanks • Treebank conversion and validation scripts (esp. head tables!) • Other new/improved tools (e.g. visualization, analysis) • Details of experiments on new treebanks (e.g. training/test split) • Predictions on test sets by new/improved parsers • ... • SIGNLL agreed to provide such a platform (hosted at Tilburg University) • http://depparse.uvt.nl/: a Wiki site where everybody is welcome to contribute!
Acknowledgements — Many thanks to … • Jan Hajič for granting the PDT/PADT temporary licenses for CoNLL-X and talking to LDC about it • Christopher Cieri for arranging distribution through LDC and Tony Castelletto for handling the distribution • Otakar Smrž for valuable help during the conversion of PADT • the SDT people for granting the special license for CoNLL-X and Tomaž Erjavec for converting the SDT for us • Matthias Trautner Kromann and assistants for creating the DDT and releasing it under the GNU General Public License • Joakim Nivre, Johan Hall and Jens Nilsson for the conversion of DDT to Malt-XML, for the conversion of the original Talbanken to Talbanken05 and for making it freely available for research purposes • Joakim Nivre again for prompt and proper response to all our questions • Bilge Say and Kemal Oflazer for granting the Metu-Sabancı license for CoNLL-X and answering questions • Gülşen Eryiğit for making many corrections to Metu-Sabancı and discussing some aspects of the conversion
Acknowledgements — continued • the TIGER team (esp. Martin Forst) for allowing us to use the treebank for the shared task • Yasuhiro Kawata, Julia Bartels and colleagues from Tübingen University for the construction of the JapaneseVerbmobil treebank • Sandra Kübler for providing the Japanese Verbmobil data and granting the special license for CoNLL-X • Diana Santos, Eckhard Bick and other Floresta sintá(c)tica project members for creating the treebank and making it publicly available, for answering many questions about the treebank (Diana and Eckhard), for correcting problems and making new releases (Diana), and for sharing scripts and explaining the head rules implemented in them (Eckhard) • Jason Baldridge for useful discussions and to Ben Wing for independently reporting problems which Diana then fixed • Gertjan van Noord and the other people at Groningen University for creating the AlpinoTreebank and releasing it for free • Gertjan van Noord for answering all our questions and for providing extra test material • Antal van den Bosch for help with the memory-based tagger
Acknowledgements — continued • Academia Sinica for granting the Sinica treebank temporary license for CoNLL-X • Keh-Jiann Chen for answering our questions about the Sinica treebank • Montserrat Civit and Toni Martí for allowing us to use Cast3LBfor CoNLL-X and supplying the head table and function mapping • Kiril Simov and Petya Osenova for allowing us to use the BulTreeBank for CoNLL-X • Svetoslav Marinov, Atanas Chanev, Kiril Simov and Petya Osenova for converting the BulTreeBank • Dan Bikel for making the Randomized Parsing Evaluation Comparator • SIGNLL for having a shared task • Erik Tjong Kim Sang for posting the Call for Papers • Lluís Màrquez and Xavier Carreras for sharing their experience from organizing the two previous shared tasks • Lluís Màrquez for being a very helpful CoNLL organizer • All participants, including those who could not submit results or cannot be here today It has been a pleasure working with you!
Future research • More result analysis • Baseline • Correlation between parsing approach and types of errors • Importance of individual features and algorithm details • Repeat experiments on improved data • POSTAG and FEATS for Talbanken05, LEMMA for Talbanken05 (+DDT) • LEMMA and FEATS for new version of TIGER, POSTAG for TIGER • better DEPREL for Cast3LB • larger treebanks • having several good parsers facilitates annotation of more text! • better quality • check cases where parsers and treebank disagree!
Future research — continued • Repeat experiments with other parsers • http://nextens.uvt.nl/~conll/post_task_data.html • Repeat experiments with additional external information • large-scale distributional data harvested from the internet • Similar experiments but including secondary relations • Similar experiments on other data • Hebrew treebank • SUSANNE treebank (English) • Kyoto University Corpus, ATR corpus (Japanese) • Szeged Corpus (Hungarian) • see list in Wikipedia article on “treebank” (please contribute!) • Integrate automatic tokenization, morphological analysis and POS tagging