Download

1 / 42
420 likes | 554 Views
Trust and Profit Sensitive Ranking for Web Databases and On-line Advertisements. Raju Balakrishnan (PhD Proposal Defense) Committee: Subbarao Kambhampati (chair) Yi Chen AnHai Doan Huan Liu. Agenda. Problem 1: Ranking the Deep Web Need for New Ranking.

E N D
Trust and Profit Sensitive Ranking for Web Databases and On-line Advertisements Raju Balakrishnan (PhD Proposal Defense) Committee: Subbarao Kambhampati (chair) Yi Chen AnHai Doan Huan Liu.
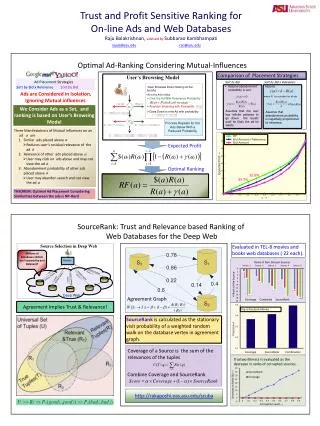
Agenda • Problem 1: Ranking the Deep Web • Need for New Ranking. • SourceRank: Agreement Analysis. • Computing Agreement and Collusion . • Results & System Implementation. • Proposed Work: Ranking the Deep Web Results. • Problem 2: Ad-Ranking sensitive to Mutual Influences. • Browsing model & Nature of Influence. • Ranking Function and Generalizations. • Results. • Proposed Work: Mechanism Design for Ads.
Deep Web Integration Scenario Search engines have nominal access. We don’t Google for a “Honda Civic 2008 Tempe” Millions of sources containing structured tuples Uncontrolled collection of redundant information Mediator ←answer tuples ←query query→ answertuples→ ←answer tuples answer tuples→ answer tuples→ query→ ←query Web DB ←query Web DB Web DB Web DB Web DB Deep Web
Why Another Ranking? Rankings are oblivious to result Importance & Trustworthiness Example Query: “Godfather Trilogy” on Google Base • Trustworthiness (bait and switch) • The titles and cover image match exactly. • Prices are low. Amazing deal! • But when you proceed towards check out you realize that the product is a different one! (or when you open the mail package, if you are really unlucky) Importance: Searching for titles matching with the query. None of the results are the classic Godfather
Source Selection in the Deep Web Problem: Given a user query, select a subset of sources to provide important and trustworthy answers. Surface web search combines link analysis with Query-Relevance to consider trustworthiness and relevance of the results. Unfortunately, deep web records do not have the hyper-links.
Source Agreement Observations • Many sources return answers to the same query. • Comparison of semantics of the answers is facilitated by structure of the tuples Idea: Compute importance and trustworthiness of sources based on the agreement of answers returned by different sources.
Agreement Implies Trust & Importance. • Important results are likely to be returned by a large number of sources. • e.g. For the query “Godfather” hundreds of sources return the classic “TheGodfather” while a few sources return the little known movie “Little Godfather”. • Two independent sources are not likely to agree upon corrupt/untrustworthy answers. • e.g. The wrong author of the book (e.g. Godfather author as “Nino Rota”) would not be agreed by other sources. As we know, truth is one (or a few), but lies are many.
Agreement is not just for the search Which tire?
Agreement Implies Trust & Relevance Probability of agreement of two independently selected irrelevant/false tuples is Probability of agreement or two independently picked relevant and true tuples is
Method: Sampling based Agreement where induces the smoothing links to account for the unseen samples. R1, R2 are the result sets of S1, S2 . • Agreement is computed using 200 key word queries. • Partial titles of movies/books are used as queries. • Mean agreement over all the queries are used as the final agreement. Link semantics from Si to Sj with weight w: Si acknowledges w fraction of tuples in Sj. Since weight is the fraction, links are unsymmetrical.
Method: Calculating SourceRank How can I use the agreement graph for improved search? • Source graph is viewed as a markov chain, with edges as the transition probabilities between the sources. • The prestige of sources considering transitive nature of the agreement may be computed based on a markov random walk. SourceRank is equal to this stationary visit probability of the random walk on the database vertex. This static SourceRank may be combined with a query-specific source-relevance measure for the final ranking.
Computing Agreement is Hard Computing semantic agreement between two records is the record linkage problem, and is known to be hard. • Example “Godfather” tuples from two web sources. Note that titles and castings are denoted differently. Semantically same entities may be represented syntactically differently by two databases (non-common domains).
Method: Computing Agreement • Agreement Computation has Three levels. • Comparing Attribute-Value • Soft-TFIDF with Jaro-Winkler as the similarity measure is used. • Comparing Records. • We do not assume predefined schema matching. • Instance of a bipartite • matching problem. • Optimal matching is . • Greedy matching is used. Values are greedily matched • against most similar value in the other record. • The attribute importance are weighted by IDF. (e.g. same titles (Godfather) is more important than same format (paperback)) • Comparing result sets. • Using the record similarity computed above, result set similarities are computed using the same greedy approach.
Detecting Source Collusion The sources may copy data from each other, or make mirrors, boosting SourceRank of the group. Observation 1: Even non-colluding sources in the same domain may contain same data. e.g. Movie databases may contain all Hollywood movies. Observation 2: Top-k answers of even non-colluding sources may be similar. e.g. Answers to query “Godfather” may contain all the three movies in the Godfather trilogy.
Source Collusion--Continued • Basic Method: If two sources return same top-k answers to the queries with large number of answers (e.g. queries like “the” or “DVD”) they are likely to be colluding. • We compute the degree of collusion of sources as the agreement on large answer queries. • Words with highest DF in the crawl is used as the queries. • The agreement between two databases are adjusted for collusion by multiplying by • (1-collusion).
Factal: Search based on SourceRank ”I personally ran a handful of test queries this way and gotmuch better [than Google Products] results using Factal” --- Anonymous WWW’11 Reviewer. http://factal.eas.asu.edu
Evaluation All experiments distinguish the SourceRank from baseline methods with 0.95 confidence levels. Precision and DCG are compared with the following baseline methods CORI: Adapted from text database selection. Union of sample documents from sources are indexed and sources with highest number term hits are selected [Callanet al. 1995]. Coverage: Adapted from relational databases. Mean relevance of the top-5 results to the sampling queries [Nieet al. 2004]. Google Products: Products Search that is used over Google Base
Online Top-4 Sources-Movies Though combinations are not our competitors, note that they are not better: 1.SourceRank implicitly considers query relevance, as selected sources fetch answers by query similarity. Combining again with query similarity may be an “overweighting” 2. Search is Vertical 29%
Google Base Top-5 Precision-Books • 675 Google Base sources responding to a set of book queries are used as the book domain sources. • GBase-Domain is the Google Base searching only on these 675 domain sources. • Source Selection by SourceRank (coverage) followed by ranking by Google Base. 675 Sources 24%
Trustworthiness of Source Selection Corrupted the results in sample crawl by replacing attribute vales not specified in the queries with random strings (since partial titles are the queries, we corrupted attributes except titles). If the source selection is sensitive to corruption, the ranks should decrease with the corruption levels. Google Base Movies Every relevance measure based on query-similarity are oblivious to the corruption of attributes unspecified in queries.
Collusion—Ablation Study • Two database with the same one million tuples from IMDB are created. • Correlation between the ranking functions reduced increasingly. Observations: At high correlation the adjusted agreement is very low. Adjusted agreement is almost the same as the pure agreement at low correlations. Natural agreement will be preserved while catching near-mirrors.
Computation Time • Random walk is known to be feasible in large scale. • Time to compute the agreements is evaluated against number of sources. • Note that the computation is offline. • Easy to parallelize.
Publications and Recognition SourceRank:Relevance and Trust Assessment for Deep Web Sources Based on Inter-Source Agreement.Raju Balakrishnan, Subbarao Kambhampati. Accepted for WWW 2011 (Full Paper). Factal: Integrating Deep Web Based on Trust and Relevance. Raju Balakrishnan, Subbarao Kabmbhampati. Accepted for WWW 2011 (Demonstration). SourceRank:Relevance and Trust Assessment for Deep Web Sources Based on Inter-Source Agreement (Best Poster Award, WWW 2010). Raju Balakrishnan, Subbarao Kambhampati. WWW 2010 Pages 1055~1056.
Proposed Work: Ranking the Deep Web Results Results from the selected sources need to be combined and ranked. Ranking is online and hence time critical. We plan to: • Consider Higher order agreements. e.g. Second order agreement, i.e. Friends of two tuples are agreeing to each other. • Computing and combining query-similarity. Query similarity considering structure of tuples. • Positional voting, as sources rank tuples. e.g. Borda count instead of set based agreement used currently.
Ranking Deep Web Results---Continued • Learning to combine ranking Parameters. Multiple Parameters: agreement, lineage, query-similarity higher order agreements etc. need to be combined. • Considering Diversity Ranking. Incorporating diversity in the result level and in the source level. • Large Scale Evaluation of Result Ranking. Similar to source selection, the result ranking need to be evaluated on multiple large scale datasets. • Enhancing prototype. Factal prototype may be enhanced with the result ranking.
Agenda Search engines generate their multi-billion dollar revenue by textual ads. Related problem of ranking of ads is as important as the ranking of results. A different aspect of ranking • Ranking the Deep Web • Need for new ranking. • SourceRank: Agreement Analysis. • Computing Agreement and Collusion . • Results & System Implementation. • Proposed Work: Ranking the Deep Web Results. • Problem 2: Ad-Ranking sensitive to Mutual Influences. • Motivation and Problem Definition. • Browsing model & Nature of Influence • Ranking Function & Generalization • Results. • Proposed Work: Mechanism Design & Evaluations.
Ad Ranking: State of the Art Sort by Bid Amount x Relevance Sort by Bid Amount Ads are Considered in Isolation, as both ignore Mutual influences. We consider ads as a set, and ranking is based on user’s browsing model
If is similar to residual relevance of decreases and abandonment probability increases. User’s Browsing Model • User browses down staring at the first ad • At every ad he May • Click the ad with relevance probability • Goes down to the next ad with probability • Abandon browsing with probability Process repeats for the ads below with a reduced probability
Mutual Influences • Three Manifestations of Mutual Influences on an ad are: • Similar ads placed above • Reduces user’s residual relevance of • Relevance of other ads placed above • User may click on above ads may not view • Abandonment probability of other ads placed above • User may abandon search and may not view
Expected Profit Considering Ad Similarities Considering bids ( ), residual Relevance ( ), abandonment probability ( ), and similarities the expected profit from a set of nresults is, Expected Profit = THEOREM: Ranking maximizing expected profit considering similarities between the results is NP-Hard Even worse, constant ratio approximation algorithms are hard (unless NP = ZPP) for diversity ranking problem Proof is a reduction of independent set problem to choosing top-k ads considering similarities.
Expected Profit Considering other two Mutual Influences (2 and 3) Dropping similarity, hence replacing Residual Relevance ( ) by Absolute Relevance ( ), Ranking to maximize this expected utility is a sorting problem Expected Profit =
Optimal Ranking Rank ads in the descending order of: • The physical meaning RF is the profit generated for unit consumed view probability of ads • Higher ads have more view probability. Placing ads producing more profit for unit consumed view probability higher up is intuitive.
Comparison to current Ad Rankings Sort by Bid Amount • Assume abandonment probability is zero Assume where is a constant for all ads Bid Amount x Relevance Assumes that the user has infinite patience to go down the results until he finds the ad he wants. Assumes that abandonment probability is negatively proportional to relevance.
Generality of the Proposed Ranking The generalizedranking based on utilities. For documents utility=relevance For ads utility=bid amount Popular relevance ranking
Quantifying Expected Profit Abandonment probability Uniform Random as Bid amount only strategy becomes optimal at Relevance Uniform random as Difference in profit between RF and competing strategy is significant Number of Clicks Zipfrandom with exponent 1.5 35.9% Proposed strategy gives maximum profit for the entire range 45.7% Bid Amounts Uniform random
Publication and Recognition Optimal Ad-Ranking for Profit Maximization. Raju Balakrishnan, Subbarao Kabmbhampati. WebDB 2008 Yahoo! Research Key scientific Challenge award for Computation advertising, 2009-10
Proposed Work: Mechanism Design and Analysis • Ad-Auction based on the proposed ranking Associate a pricing mechanism (e.g. Generalized Second Pricing) wit the proposed ranking to formulate a complete auction mechanism. • Formulating an envy free equilibrium At envy free equilibria, no advertiser will be able to increase the profit by changing bids, and the auction becomes stable. • Analysis of advertiser’s profit and comparison with the existing mechanisms. The profits at equilibrium is likely to be the sustained profit.
Proposed Work: Mining Ad Ranking Parameters Evaluating the proposed ranking on Click Logs • In addition to currently used CTR and bid amounts, the proposed ranking requires the additional parameter abandonment probability. • Mining/Learning abandonment probability from click logs, and using to improve ranking will ensure the applicability of the proposed method. • Since the access to the ad click logs is restricted within search providers, I am hoping to perform this work as part of a possible summer internship (this is a risk factor).
Contributions (completed & proposed) 1. SourceRank based source selection sensitive to trustworthiness and importance for the deep web. 2. A wisdom of sources approach to rank deep web results considering trust and relevance. 3. An optimal generalized ranking for ads and search results. 4. A ranking framework optimal with respect to the perceived relevance of search snippets, and abandonment probability. • A complete auction mechanism extending the optimal ranking with pricing.