Download

1 / 29
300 likes | 387 Views
Trust and Profit Sensitive Ranking for Web Databases and On-line Advertisements. Raju Balakrishnan (Arizona State University). Agenda. Trust and Relevance based Ranking of Web Databases for the Deep Web . Ad-Ranking Considering Mutual-Influences. Deep Web Integration Problem.

E N D
Trust and Profit Sensitive Ranking for Web Databases and On-line Advertisements Raju Balakrishnan (Arizona State University)
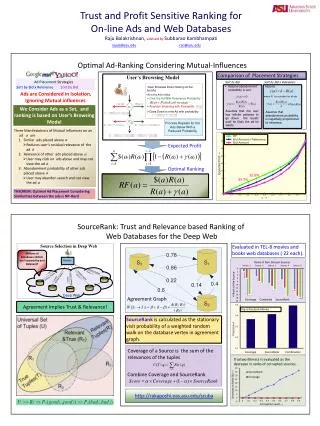
Agenda Optimal Ad Ranking for Profit Maximization • Trust and Relevance based Ranking of Web Databases for the Deep Web. • Ad-Ranking Considering Mutual-Influences.
Deep Web Integration Problem Uncontrolled Collection of Redundant Information Millions of Databases Containing Structured Tuples Mediator ←answer tuples ←query query→ answertuples→ ←answer tuples answer tuples→ answer tuples→ query→ ←query Web DB ←query Web DB Web DB Web DB Web DB Deep Web
Source Selection in Deep Web Given a user query, select a subset of sources to provide most relevant and trustworthy answers. Trustworthiness: Degree of Belief in the correctness of the data Relevance: Degree by which the data satisfies the information needs of the user. Search Results must be Trustworthy and Relevant. Surface web Search combines hyper-link based PageRank and Relevance to Assure trust and relevance of results.
Source Agreement Agreement Based Relevance and Trust assessment May be intuitively understood as a meta-reviewer assessing quality of a paper based on agreement between primary reviews. Reviewers agreed upon by other reviewers are likely to be relevant and trustworthy. Observations • Many Sources Return Answers to the Same Query. • Comparison of Semantics of the answers is facilitated by structure of the tuples Idea: Compare Agreement of Answers Returned by Different Sources to Assess the Reputation of Sources!
Agreement Implies Trust & Relevance Probability of Agreement or Two independently selected irrelevant/false tuples Probability of Agreement or two independently picked relevant and true tuples is
Computing Agreement between Sources • Closely Related to Record Linkage Problem for Integration of databases without common domains (Cohen 98). • We used a Greedy matching between tuples using Jaro-Winkler similarity with SoftTF-IDF, since this measure performs best for named entity matching (Cohen et al. 03) • Agreement computed using top-5 answer tuples to sample queries (200 queries each domain). • The computation complexity is ; where V is number of data sources, using top-k answers.
Representation: Agreement Graph where induces the smoothing links to account for the unseen samples. R1, R2 are the result sets of S1, S2 . Link Semantics from Sito Sj with weight w: Si acknowledges w fraction of tuples in Sj Sample agreement graph for the book sources.
Calculating SourceRank Start on a random node If he likes the result, randomly traverse a link, with a probability proportional to its weight to search an agreed database. If he does not like the node, restart the search traversing a smoothing link. How do I Search using the agreement graph? • This is a Weighted Markov Random Walk. • The visit probability of the searcher for a database is given by the stationary visit probability of the random walk on the database vertex. • SourceRank is equal to this stationary visit probability of the random walk on the database vertex.
Combining Coverage and SourceRank Coverage of a set of tuples T w.r.t a query q Coverage is calculated using sample queries, and we used Jaro-Winkler with SoftTF-IDF similarity between the query and the tuple as the relevance measure. We combine the Coverage and SourceRank as Databases are ranked based on this Score, with .
Evaluations and Results Evaluated in movies and books domain web databases listed in UIUC TEL-8 repository, twenty two from each domain. Evaluation Metrics • Ability to remove closely related out of domain Sources. • Top-5 precision. (relevance evaluation) • Ability to remove corrupted sources (trustworthiness) • Time to Compute the Agreement Graph
2. Top-5 Precision-Movies Movies Top-4 Source Selection Movies Top-8 Source Selection 36% 40%
2. Top-5 Precision-Books Top-4 Source Selection Top-8 Source Selection
3. Trustworthiness of Source Selection Trustworthiness-Movies Trustworthiness-Books
4. Time to Compute Agreement Graph Time Vs number of Sources Time Vs top-k tuples
System Implementation Searches Online books and movies Web Databases http://rakaposhi.eas.asu.edu/scuba • System Architecture • Implemented as a web application. • Searches real web databases
Agenda Optimal Ad Ranking for Profit Maximization • Trust and Relevance based Ranking of Web Databases for the Deep Web. • Ad-Ranking Considering Mutual-Influences.
Ad Ranking: State of the Art Sort by Bid Amount x Relevance Sort by Bid Amount Ads are Considered in Isolation, Ignoring Mutual influences. We Consider Ads as a Set, and ranking is based on User’s Browsing Model Optimal Ad Ranking for Profit Maximization
Mutual Influences • Three Manifestations of Mutual Influences on an Ad are • Similar ads placed above • Reduces user’s residual relevance of the ad • Relevance of other ads placed above • User may click on above ads may not view the ad • Abandonment probability of other ads placed above • User may abandon search and not view the ad Optimal Ad Ranking for Profit Maximization
If is similar to residual relevance of goes down and abandonment probabilities goes up. User’s Browsing Model • User Browses Down Staring at the first Ad • At every Ad he May • Click the Ad With Relevance Probability • Goes Down to next Ad with probability • Abandon Browsing with Probability Process Repeats for the Ads Below With a Reduced Probability Optimal Ad Ranking for Profit Maximization
Expected Profit Considering Ad Similarities Considering Bid Amounts ( ), Residual Relevance ( ), abandonment probability ( ), and similarities the expected profit from a set of n ads is, Expected Profit = THEOREM: Optimal Ad Placement Considering Similarities between the ads is NP-Hard Proof is a reduction of independent set problem to choosing top k ads considering similarities. Optimal Ad Ranking for Profit Maximization
Expected Profit Considering other two Mutual Influences (2 and 3) Dropping similarity, hence replacing Residual Relevance ( ) by Absolute Relevance ( ), Ranking to Maximize This Expected Profit is a Sorting Problem Expected Profit = Optimal Ad Ranking for Profit Maximization
Optimal Ranking Rank ads in Descending order of: • The physical meaning RF is the profit generated for unit consumed view probability of ad • Ads above have more view probability. Placing ads producing more profit per consumed view probability is intuitively justifiable. (Refer Balakrishnan & Kambhampati (WebDB 08)for proof of optimality) Optimal Ad Ranking for Profit Maximization
Comparison to Yahoo and Google Yahoo! • Assume abandonment probability is zero Google Assume where is a constant for all ads Assumes that the user has infinite patience to go down the results until he finds the ad he wants. Assumes that abandonment probability is negatively proportional to relevance. Optimal Ad Ranking for Profit Maximization
Quantifying Expected Profit Abandonment Probability Uniform Random as Bid Amount Only strategy becomes optimal at Relevance Uniform Random as Difference in profit between RF and competing strategy is significant Number of Clicks Zipf Random with exponent 1.5 35.9% Proposed strategy gives maximum profit for the entire range 45.7% Bid Amounts Uniform Random Optimal Ad Ranking for Profit Maximization
Thank You! Contributions SourceRank • Agreement based computation of relevance and trust of deep web sources. • System implementation to search the deep web, and formal evaluation. Ad-Ranking • Extending Expected Profit Model of Ads Based on Browsing Model, Considering Mutual Influences • Optimal Ad Ranking Considering Mutual Influences Other than Ad Similarities. Optimal Ad Ranking for Profit Maximization