Download

1 / 25
250 likes | 410 Views
Generating FPGA-Accelerated DFT Libraries. Chi-Li Yu Nov. 13, 2007. Overview. Application: 1D/2D Discrete Fourier Transform Problem: Hardware-Software Partitioning Acceleration Based on FPGA Results (compared to software-only solution): Up to 7.5 times higher performance

E N D
Generating FPGA-Accelerated DFT Libraries Chi-Li Yu Nov. 13, 2007
Overview • Application: • 1D/2D Discrete Fourier Transform • Problem: • Hardware-Software Partitioning • Acceleration Based on FPGA • Results (compared to software-only solution): • Up to 7.5 times higher performance • Up to 2.5 times better energy efficiency
Why DFT? • Discrete Fourier Transform (DFT) is an important primitive underlying many DSP applications. • Imaging/speech processing • Communication systems • Computation-intensive • Data/memory-intensive
Review of DFT Requires N2 complex multiplies and N(N-1) complex additions When N is a power-of-two, 2p:
Pipelined streaming architecture of FFT Data flow diagram of Fast Fourier Transform (FFT) Pipelined streaming architecture (Throughput: 1 sample/clock)
Problem • Pure hardware implementation • N should be a power-of-two • N is usually fixed • Arbitrary sized DFT is hard to be implemented • Flexible programmability/Fast execution time • Hardware-Software heterogeneous architecture • HW-SW partitioning
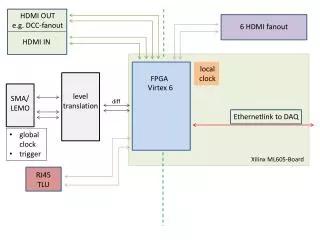
Principles of HW-SW partitioning Xilinx Virtex-II Pro Platform FPGA • Hardware: • The most computation intensive kernels that are conducive to hardware acceleration are extracted from an algorithm and realized as hardware. • Software: • Remaining computations are carried out in software. • Control-intensive part.
Xilinx Virtex-II Pro Platform FPGA • Field Programmable Gate Array: FPGA • Process: 0.13um, 1.5v • Flexible Logic Resources • Up to 1M gate-count capacity • Up to 8 Mb of True Dual-Port RAM • Embedded IBM PowerPC 405 RISC processor blocks • provide performance up to 400 MHz
The way to achieve hardware acceleration for DFT When considering power-of-2 problem sizes (i.e., DFTs on 2p points), we only need to consider two-power sized DFT kernels (i.e., DFT2q ). By off-loading the appropriate kernels into hardware, the software receives the benefit of hardware acceleration and yet can still compute arbitrary sized DFTs on top of the available kernels.
Research problem • Different kernels in hardware yield • Different performance (e.g., operations per second) • Different amounts of resources (e.g., logic, number of BRAM, or power consumption). • DFT partitioning problem • Selecting the appropriate set of throughput optimized two-power sized DFT cores to satisfy a given resource constraint (logic, power, energy) while maximizing a scalar metric, such as performance.
Test platform based on the FPGA • Notice that the data cache of PowerPC is 16kB.
DFT Performance (N is a power-of-two) • The highest performance is reached at the core’s native size. • Data does not fit into data cache at N = 8192. • Memory bandwidth becomes the main bottleneck and practically reduces all possible speedups.
DFT Performance (N is not a power-of-two) N=3*2k and N=5*2k Radix-3 and Radix-5 operations are done in software.
1D DFT with different core sizes Up to 7.5 times speedup. The best choice depends on the targeted applications. For small problem sizes, software is the most energy-efficient choice.
2D DFT with different core sizes Up to 4 times speedup. Again, for small problem sizes, software is the most energy-efficient choice. All sizes larger than or equal to 64x128 do not fit into data cache of PPC, which leads to a performance degradation.
Area/performance There is also a 3 times variation in the power consumed by the DFT calculations. In other words, by allowing up to 3 times more power (or 4 times more area) to be consumed, one can speed up a whole library up to 4 times (averaged across the library).
Power/performance There is a 4 times variation in both area consumption and normalized runtime across all possible.
Conclusions In the experiments on a Xilinx Virtex-II Pro, the automatically partitioned and generated FPGA-accelerated library has between 2 and 7.5 times higher performance and up to 2.5 times better energy efficiency than the software-only version. We have integrated this approach in the “Spiral linear-transform code-generation framework” to support push-button automatic implementation.
Conclusions Architectures with tightly integrated FPGAs and general purpose processors are starting to play an important role in both embedded and high performance computing settings. The tight integration makes it possible to offload fine and coarse grain functionalities from processors to the FPGA fabric, combining the strengths of both components.
My critiques about this paper • Strength: • Detailed analysis on the HW-SW partitioning. • Comparisons on performance and energy efficiency are very valuable. • Weakness: • 2D DFT on this platform is not efficient. • Communications between PPC and FPGA slow down the whole operation.
What is relative to our class? A heterogeneous architecture combining two different cores: one RISC CPU and one programmable hardware, FPGA. Discussions on the power consumption of this kind of platform are interesting.
What is relative to our project? • The same applications • Discrete Fourier Transform. • The same platform • Xilinx FPGA • Reduce the workload of PPC. • Introduce the concept of multi-core architectures to our hardware design.
Paper Paolo D’Alberto, et al., “Generating FPGA-Accelerated DFT Libraries,” in Proceedings of 15th Annual IEEE Symposium on Field-Programmable Custom Computing Machines (FCCM'07), pp. 173-184, Napa Valley, CA, US, 23-25th, April 2007.