Download
1 / 4
40 likes | 101 Views
Explore how to address human bottleneck in autonomic computing and intelligent information organization. Learn about self-tuning DBMS, collective human input, and automated data integration. Discover innovative solutions and challenges ahead in the tech world.

E N D
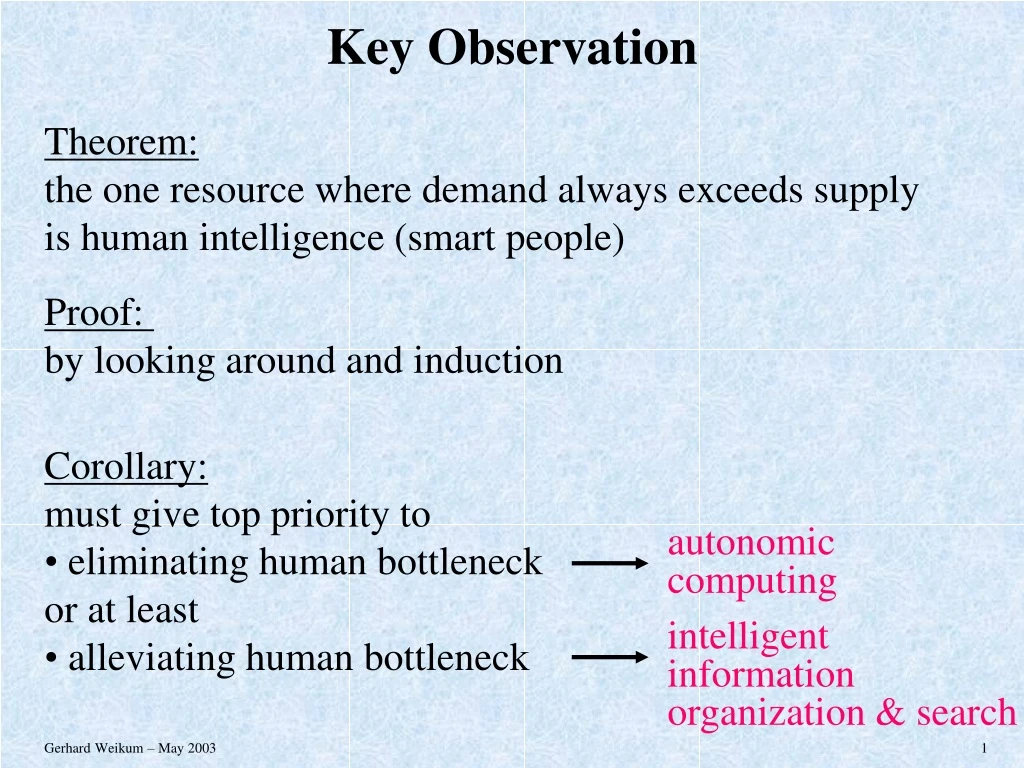
Corollary: • must give top priority to • eliminating human bottleneck • or at least • alleviating human bottleneck autonomic computing intelligent information organization & search Key Observation Theorem: the one resource where demand always exceeds supply is human intelligence (smart people) Proof: by looking around and induction
Problem 1: Self-tuning DBMS - From Visionary Buzzwords to Practical Tools - Common practice: KIWI (kill it with iron) Problem: When is KIWI applicable, and how much will it cost? • Problem (technical variant): • given: • perfect info about DB and previous week‘s multi-class workload • throughput & response time goals (QoS / SLA / WS Policies) • predict accurately performance improvement by • adding x GB memory • adding y MB/s disk bandwidth • adding or replacing processors • with all software tuning knobs left invariant or • with tuning knobs automatically adjusted Challenge: How to automate introspective bottleneck analysis and asap alerting about (modest) HW upgrades?
query logs, bookmarks, etc. provide • human assessments & endorsements • correlations among words & concepts • and among documents Problem 2: Exploit Collective Human Input for Collaborative Web Search - Beyond Relevance Feedback and Beyond Google - • href links are human endorsements PageRank, etc. • Opportunity: online analysis of human input & behavior • may compensate deficiencies of search engine Typical scenario for 3-keyword user query: a & b & c top 10 results: user clicks on ranks 2, 5, 7 top 10 results: user modifies query into a & b & c & d user modifies query into a & b & e user modifies query into a & b & NOT c top 10 results: user selects URL from bookmarks user jumps to portal user asks friend for tips Challenge: How can we use knowledge about the collective input of all users in a large community?
DB schemas, instances & • data usage in apps provide • human annotations • correlations among tables, attr‘s, etc. Problem 2‘: Exploit Collective Human Input for Automated Data Integration - Inspired by Alon Halevy - • „semantic“ data integration is hoping for ontologies • Opportunity: all existing DBs & apps already provide • a large set of subjective mini-ontologies Typical scenario for analyzing if A and B mean the same entity compare their attributes, relationships, etc. • consider attributes and relationships of all similar tables/docs in all known DBs • consider instances of A and B in comparison to instances of similar tables/docs in all known DBs • compare usage patterns of A and B in queries & apps in comparison to similar tables/docs of all known DBs Challenge: How can we use knowledge about the collective designs of all DB apps in a large community?