Download

1 / 74
740 likes | 916 Views
Scheduling. 7. CPU Scheduling. Basic Concepts Scheduling Criteria Scheduling Algorithms FCFS (FIFO) SJN Priority Scheduling Round Robin Scheduling Multilevel Queue Multilevel Feedback Queue. CPU Scheduling.

E N D
Scheduling 7 Operating Systems: A Modern Perspective, Chapter 7
CPU Scheduling • Basic Concepts • Scheduling Criteria • Scheduling Algorithms • FCFS (FIFO) • SJN • Priority Scheduling • Round Robin Scheduling • Multilevel Queue • Multilevel Feedback Queue Operating Systems: A Modern Perspective, Chapter 7
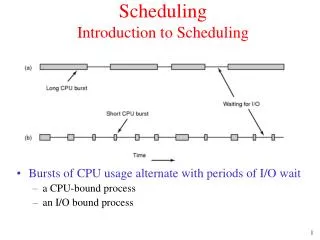
CPU Scheduling • A multiprogramming OS allows more than one process to be loaded in main memory at a time. • Processes share the CPU using time-multiplexing • A process execution consists of a cycle of CPU computation--I/O operations. • I/O operations require orders of magnitude more time to complete. • Basic Idea: When the running process requests an I/O operation, allocate CPU to another process. Operating Systems: A Modern Perspective, Chapter 7
CPU Scheduler • CPU Scheduler: the part of the Process Manager that is responsible for • handling removal of running process from CPU • Selection of another process Two major issues: • Scheduling mechanism: how is it all done? • Scheduling policy: • when is it time for a process to be removed from CPU? • Which ready process should be allocated the CPU next? Operating Systems: A Modern Perspective, Chapter 7
Model of Process Execution Preemption or voluntary yield New Process Ready List Scheduler CPU Done job job “Running” job “Ready” Resource Manager Allocate Request job job “Blocked” Resources Operating Systems: A Modern Perspective, Chapter 7
Scheduler as CPU Resource Manager Ready List Scheduler Ready to run Release Dispatch Release Dispatch Release Process Dispatch Units of time for a time-multiplexed CPU Operating Systems: A Modern Perspective, Chapter 7
Ready Process The Scheduler From Other States Process Descriptor Enqueuer Ready List Context Switcher Dispatcher CPU Running Process Operating Systems: A Modern Perspective, Chapter 7
Process/Thread Context Right Operand Status Registers Left Operand R1 R2 . . . Rn Functional Unit ALU Result PC IR Ctl Unit Operating Systems: A Modern Perspective, Chapter 7
Context Switching Old Thread Descriptor CPU New Thread Descriptor Operating Systems: A Modern Perspective, Chapter 7
Scheduling Mechanism CNTD • When a process is moved to the Ready-List • Process Descriptor (PD) is updated • the enqueuer places a pointer to PD in the Ready-List • When the Scheduler switches CPU from one process to another process • the Context-Switcher saves the state of the current process in its PD. • How context-switching occurs depends on how CPU multiplexing technique used: • voluntary multiplexing • involuntary multiplexing Operating Systems: A Modern Perspective, Chapter 7
Invoking the Scheduler • Need a mechanism to call the scheduler • Voluntary call • Process blocks itself • Calls the scheduler • Involuntary call • External force (interrupt) blocks the process • Calls the scheduler Operating Systems: A Modern Perspective, Chapter 7
Voluntary CPU Sharing yield(pi.pc, pj.pc) { memory[pi.pc] = PC; PC = memory[pj.pc]; } • pi can be “automatically” determined from the processor status registers yield(*, pj.pc) { memory[pi.pc] = PC; PC = memory[pj.pc]; } Operating Systems: A Modern Perspective, Chapter 7
More on Yield • pi and pj can resume one another’s execution yield(*, pj.pc); . . . yield(*, pi.pc); . . . yield(*, pj.pc); . . . • Suppose pj is the scheduler: // p_i yields to scheduler yield(*, pj.pc); // scheduler chooses pk yield(*, pk.pc); // pk yields to scheduler yield(*, pj.pc); // scheduler chooses ... Operating Systems: A Modern Perspective, Chapter 7
Voluntary Sharing • Every process periodically yields to the scheduler • Relies on correct process behavior • Malicious • Accidental • Need a mechanism to override running process Operating Systems: A Modern Perspective, Chapter 7
Involuntary CPU Sharing • Interval timer • Device to produce a periodic interrupt • Programmable period IntervalTimer() { InterruptCount--; if(InterruptCount <= 0) { InterruptRequest = TRUE; InterruptCount = K; } } SetInterval(programmableValue) { K = programmableValue: InterruptCount = K; } } Operating Systems: A Modern Perspective, Chapter 7
Contemporary Scheduling • Involuntary CPU sharing – timer interrupts • Time quantum determined by interval timer – usually fixed size for every process using the system • Sometimes called the time slice length Operating Systems: A Modern Perspective, Chapter 7
Scheduling Mechanism--Dispatcher • After state of "old" process is saved by context-switcher, the CPU is allocated to the Dispatcher • Dispatcher state is loaded on CPU • Dispatcher selects one of the ready processes enqueued in the Ready-List. • Dispatcher performs another context-switch from itself to selected process (saves its state and loads state of selected process). • The Process Descriptor of selected process is changed from Ready to Running. Operating Systems: A Modern Perspective, Chapter 7
Process Descriptor Ready Process Enqueue Ready List Context Switch Dispatch CPU Running Process Choosing a Process to Run • Mechanism never changes • Strategy = policy the dispatcher uses to select a process from the ready list • Different policies for different requirements Operating Systems: A Modern Perspective, Chapter 7
Policy Considerations • Policy can control/influence: • CPU utilization • Average time a process waits for service • Average amount of time to complete a job • Could strive for any of: • Equitability • Favor very short or long jobs • Meet priority requirements • Meet deadlines Operating Systems: A Modern Perspective, Chapter 7
Optimal Scheduling • Suppose the scheduler knows each process pi’s service time, t(pi) -- or it can estimate each t(pi) : • Policy can optimize on any criteria, e.g., • CPU utilization • Waiting time • Deadline • To find an optimal schedule: • Have a finite, fixed # of pi • Know t(pi) for each pi • Enumerate all schedules, then choose the best Operating Systems: A Modern Perspective, Chapter 7
However ... • The t(pi) are almost certainly just estimates • General algorithm to choose optimal schedule is O(n2) • Other processes may arrive while these processes are being serviced • Usually, optimal schedule is only a theoretical benchmark – scheduling policies try to approximate an optimal schedule Operating Systems: A Modern Perspective, Chapter 7
Model of Process Execution Preemption or voluntary yield New Process Ready List Scheduler CPU Done job job “Running” job “Ready” Resource Manager Allocate Request job job “Blocked” Resources Operating Systems: A Modern Perspective, Chapter 7
Simplified Model Preemption or voluntary yield New Process Ready List Scheduler CPU Done job job “Running” job “Ready” Resource Manager Allocate Request job job “Blocked” Resources • Simplified, but still provide analysis result • Easy to analyze performance • No issue of voluntary/involuntary sharing Operating Systems: A Modern Perspective, Chapter 7
Nonpreemptive Schedulers Blocked or preempted processes New Process Ready List Scheduler CPU Done • Try to use the simplified scheduling model • Only consider running and ready states • Ignores time in blocked state: • “New process created when it enters ready state” • “Process is destroyed when it enters blocked state” • Really just looking at “small phases” of a process Operating Systems: A Modern Perspective, Chapter 7
Estimating CPU Utilization New Process Ready List Scheduler CPU Done Let l = the average rate at which processes are placed in the Ready List, arrival rate Let m = the average service rate 1/ m = the average t(pi) l pi per second System Each pi uses 1/ m units of the CPU Operating Systems: A Modern Perspective, Chapter 7
Estimating CPU Utilization New Process Ready List Scheduler CPU Done Let l = the average rate at which processes are placed in the Ready List, arrival rate Let m = the average service rate 1/ m = the average t(pi) Let r = the fraction of the time that the CPU is expected to be busy r = # pi that arrive per unit time * avg time each spends on CPU r = l * 1/ m = l/m • Notice must have l < m (i.e., r < 1) • What if r approaches 1? Operating Systems: A Modern Perspective, Chapter 7
Talking About Scheduling ... • Let P = {pi | 0 i < n} = set of processes • Let S(pi) {running, ready, blocked} • Let t(pi) = Time process needs to be in running state (the service time) • Let W(pi) = Time pi is in ready state before first transition to running (wait time) • Let TTRnd(pi) = Time from pi first enter ready to last exit ready (turnaround time) • Batch Throughput rate = inverse of avg TTRnd • Timesharing response time = W(pi) Operating Systems: A Modern Perspective, Chapter 7
First-Come-First-Served i t(pi) 0 350 1 125 2 475 3 250 4 75 0 350 p0 TTRnd(p0) = t(p0) = 350 W(p0) = 0 Operating Systems: A Modern Perspective, Chapter 7
First-Come-First-Served i t(pi) 0 350 1 125 2 475 3 250 4 75 350 475 p0 p1 TTRnd(p0) = t(p0) = 350 TTRnd(p1) = (t(p1) +TTRnd(p0)) = 125+350 = 475 W(p0) = 0 W(p1) = TTRnd(p0) = 350 Operating Systems: A Modern Perspective, Chapter 7
First-Come-First-Served i t(pi) 0 350 1 125 2 475 3 250 4 75 475 950 p0 p1 p2 TTRnd(p0) = t(p0) = 350 TTRnd(p1) = (t(p1) +TTRnd(p0)) = 125+350 = 475 TTRnd(p2) = (t(p2) +TTRnd(p1)) = 475+475 = 950 W(p0) = 0 W(p1) = TTRnd(p0) = 350 W(p2) = TTRnd(p1) = 475 Operating Systems: A Modern Perspective, Chapter 7
First-Come-First-Served i t(pi) 0 350 1 125 2 475 3 250 4 75 950 1200 p0 p1 p2 p3 TTRnd(p0) = t(p0) = 350 TTRnd(p1) = (t(p1) +TTRnd(p0)) = 125+350 = 475 TTRnd(p2) = (t(p2) +TTRnd(p1)) = 475+475 = 950 TTRnd(p3) = (t(p3) +TTRnd(p2)) = 250+950 = 1200 W(p0) = 0 W(p1) = TTRnd(p0) = 350 W(p2) = TTRnd(p1) = 475 W(p3) = TTRnd(p2) = 950 Operating Systems: A Modern Perspective, Chapter 7
First-Come-First-Served i t(pi) 0 350 1 125 2 475 3 250 4 75 1200 1275 p0 p1 p2 p3 p4 TTRnd(p0) = t(p0) = 350 TTRnd(p1) = (t(p1) +TTRnd(p0)) = 125+350 = 475 TTRnd(p2) = (t(p2) +TTRnd(p1)) = 475+475 = 950 TTRnd(p3) = (t(p3) +TTRnd(p2)) = 250+950 = 1200 TTRnd(p4) = (t(p4) +TTRnd(p3)) = 75+1200 = 1275 W(p0) = 0 W(p1) = TTRnd(p0) = 350 W(p2) = TTRnd(p1) = 475 W(p3) = TTRnd(p2) = 950 W(p4) = TTRnd(p3) = 1200 Operating Systems: A Modern Perspective, Chapter 7
FCFS Average Wait Time i t(pi) 0 350 1 125 2 475 3 250 4 75 • Easy to implement • Ignores service time, etc • Not a great performer 0 350 475 900 1200 1275 p0 p1 p2 p3 p4 TTRnd(p0) = t(p0) = 350 TTRnd(p1) = (t(p1) +TTRnd(p0)) = 125+350 = 475 TTRnd(p2) = (t(p2) +TTRnd(p1)) = 475+475 = 950 TTRnd(p3) = (t(p3) +TTRnd(p2)) = 250+950 = 1200 TTRnd(p4) = (t(p4) +TTRnd(p3)) = 75+1200 = 1275 W(p0) = 0 W(p1) = TTRnd(p0) = 350 W(p2) = TTRnd(p1) = 475 W(p3) = TTRnd(p2) = 950 W(p4) = TTRnd(p3) = 1200 Wavg = (0+350+475+950+1200)/5 = 2974/5 = 595 Operating Systems: A Modern Perspective, Chapter 7
Predicting Wait Time in FCFS • In FCFS, when a process arrives, all in ready list will be processed before this job • Let m be the service rate • Let L be the ready list length • Wavg(p) = L*1/m + 0.5* 1/m = L/m+1/(2m) • Compare predicted wait with actual in earlier examples Operating Systems: A Modern Perspective, Chapter 7
Shortest Job Next i t(pi) 0 350 1 125 2 475 3 250 4 75 0 75 p4 W(p4) = 0 TTRnd(p4) = t(p4) = 75 Operating Systems: A Modern Perspective, Chapter 7
Shortest Job Next i t(pi) 0 350 1 125 2 475 3 250 4 75 0 75 200 p4 p1 W(p1) = 75 W(p4) = 0 TTRnd(p1) = t(p1)+t(p4) = 125+75 = 200 TTRnd(p4) = t(p4) = 75 Operating Systems: A Modern Perspective, Chapter 7
Shortest Job Next i t(pi) 0 350 1 125 2 475 3 250 4 75 0 75 200 450 p4 p1 p3 W(p1) = 75 W(p3) = 200 W(p4) = 0 TTRnd(p1) = t(p1)+t(p4) = 125+75 = 200 TTRnd(p3) = t(p3)+t(p1)+t(p4) = 250+125+75 = 450 TTRnd(p4) = t(p4) = 75 Operating Systems: A Modern Perspective, Chapter 7
Shortest Job Next i t(pi) 0 350 1 125 2 475 3 250 4 75 0 75 200 450 800 p4 p1 p3 p0 TTRnd(p0) = t(p0)+t(p3)+t(p1)+t(p4) = 350+250+125+75 = 800 TTRnd(p1) = t(p1)+t(p4) = 125+75 = 200 TTRnd(p3) = t(p3)+t(p1)+t(p4) = 250+125+75 = 450 TTRnd(p4) = t(p4) = 75 W(p0) = 450 W(p1) = 75 W(p3) = 200 W(p4) = 0 Operating Systems: A Modern Perspective, Chapter 7
Shortest Job Next i t(pi) 0 350 1 125 2 475 3 250 4 75 0 75 200 450 800 1275 p4 p1 p3 p0 p2 TTRnd(p0) = t(p0)+t(p3)+t(p1)+t(p4) = 350+250+125+75 = 800 TTRnd(p1) = t(p1)+t(p4) = 125+75 = 200 TTRnd(p2) = t(p2)+t(p0)+t(p3)+t(p1)+t(p4) = 475+350+250+125+75 = 1275 TTRnd(p3) = t(p3)+t(p1)+t(p4) = 250+125+75 = 450 TTRnd(p4) = t(p4) = 75 W(p0) = 450 W(p1) = 75 W(p2) = 800 W(p3) = 200 W(p4) = 0 Operating Systems: A Modern Perspective, Chapter 7
Shortest Job Next i t(pi) 0 350 1 125 2 475 3 250 4 75 • Minimizes wait time • May starve large jobs • Must know service times 0 75 200 450 800 1275 p4 p1 p3 p0 p2 TTRnd(p0) = t(p0)+t(p3)+t(p1)+t(p4) = 350+250+125+75 = 800 TTRnd(p1) = t(p1)+t(p4) = 125+75 = 200 TTRnd(p2) = t(p2)+t(p0)+t(p3)+t(p1)+t(p4) = 475+350+250+125+75 = 1275 TTRnd(p3) = t(p3)+t(p1)+t(p4) = 250+125+75 = 450 TTRnd(p4) = t(p4) = 75 W(p0) = 450 W(p1) = 75 W(p2) = 800 W(p3) = 200 W(p4) = 0 Wavg = (450+75+800+200+0)/5 = 1525/5 = 305 Operating Systems: A Modern Perspective, Chapter 7
SJN is optimal – gives minimum average waiting time for a given set of processes Shortest-Job-Next (SJN) Scheduling Operating Systems: A Modern Perspective, Chapter 7
Preemptive Schedulers Preemption or voluntary yield New Process Ready List Scheduler CPU Done • Highest priority process is guaranteed to be running at all times • Or at least at the beginning of a time slice • Dominant form of contemporary scheduling • But complex to build & analyze Operating Systems: A Modern Perspective, Chapter 7
2.0 Example of Non-Preemptive SJN Operating Systems: A Modern Perspective, Chapter 7
2.0 Example of Preemptive SJN Average waiting time = (0 + 0 + 0 + 2)/4 = 0.5 Operating Systems: A Modern Perspective, Chapter 7
Priority Scheduling Operating Systems: A Modern Perspective, Chapter 7
Priority Scheduling i t(pi) Pri 0 350 5 1 125 2 2 475 3 3 250 1 4 75 4 • Reflects importance of external use • May cause starvation • Can address starvation with aging 0 250 375 850 925 1275 p3 p1 p2 p4 p0 TTRnd(p0) = t(p0)+t(p4)+t(p2)+t(p1) )+t(p3) = 350+75+475+125+250 = 1275 TTRnd(p1) = t(p1)+t(p3) = 125+250 = 375 TTRnd(p2) = t(p2)+t(p1)+t(p3) = 475+125+250 = 850 TTRnd(p3) = t(p3) = 250 TTRnd(p4) = t(p4)+ t(p2)+ t(p1)+t(p3) = 75+475+125+250 = 925 W(p0) = 925 W(p1) = 250 W(p2) = 375 W(p3) = 0 W(p4) = 850 Wavg = (925+250+375+0+850)/5 = 2400/5 = 480 Operating Systems: A Modern Perspective, Chapter 7
Deadline Scheduling • Real Time Systems • Processes must complete their task by specific deadlines • Main performance criteria • Scheduler must have complete knowledge of service time of each process • All function must be predictable– no virtual memory • A process is admitted to ready list only if OS can guarantee deadline can be met. Operating Systems: A Modern Perspective, Chapter 7
Deadline Scheduling i t(pi) Deadline 0 350 575 1 125 550 2 475 1050 3 250 (none) 4 75 200 • Allocates service by deadline • May not be feasible 200 550 575 1050 0 1275 p1 p4 p0 p2 p3 p4 p1 p0 p2 p3 p4 p0 p1 p2 p3 Operating Systems: A Modern Perspective, Chapter 7
Round Robin (RR) Scheduling Operating Systems: A Modern Perspective, Chapter 7