Download

1 / 29
300 likes | 494 Views
MMX-accelerated Matrix Multiplication. Assembly Language & System Software National Chiao-Tung Univ. Motivation. Pentium processors support SIMD instructions for vector operations Multiple operations can be perform in parallel

E N D
MMX-accelerated Matrix Multiplication Assembly Language & System Software National Chiao-Tung Univ.
Motivation • Pentium processors support SIMD instructions for vector operations • Multiple operations can be perform in parallel • In this lecture, we shall show how to accelerate matrix multiplication by using MMX instructions
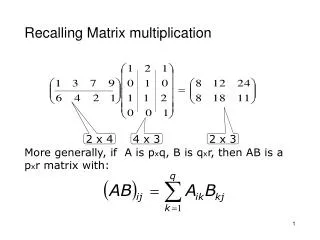
int16 vect[Y_SIZE]; int16 matr[Y_SIZE][X_SIZE]; int16 result[X_SIZE]; int32 accum; for (i = 0; i < X_SIZE; i++) { accum = 0; for (j = 0; j < Y_SIZE; j++) accum += vect[j] * matr[j][i]; result[i] = accum; } Naïve Matrix Multiplication
MMX • A collection of • new SIMD instructions • new registers • mm0~mm7, each is of 64 bits • MMX is primarily for integer vector operations
MMXTM registers mmx register float mmx char a; a 8 bits int b; b1 b2 b3 b4 64 bits 32 bits 80 bits p p+8 16 16 16 16 16 16 16 16 16 16 16 16 64 bits 64 bits 64 bits
MMX™ instructions • movd、movq—Move Doubleword、Move Quadword • punpcklbw、punpcklwd、punpckldq—Unpack Low Data and Interleave (word、doubleword) • punpckhwd—Unpack High Data and Interleave (word) LBW HBW
MMX™ instructions • pmaddwd—Multiply and Add Packed Integers (word) • paddd—Add Packed Integers (doubleword)
MMX™ for Matrix Multiply • One matrix multiplication is divide into a series of multiplying a 1*2 vector with a 2*4 sub-matrix
MMX™ for Matrix Multiply [edx] [esi] ecx elements
int16 vect[Y_SIZE]; int16 matr[Y_SIZE][X_SIZE]; int16 result[X_SIZE]; int32 accum[4]; for (i = 0; i < X_SIZE; i += 4) { accum = { 0, 0, 0, 0}; for (j = 0; j < Y_SIZE; j += 2) accum += MULT4x2 (&vect[j], &matr[j][i]); result[i..i + 3] = accum; } MMX™ for Matrix Multiply
MMX™ code for MULT4x2 • MULT4x2 movd mm7, [esi] ; Load two elements from input vector punpckldq mm7, mm7 ; Duplicate input vector: x0:x1:x0:x1 movq mm0, [edx+0] ; Load first line of matrix (4 elements) movq mm6, [edx+2*ecx] ; Load second line of matrix (4 elements) movq mm1, mm0 ; Transpose matrix to column presentation punpcklwd mm0, mm6 ; mm0 keeps columns 0 and 1 punpckhwd mm1, mm6 ; mm1 keeps columns 2 and 3 pmaddwd mm0, mm7 ; multiply and add the 1st and 2nd column pmaddwd mm1, mm7 ; multiply and add the 3rd and 4th column paddd mm2, mm0 ; accumulate 32 bit results for col. 0/1 paddd mm3, mm1 ; accumulate 32 bit results for col. 2/3
MMX™ code for MULT4x2 • Matrix states in multiplication • movd mm7, [esi] ; Load two elements from input vector • punpckldq mm7, mm7; Duplicate input vector: X0:X1:X0:X1
MMX™ code for MULT4x2 • movq mm0, [edx+0] ; Load first line of matrix • the 4x2 block is addressed through register edx • movq mm6, [edx+2*ecx] ; Load second line of matrix • ecx contains the number of elements per matrix line
MMX™ code for MULT4x2 • movq mm1, mm0 ; Transpose matrix to column presentation • punpcklwd mm0, mm6 ; mm0 keeps columns 0 and 1 • punpckhwd mm1, mm6 ; mm1 keeps columns 2 and 3
MMX™ code for MULT4x2 • pmaddwd mm0, mm7;multiply and add the 1st and 2nd column • pmaddwd mm1, mm7;multiply and add the 3rd and 4th column
MMX™ code for MULT4x2 • paddd mm2, mm0 ; accumulate 32 bit results for col. 0/1 • paddd mm3, mm1; accumulate 32 bit results for col. 2/3
MMX™ code for MULT4x2 • Packing and storing results • packssdw mm2, mm2 ; Pack the results for columns 0 and 1 to 16 Bits • packssdw mm3, mm3 ; Pack the results for columns 2 and 3 to 16 Bits • punpckldq mm2, mm3 ; All four 16 Bit results in one register (mm2) • movq [edi], mm2 ; Store four results into output vector
MMX™ code for MULT4x2 • packssdw mm2,mm2 • packssdw mm3,mm3 • Convert (shrink) signed DWORDs into WORDs
Little endian Y, Z, W,V
Memory Alignment • Memory operations for MMX must be aligned at 8-byte boundaries • 16-byte boundaries for SSE2 .data ALIGN 8 myBuf DWORD 128 DUP(?)
CPU-Mode Directives • In Irvine32.inc, the CPU mode is specified as .686P • MMX is supported since Pentium • Additionally, you should specify .mmx to use MMX instructions • If you want to use SSE2, specify .xmm
Debugging with MMX MMX/SSE2 registers are hidden unless you specify to see them
High-Resolution Counter A PC clock ticks 18.7 times every second Low resolution Use the CPU internal clock counter for high accuracy performance measurement
High-Resolution Counter RDTSC Read the CPU cycle counter +1 every clock +3000000000 every second for a 3GHz CPU The result is put in EDX:EAX readTSC PROC rdtsc ret readTSC ENDP
High-Resolution Counter • To calculate time spent in a specific interval, • Recording the starting time and finish tine • Finish-start • Time stamps are of 64 bits, SUB instruction is for up to 32-bit operands • Use SBB (sub with borrow) for implementation
SSE2 • SIMD instructions for MMX extension • Basically SSE2 and MMX are the sane, except • Registers for SSE2 are 128 bits instead of 64 bits, named by xmm0~xmm7 • 8 16-bit integers in one single register • xmm8~xmm15 are accessible only with 64-bit processors • Memory operations should be aligned at 16-byte boundaries • Use .xmm directive to enable SSE2 for MASM • Use MOVDQ instead of MOVQ for data movement
From MMX to SSE2 • Change the multiplication for 1*2 x 2*4 matrixes • 1*? To ?*? • The rest are almost the same!
Things you have to do… • Understand the code of MUL4x2 • Extend the logic to handle generic matrix multiplication • Understand alignment of memory operations • Remember to put an “EMMS” instruction by the end of your program • Not required if you are using SSE2 • Implement 1) naïve 2) MMX-based 3) SSE2-based algorithms and measure their performance