Download

1 / 24
240 likes | 249 Views
Explore how ViBE transforms video access with shot transition detection, tree representation, semantic labeling, and active browsing. Discover the framework for scalable video data management.

E N D
The ViBE Video Database System:An Update and Further Studies C. M. Taskiran, C. A. Bouman, and E. J. Delp Purdue University School of Electrical and Computer Engineering Video and Image Processing Laboratory (VIPER) Electronic Imaging System Laboratory (EISL) West Lafayette, Indiana
Outline • The content-based video access problem • The ViBE system • Temporal Segmentation and the Generalized Trace • Results • Conclusions The main result of this paper is a extended experimental study of the performance of our shot transition detection techniques
The Problem • How does one manage, query, and browse a large database of digital video sequences? • Problem Size • One hour of MPEG-1 is 675MB and 108,000 frames. • Goal : browse by content (how do you find something) • applications include digital libraries • Need for compressed-domain processing
ViBE: A New Paradigm for Video Database Browsing and Search • ViBE has four components • shot transition detection and identification • hierarchical shot representation • pseudo-semantic shot labeling • active browsing based on relevance feedback • ViBE provides an extensible framework that will scale as the video data grows in size and applications increase in complexity
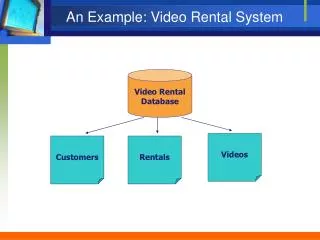
ViBE System Components Active Browsing Environment Detection and classification of shot boundaries Video sequences Shot Tree Representation User Pseudo-semantic labeling of shots
Frame by frame dissimilarity features Feature Processing list of scene changes Current Paradigm in Temporal Segmentation of Video dissimilarity measure Compressed Video Sequence frame number
Tree Representation of Shots • Single keyframe is not adequate for shots with large variation • Agglomerative clustering is used to build tree representation for shots • Shot similarity is obtained using tree matching algorithms
Pseudo-Semantic Labeling • Bridge between high-level description and low-level representation of a shot • Uses semantic classes which can be derived from mid- and low-level features, improves the description of the image content • Examples: • head and shoulders • indoor/outdoor • high action • man made/natural For each shot we will extract a vector indicating the confidence of each pseudo-semantic label
Color (UV) Segmentation EM Model Estimation Color (YUV) Segmentation General models for skin and background Head and Shoulders Feature Label • From a shot-based point of view, we want to indicate if there is a talking head in a shot • The first goal is to extract skin-like regions from each frame • With motion and texture information, each region along the shot will be labeled as a face candidate or not
Browsing with a Similarity Pyramid • Organize database in a pyramid structure • Top level of pyramid represents global variations • Bottom level of pyramid represents individual images • Spatial arrangement makes most similar images neighbors • Embedded hierarchical tree structure
Navigation via the Similarity Pyramid Zoom in Zoom out Zoom in Zoom out
Browser Interface Control Panel Similarity Pyramid Relevance Set
dissimilarity measure frame number Common Approach in Temporal Segmentation of Video Extraction of a frame-by-frame dissimilarity feature Compressed video sequence Extraction of DC frames Processing Shot boundary locations
Problems With This Approach • What type of feature(s) should be used? • How do we choose threshold(s) robustly? • Classes (cut vs. dissolve, etc.) may not be separable using one simple feature Using a multidimensional feature vector may alleviate these problems.
The Generalized Trace (GT) • The GT is a feature vector, , which is extracted from each DC frame in the compressed video sequence • DC frames for P and B frames are estimated using motion vector information • Includes features which are readily available from an MPEG stream with minimal computation • The use of the GT to detect cuts was described in Taskiran and Delp, ICASSP’98 • Binary regression tree classifier • Gelfand, Ravishankar, and Delp, PAMI, Feb. 1991
List of Features • The GT feature vector consists of • g1 : Y component • g2 : U component • g3 : V component • g4 : Y component • g5 : U component • g6 : V component • g7 : Number of intracoded MB’s • g8 : Number of MB’s with forward MV • g9 : Number of MB’s with backward MV • g10 - g12 : Frame type binary flags histogram intersections frame standard deviations Not applicable to all frames
Detection of Cuts Tree training Ground truth sequences Regression tree GT extraction and windowing Sequence to be processed Postprocessing Cut locations
Detection of Gradual Transitions First tree GT extraction and windowing Sequence to be processed Windowing Second tree Postprocessing Gradual transition locations
The Data Set • Digitized at 1.5Mb/sec in CIF format (352x240) • Contains more than 4 hours of video (35 hours in general) • 5 different program genres • 10 min clips were recorded at random points during the program and commercials were edited out • A single airing of a program is never used to obtain more than one clip (except movies)
#frames #cuts #dissolves #fades #others soap opera 67582 337 0 0 2 107150 108 6 talk show 331 1 78051 173 sports 45 0 29 news 58219 297 7 0 6 movies 54160 262 15 6 1 cspan 90269 95 19 0 0 TOTAL 455431 1495 196 7 42 Data Set Statistics
Experiments • Use a cross-validation procedure to determine performance for each genre G {soap, talk, sports, news, movies, cspan} for i = 1 to 4 randomly choose S1 and S2, both not in G train regression tree using S1 and S2 process all sequences in G using this tree average performance over G average the four stes of values to find performance for G • Window size = 3 frames; threshold = 0.35
Results Tree Classifier Sim. Thresholding Sliding Window Detect Detect Detect FA FA MC MC FA MC soap 0.941 13.3 0.916 99 0 0 0.852 24 0 0.942 talk 32.3 0.950 45 7.5 0.968 1 171 15 0.939 82.5 sports 0.785 59 34.8 1 0.925 251 73 news 0.958 38.0 0.886 61 0.75 0 0.926 212 1 movies 0.821 43.3 0.856 25 2 0 0.816 25 3 cspan 0.915 54.3 0.994 40 8.5 0 0.943 3 20
Conclusion • Double stage tree classifier provides a good framework for detection of dissolves and fades • Pseudo-Semantic labeling is a fast, feature-based approach to content description • Relevance feedback coupled with the similarity pyramid forms a powerful active browsing tool • Performance of the regression tree classifier is very robust to changes in program content. • The performance is not affected much by the choice of the training sequences.