Download

1 / 30
300 likes | 431 Views
Caio César Neves de Oliveira ccno Mário Barbosa de Araújo Júnior mbaj. Protein network based prediction of domain-domain and domain-peptide interactions. Motivação. Informações podem ser extraidas das redes de interação proteína-proteína Falta detalhes dessas interações

E N D
Caio César Neves de Oliveira ccno Mário Barbosa de Araújo Júnior mbaj Protein network based prediction of domain-domain and domain-peptide interactions
Motivação • Informações podem ser extraidas das redes de interação proteína-proteína • Falta detalhes dessas interações • Esse conhecimento poderá ser uma arma para o estudo de doenças e de produção de remédios
Interações da proteína • Interações domínio-domínio • Gerais • Interagem • Específicas • Interagem ou não • Dependem do contexto • Expressão dependende do ciclo • Localização da célula • Características específicas da sequência de aminoácidos
Métodos para predizer interações • Métodos representativos • Association • Maximum Likelihood Estimation • Domain Pair Exclusion Analysis • Parsimonious Explanation • Integrative approach
Association method • Detecta pares de domínios super-representados • Atribui Score de frequência para cada par • Se Pi é observado freqüentemente no domínio i na rede de interação e Pij é observado freqüentemente no par (i, j), temos o score • Score é 2 para completa interação (fusão), caso contrário é 0
Association method • Outra forma de calcular score • É mais precisa por considerar mais fatores N – número de arestas na rede de interação proteína-proteína #exk – número de experimentos distintos na rede que detecta interações da proteína k #ppairsk – número de contatos do potencial domínio na interação da proteína k #ppairskij - número de contatos do potencial domínio entre o par (i, j) na interação da proteína k Pi – frequência do domínio i na rede de proteínas
Maximum Likelihood Estimaton (MLE) • Para cada par de domínio, ele gera a probabilidade de interação entre o domínio, • Maximiza a probabilidade da rede de interação • Permite levar em conta falso positivos e falso negativo da informação • Interações proteína-proteína e domínio-domínio são tratadas como variáves aleatórias
Maximum Likelihood Estimaton (MLE) • Variáveis aleatórias • PAB • 1 – se A e B interagem • 0 – caso contrário • Dij • 1 – se o domínio i e j interagem • 0 – caso contrário • Assumindo que duas proteínas interagem sse pelo menos um dos potenciais pares de domínios interagem de fato
Maximum Likelihood Estimaton (MLE) • Probabilidade de interação entre duas proteínas A e B λij = Pr(Dij = 1) – denota a probabilidade do domínio i interagir com j Dij ϵ PAB - Conjunto de potencial domínio que entram em contato com o par de proteínas (A, B)
Maximum Likelihood Estimaton (MLE) • OAB descreve a observação do experimento de interação • 1 para interação observada • 0 para caso contrário • Denotando • fp – false positive • fn – false negative
Maximum Likelihood Estimaton (MLE) • O objetivo do método MLE é estimar o parâmetro λijparamaximizar a função de probabilidade L, dada por
Maximum Likelihood Estimaton (MLE) • Num estudofeitopor Deng e seuscolegaseles estimaram que se fp = 2.5E-4 e fn = 0.80 osvaloresλij seria computado com a expectativa máxima, isso maximiza L. Em cada interação t, valores de λij^(t-1) é usado para computar Pr(OAB =1 | λ^(t-1))
Maximum Likelihood Estimaton (MLE) Expectation Step: Maximization Step: E(Dij^(AB)) – probabilidade do domínio (i, j) executar a interação emtre (A, B) Nij – número de par de proteínas na rede que possui (i, j) como potencial par de domínios
Maximum Likelihood Estimaton (MLE) • Uma limitação do MLE é a dificudade em detectar interações de domínios específicos • O algoritmo considera que existem muitos fn
Domain Pair Exclusion Analysis (DPEA) • Este método utiliza MLE como subrotina • Executa o MLE várias vezes • Corrige o problema de domínios específicos de MLE • Bloqueia uma interação domínio-domínio por vez e analiza o grau de redução da esperança E proteína-proteína • Supera o desempenho de Association e MLE
Parsimonious Explanation (PE) • Um problema de otimização de programação linear
Parsimonious Explanation (PE) • PW-Score • Filtra predições (otimiza) • São baseados nas seguites observações • Interações com muitas testemunhas são mais fáceis de estarem corretas do que as que possuem poucas • Interações domínio-domínio tem sua pontuação relacionada à frequência de ocorrências • Pw-score penaliza interações promíscuas e incentiva interações com muitas testemunhas • Método com excelentes resultados
Integrative approach • Abordagem diferente • Informações da interação da proteína • Composição do domínio da proteína • Método baseado nesses principios • IntegrativeBayesian(IB)
Integrative Bayesian (IB) • Espectativa de interação de pares de domínios são computado separadamente • Levedura • Verme • Mosca de fruta (drosófila) • Humano • Scores obtidos utilizando MLE • Pr(Dij =1) como score
Integrative Bayesian (IB) • Os resultados obtidos pelas quatro redes são considerados quatro pedações independentes • Utiliza a base de dados Gene Ontology (GO) como base do algoritmo • Desvantagem, pois dados novos sem estudos prévious não podem ser utilizados nesse algoritmo Nij – número de par de proteínas na rede que possui (i, j) como potenciais contatos domínios
Validação dos Métodos Sugeridos • Pares de domínios não específicos versus Pares de dominós específicos • Testar para cada par de proteínas que interagem o par de domínios que tem maior score e comparar com o iPFAM • Medida de performance: • PPV = valor de predição positiva
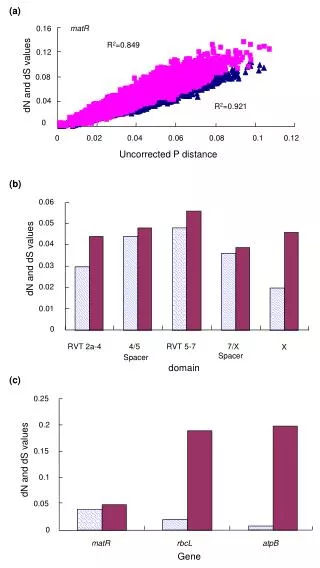
Resultados • Métodos aplicados a 1780 proteínas que interagiram Guimarães e colegas
Descobrindo Rede Fosforilização • Motifs sozinhos são insuficientes para identificar as enzimas responsáveis pela fosforilizaçãode locais correspondentes na célula • NetworKIN algoritmo para predição de redes de fosforilização
Conclusão • Poucas pesquisas na área • Muitos dados não analisado • No caso de interações domínio-peptídeo existe poucos bancos de dados para se fazer pesquisas
Referências • [1] Protein network basedpredictionofdomain-domainanddomain-peptideinteractions, KatiaGuimaraesand Tereza Przytycka. • Systematicdiscoveryofnewrecognitionpeptidesmediatingproteininteraction networks, NeduvaandLinding