Download

1 / 1
10 likes | 140 Views
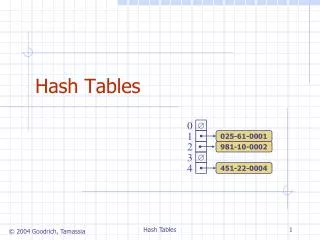
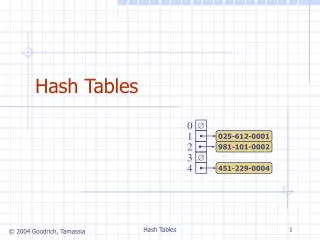
Access-Efficient Balanced Bloom Filters. Yossi Kanizo (Technion), David Hay (Hebrew Univ.), Isaac Keslassy (Technion). Motivation. Our Proposal. Classical Bloom Filters need a significant number of memory accesses.

E N D
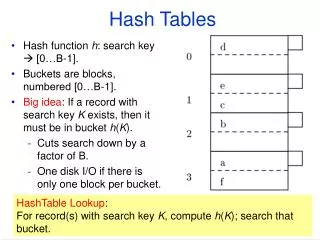
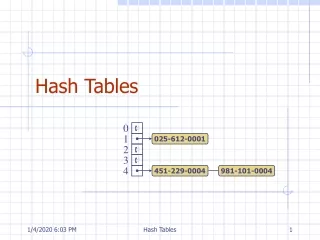
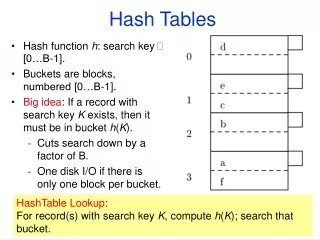
Access-Efficient Balanced Bloom Filters Yossi Kanizo (Technion), David Hay (Hebrew Univ.), Isaac Keslassy (Technion) Motivation Our Proposal • Classical Bloom Filters need a significant number of memory accesses. • Bloom Filter with 30 bits per element 30・ln 2 ≈ 21 memory accesses. • Each memory access may be to a distinct memory block Energy- and cache-inefficient. • Blocked Bloom Filter [Putze et al.]: Choose a memory block first; then local Bloom Filter within each block. • Might cause imbalance between memory blocks Efficient, but poor false positive rate. Evaluation • Balance the load between the blocks using multiple hash functions. • Upon a query, an element might be found in more than one bucket. • Objective: minimize the average number of buckets needed to be checked, ensuring the optimal balancing between the buckets. • In addition, restrict the worst-case number of buckets need to be checked. • Utilize an overflow list (in CAM) of size to mitigate such extreme situations. • Two orders of magnitude FPR improvement upon Blocked Bloom Filter, for a memory block size of 256 bits MHT with an overflow list size 0.49% and only 1.2 memory accesses per element. • All results were confirmed using real-life traces. Model Lower Bound – Basic Idea Upper Bounds Example:The Balanced Bloom Filter • - The occupancy of bucket , given buckets, element, and a balancing scheme (random variable). • - General cost function mapping bucket occupancy to its cost. • Overall balancing quality: • The specific cost function for Bloom filter is FPR: • Given and , we consider an initial insertion of distinct elements. • Then, we remove elements from the most occupied buckets, until exactly elements are left. • Looks like “pushed-back” Poisson distribution. • Valid for any convex cost function . • Upon a query, up to hash functions are used one by one, where the next hash is used only if the occupancy of the mapped bucket exceeds some threshold. • More specifically, the following schemes are used: • A simple scheme (using only a singlehash function). • A sequential scheme, using hashfunctions with uniform distribution. • A Mutli-level Hash-Table scheme (MHT),divides the memory into subtables with a single hash function for each subtable. • Based on Multi-level Hash Tables (MHT). • Using 3 subtables of (4,2 and 1 memory blocks). • In each memory block, 2 bits are saved for a counter so bucket occupancy can be determined.