Download
1 / 1
10 likes | 137 Views
Regularized Off-Policy TD-Learning Bo Liu, Sridhar Mahadevan, University of Massachusetts Amherst, {boliu, mahadeva}@cs.umass.edu Ji Liu , ji-liu@cs.wisc.edu. MSBE. MSPBE. Problem Setting:

E N D
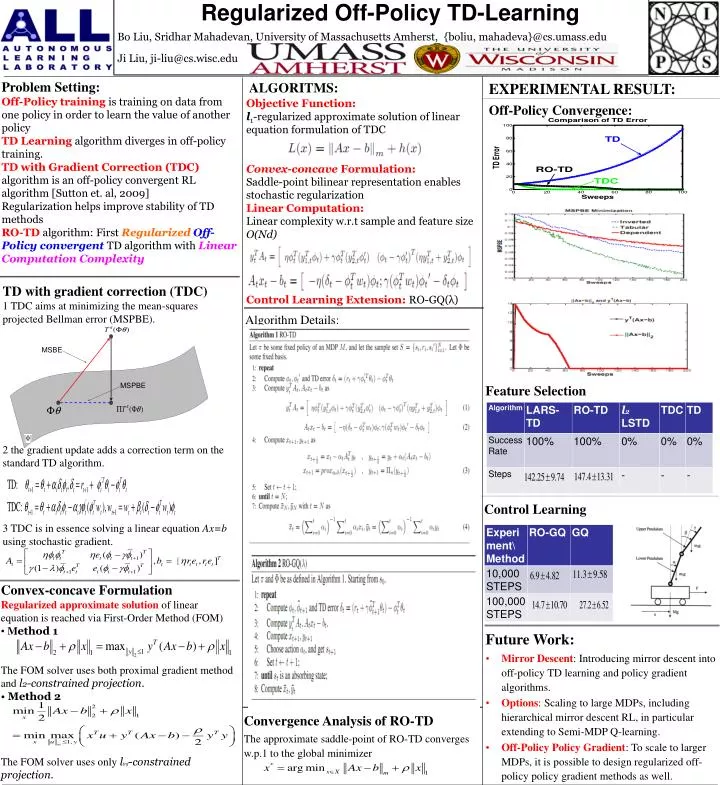
Regularized Off-Policy TD-Learning Bo Liu, Sridhar Mahadevan, University of Massachusetts Amherst, {boliu, mahadeva}@cs.umass.edu Ji Liu, ji-liu@cs.wisc.edu MSBE MSPBE Problem Setting: Off-Policy training is training on data from one policy in order to learn the value of another policy TD Learning algorithm diverges in off-policy training. TD with Gradient Correction (TDC) algorithm is an off-policy convergent RL algorithm [Sutton et. al, 2009] Regularization helps improve stability of TD methods RO-TD algorithm: First RegularizedOff-Policy convergentTD algorithm with Linear Computation Complexity ALGORITMS: EXPERIMENTAL RESULT: Objective Function:l1-regularized approximate solution of linear equation formulation of TDC Convex-concave Formulation: Saddle-point bilinear representation enables stochastic regularization Linear Computation: Linear complexity w.r.t sample and feature size O(Nd) Control Learning Extension: RO-GQ(λ) Off-Policy Convergence: TD with gradient correction (TDC) 1 TDC aims at minimizing the mean-squares projected Bellman error (MSPBE). 2 the gradient update adds a correction term on the standard TD algorithm. 3 TDC is in essence solving a linear equation Ax=b using stochastic gradient. Algorithm Details: Feature Selection Feature Selection Control Learning Convex-concave Formulation Regularized approximate solution of linear equation is reached via First-Order Method (FOM) • Method 1The FOM solver uses both proximal gradient method and l2-constrained projection. • Method 2 The FOM solver uses only linf-constrained projection. • Future Work: • Mirror Descent: Introducing mirror descent into off-policy TD learning and policy gradient algorithms. • Options: Scaling to large MDPs, including hierarchical mirror descent RL, in particular extending to Semi-MDP Q-learning. • Off-Policy Policy Gradient: To scale to larger MDPs, it is possible to design regularized off-policy policy gradient methods as well. Convergence Analysis of RO-TD The approximate saddle-point of RO-TD converges w.p.1 to the global minimizer



















