Download

1 / 97
970 likes | 1.27k Views
Data-Tier Aufgaben und Dienste. Arno Schmidhauser Letzte Revision: Juli 2006 Email: arno.schmidhauser@bfh.ch Webseite: http://www.sws.bfh.ch/db. I Übersicht. Aufgaben und Dienste.

E N D
Data-Tier Aufgaben und Dienste Arno Schmidhauser Letzte Revision: Juli 2006 Email: arno.schmidhauser@bfh.ch Webseite: http://www.sws.bfh.ch/db
Aufgaben und Dienste Dieses Skript erläutert Aufgaben und Dienste des Data-Tier, die unmittelbar für die Anwendungsentwicklung in Multi-Tier-Applikationen wichtig sind: • Transaktionssicherheit • ACID-Transaktionen • Concurrency Control • Locking • Versioning • Timestamping • Lokalitätstransparenz • Verteilte Daten • Datenbereitstellung • OLTP und OLAP Abfragen • Replikation, Warehouse-Befüllung OLTP und OLAP-Bedürfnisse Business Tier Web Tier Data Tier Client Tier Data Watehouse-Srvices Data Warehouse-Clients
Was ist eine Transaktion • Aus logischer Sicht ist eine Transaktion ein Arbeitspaket, das einen geschäftlichen Nutzen erzeugt. • So klein wie möglich. • so gross wie nötig, um alle Integritätsbedingungen einhalten zu können. • Aus technischer Sicht ist eine Transaktion eine Folge von Lese- und Änderungsoperationen in der Datenbank, mit einem definierten Beginn und einem definierten Abschluss. • Die Transaktionsverwaltung ist eine der Kernaufgaben eines Datenbanksystems.
ACID-Regel • Das Datenbanksystem garantiert für eine Transaktion folgende Eigenschaften: A Atomarität C Konsistenz I Isolation D Dauerhaftigkeit Diese Eigenschaften werden als ACID Regel bezeichnet.
Arbeiten mit Transaktionen • Jeder lesende oder schreibende Zugriff auf die Datenbank kann nur innerhalb einer Transaktion stattfinden. • Eine Transaktion beginnt explizit mit einem "begin transaction" Befehl oder implizit mit dem ersten SQL-Befehl. • Eine Transaktion wird nur mit dem "commit"-Befehl korrekt abgeschlossen. Andernfalls gilt sie noch nicht als korrekt beendet. • Eine Transaktion kann explizit mit "rollback" oder implizit durch ein äusseres Ereignis abgebrochen werden.
Das Recovery-System • Zweck • Logfile • Fehlerbehebung
Zweck des Recovery-Systems • Das Recovery-System eines DBMS enthält alle Hilfsmittel zum Wiederherstellen eines korrekten Datenbank-zustandes nach • Transaktionsfehlern (Rollback) • Systemfehlern (Crash des Serverprozesses) • Das Recovery-System garantiert die Atomarität und Dauerhaftigkeit einer Transaktion (ACID Regel). • Das Recovery-Systems basiert auf dem Führen eines Logfiles, in welchem Änderungen protokolliert werden. • Abschätzen und Überwachen der Grösse und Festlegen des Speicherortes für das Logfile sind zwei wichtige Aufgaben der Datenbank-Administration
Fehlerarten • Transaktionsfehler • Rollback-Befehl durch Applikation • Verletzung von Integritätsbedingungen • Verletzung von Zugriffsrechten • Deadlock • Verbindungsunterbruch oder Client-Crash • Systemfehler • Stromausfall, Hardware- oder Memory-Fehler
Ablauf von Modifikationsbefehlen SQL-Befehl eines Clients 2. Neue Datenwerte Workspace 1. Alte und neueDatenwerte Checkpoint (Gelegentlich) Logfile DB-Storage
Logging, Beispiel M11 T1 M21 M22 T2 M31 M32 T3 M42 M41 T4 Zeit Checkpoint Systemfehler BOT T1 M11 CMT T1 BOT T2 M21 BOT T3 M31 BOT T4 M41 B_CKPT (T2,T3,T4) E_CKPT (T2,T3,T4) M22 CMT T2 M32 RBK T3 M42 Logfile
Behebung von Transaktionsfehlern • Bei einem Transaktionsfehler (Rollback) werden aus den rückwärts verketteten Transaktionseinträgen im Logfile die alten Daten (Before Images) in den Cache übertragen. • Das Datenbanksystem führt hierzu für jede laufende Transaktion einen Verweis auf den letzten Log- Eintrag mit. Der Transaktionsabbruch wird im Logfile ebenfalls protokolliert. • Beispiel: Für Transaktion T3 müssen die Before-Images von M31 und M32 zurückgeladen werden.
Behebung von Systemfehlern • Gewinner- und Verlierer-Transaktionen ermitteln • Verlierer-Transaktionen mit Hilfe der Before-Images zurücksetzen • Gewinner-Transaktionen mit Hilfe der After-Images noch einmal durchführen • Checkpoint durchführen • Beispiel • Gewinner: T2 -> M22 nachspielen. • Verlierer: T3 und T4 -> M31, M41 zurücksetzen.
Concurreny Control • Zweck • Serialisierbarkeit • Neue Methoden
Ziel des Concurrency Control • Einerseits: Isolation (I-Bedingung der ACID Regel) • Änderungen am Datenbestand dürfen erst bei Transaktionsabschluss für andere sichtbar sein. • Die parallele Ausführung von Transaktionen muss bezüglich Datenzustand und bezüglich Resultatausgabe identisch mit der seriellen Ausführung von Transaktionen sein. • Andererseits: Parallelität • Eine Datenbank muss mehrere Benutzer(-prozesse) gleichzeitig bedienen können und es sollen möglichst wenig Wartesituationen entstehen. • Auch für Middleware (Appserver) gilt: Der gemeinsame Referenzpunkt für Datenobjekte ist der Data-Tier.
Transaktion 1 1.1 select * from Kundewhere name = "Muster" 1.2 delete from Kunde where kunr = :kunr 1.3 delete from Bestellungwhere kunr = :kunr commit Transaktion 2 2.1 select * from Kunde where where name = "Muster" 2.2 select * from Bestellung where kunr = :kunr commit Serialisierbarkeit, Beispiel Die folgenden zwei Transaktionen müssen so gesteuert werden, dass der Schritt 1.3 nicht zwischen 2.1 und 2.2 zu liegen kommen.
Serialisierbarkeit ff Unter der Annahme, dass die Datenbank keine Synchro-nisationsmittel einsetzt und jedes SQL-Statement ein atomarer Schritt ist, sind verschiedene zeitliche Abläufe der beiden Transaktionen denkbar: • 1.1 2.1 1.2 2.2 1.3 (k) • 1.1 2.1 1.2 1.3 2.2 (f) • 1.1 2.1 2.2 1.2 1.3 (k) • 1.1 1.2 2.1 1.3 2.2 (f) • 1.1 1.2 2.1 2.2 1.3 (f) • 1.1 1.2 1.3 2.1 2.2 (s) • 2.1 1.1 1.2 2.2 1.3 (k) • 2.1 1.1 2.2 1.2 1.3 (k) • 2.1 1.1 1.2 1.3 2.2 (f) • 2.1 2.2 1.1 1.2 1.3 (s)
Locking • Locking ist die häufigste Technik zur Gewährleistung der Serialisierbarkeit. • Für das Lesen eines Datensatzes wird ein S-Lock gesetzt • Für das Ändern, Löschen, Einfügen wird ein X-Lock gesetzt. • Für das Einfügen wird zusätzlich ein S-Lock auf der Tabelle gesetzt. • Die gesetzten Locks sind gemäss einer Verträglichkeitstabelle untereinander kompatibel oder nicht: Angeforderte Sperre Angeforderte Sperre wird gewährt (+) oder nicht gewährt (-) Bestehende Sperre
Deadlocks • Beim Sperren von Daten können Deadlocks auftreten. Der Deadlock ist nicht ein logischer Fehler, sondern bedeutet: • Es gibt keinen Weg mehr, die anstehenden Transaktionen so zu steuern, dass ein serialisierbarer Ablauf entstehen wird. • Eine der beteiligten Transaktionen wird daher zurückgesetzt, so dass für die übrigen wieder die Chance besteht, gemäss Serialisierbarkeitsprinzip abzulaufen.2004.ppt#121. Serialisierbarkeit
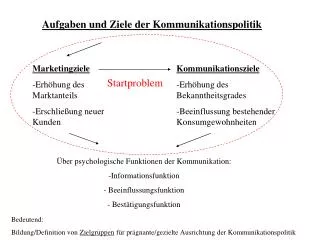
Isolationsgrade • Eine unter allen Umständen garantierte Serialisierbarkeit kann die Parallelität empfindlich einschränken. Ist zum Vornherein bekannt, dass gewisse Inkonsistenzen aufgrund der Business-Logik gar nicht auftreten können, oder allenfalls in Kauf genommen werden sollen, können die Locking-Massnahmen des DBMS gelockert werden. • SQL definiert deshalb vier Isolationsgrade beim Lesen von Daten: Modus Inkonsistenzen SERIALIZABLE keine Inkonsistenzen REPEATABLEREAD Phantom-Problem READCOMMITTED Lost-Update READUNCOMMITTED Lesen unbestätigter Daten Paralleliät Isolation
Phantom-Problem Hier tauch neuer Datensatz auf
Lost-Update Änderungen von T2 gehen beim Update von T1 verloren !
Demo Auswirkung des Isolationsgrades auf Transaktions-Durchsatz • Die Einstellung des Isolationsgrades hat bei intensiven genutzten Systemen (J2EE-Appservern) grosse Auswirkungen auf den Transaktionsdurchsatz, die Deadlockhäufigkeit und das Auftreten von Inkonsistenzen. TransaktionsSimulator.doc
Neue Methoden • Range Locks: Entschärft ganz entscheidend die Phantomproblematik und erlaubt in den meisten Fällen von OLTP das Arbeiten im Modus SERIALIZABLE. • Datensatz-Versionierung: Erlaubt ein vollständiges stabiles Lesen von Daten und Vermeidung des Phantom-Problems, ohne Anwendung von Locks.
Range Locks (1) • Range Locks werden für die Realisierung des Isolation Levels SERIALIZABLE verwendet. • Mit Range Locks werden Datensätze nach einer logischenBedingung und nicht nur rein physisch gesperrt. • Mit Range Locks kann das Phantom Problem elegant gelöst werden. • Voraussetzung: Die Abfragebedingung enthält einen oder mehrere Teile, welche über einen Index evaluiert werden können. Beispiel: select * from Reservationwhere resDatum > '1.1.2004' and resDatum < '31.12.2004'
Range Locks (2) Der Range Lock werden auf Index-Einträge gesetzt, nicht auf Datensätze, wie gewöhnliche Locks. Datensatz mit resDatum 1.6.2005 select * from Reservationwhere resDatum < '31.12.2004'and resDatum > '1.1.2004' Datensatz mit resDatum 1.6.2004 Datensatz mit resDatum 1.6.2003 Datensätze mit gesetztem Range Lock Datensatz mit resDatum 1.6.2002 Wirkungsbereich des Range Locks
Concurrency Control mit Versionen (1) • Von einem Datensatz werden zeitweilig mehrere Versionen geführt, mit folgenden Zielen: • Eine Transaktion sieht einen committeten Datenbankzustand bezogen auf den Zeitpunkt des Starts. Dieser Zustand bleibt über die ganze Transaktionsdauer eingefroren. • Schreibbefehle werden durch Lesebefehle nicht behindert und umgekehrt. • Schreibbefehle beziehen sich immer auf die neueste Version eines Datensatz in der Datenbank, und verwenden gegebenenfalls einen Lock, um diese zu reservieren.
6 1 Lesende Transaktion/Befehl, TNC = 6 4 Lesende Transaktion/Befehl, TNC = 5 2 Schreibende Transaktion/Befehl, TNC = 4 Lesende Transaktion/Befehl, TNC = 3 Kopie des Datensatz commit 5 3 Datensatz X, TNC = 2 Datensatz X, TNC = 4 7 Kann gelöscht werden Versionen, Leser gegen Schreiber Datensatz X, TNC = 2 Datensatz X, TNC = 1
4 Änderungsbefehl 1 2 Datensatz X, TNC = 2 Schreibende Transaktion, TNC = 3 Schreibende Transaktion, TNC = 4 3 Datensatz X, TNC = 2 6 Datensatz X, TNC = 3 Kopie Datensatz Kopie Datensatz 7 commit: abort, weil TNC 2 max TNC im Pool commit: ok, weil TNC 2 = max TNC im Pool 5 Versionen, Schreiber gegen Schreiber Datensatz X, TNC = 2 Datensatz X, TNC = 1
Demo Isolationsverbesserung mit Versionenverfahren in SQL Server 2005 • Zusätzlicher Isolation Level SNAPSHOT : Ergibt serialisierbare Transaktionen ohne Verwendung von Lesesperren. Änderungskonflikte mit anderen Transaktionen werden beim Commit festgestellt. • Isolation Level READ COMMITTED: Mit Versionenverfahren realisiert.
Concurrency Control mit Zeitstempeln • Zeitstempel + Daten in die Applikation lesen. • Beim Zurückschreiben werden Zeitstempel verglichen:Bei Veränderung Abbruch der Transaktion.
Zeitstempel in SQL create table T ( ts integer default 1, id integer primary key, data ... ) select ts asts_old, id, data from T where id = id_gesucht A -- dataändern B update T set ts = ts_old + 1, data = ... where id = id_gesucht and ts = ts_old C if rowcount = 0 then rollback D
OLTP- und OLAP-Applikationen • OLTP = Online Transaction Processing • OLAP = Online Analytical Processing • Der Fokus von Java EE Applikationen liegt stark im OLTP-Bereich: • Kurze, einfache, effiziente Transaktionen für das laufende Geschäft. • Das extremste Gegenstück zum OLTP-Betrieb ist das Data Warehouse: • Periodische Extraktion und Aufbereitung von Aktualdaten in spezielle Datenbanken, den Data Warehouses. • Aufbewahrung von historischen Daten. • Auswertung in die Vergangenheit und die Zukunft. • OLAP-Anfragen nehmen eine Zwischenposition an: • Zusammenfassende Informationen, in Echtzeit aus den Aktualdaten erzeugt. • OLAP-Anfragen gehören mehr und mehr zu OLTP-Applikationen.
Beispiele OLTP-Transaktionen Kundenlogin prüfen select count(*) from Kunde where username = eingegebener Name and password = eingegebenes Passwort Anzeigen von Artikeln select * from Artikel where idGruppe = gewählte Gruppe order by name Bestellung einfügen insert Bestellung (idKunde, idArtikel, menge, bestellDatum ) values ( vom Benützer eingegebene Daten )
Beispiel 1, OLAP-Transaktion Welche Artikel wurden wie oft von Kunden gekauft, die auch den Artikel 1 gekauft haben? select b2.idArtikel, count(*) from Bestellung b1, Bestellung b2 where b1.idArtikel = 1 and b2.idArtikel != b1.idArtikel and b1.idKunde = b2.idKunde group by b2.idArtikel
Beispiel 2, OLAP-Transaktion Zeige für jeden Artikel, wieviele Verkäufe im Jahr 2007 realisiert wurden: Absolute Menge, relativ zu allen verkauften Artikeln, relativ zu allen Verkäufen in der Artikelgruppe. select artikel, gruppe, verkäufe, verkäufe / sum(verkäufe) over() anteilGesamt, verkäufe / sum(verkäufe) over( partition by gruppe ) anteilGruppe from ( select a.name artikel, g.name gruppe, cast ( sum(b.menge) as float ) verkäufe from Bestellung b, Artikel a, Gruppe g where b.idArtikel = a.idArtikel and a.idGruppe = g.idGruppe and datepart( year, bestellDatum ) = 2007 group by a.name, g.name ) as Verkauf order by artikel
Definition • Eine verteilte Datenbank umfasst ein einziges Datenmodell, dessen Daten auf mehrere Datenbankserver (Knoten)aufgeteilt werden. Jede Information ist nur auf einem Knoten vorhanden. • Die einzelnen Knoten und das verbindende Netzwerk sind technisch unabhängig lebensfähige Komponenten. • Das Managementsystem für eine verteilte Datenbank muss mit zeitweise ausfallenden oder nicht erreichbaren Knoten umgehen können. Knoten = Datenbankserver = Resource Manager RM
Warum verteilte Datenbanken? • Zusammenwachsen von vormals unabhängigen Systemen zu einem aus Benutzer- oder Applikationssicht einzigen System. • An gewissen Knoten werden meist nur bestimmte Daten benötigt. Ein Zugriff auf die anderen Knoten ist nur gelegentlich notwendig. • Aus Sicherheits- oder gesetzlichen Überlegungen werden bestimmte Daten nur auf bestimmten Knoten abgelegt.
Verteilte Datenbank, Beispiel Gesamtsystem Knoten 1 Knoten 3 Knoten 2
Zugriff auf verteilte DB, Beispiele • Kunde aufnehmen • erfordert neuen Eintrag in Knoten 1 • Kunde löschen • erfordert Löschungen in Knoten 1, 2 und 3 • Artikelstamm ändern • erfordert Änderungen in Knoten 2 • Artikel bestellen • erfordert Lesen in 1 und 3, Änderungen in 2
Zugriffsarchitektur Explizite Architektur • Eine "Drittpartei", der Transaktions-manager, steuert die beteiligten Datenbanken. • Oft für produktheterogene, verteilte Datenbanken, z.B. mit Java EE Transparente Architektur • Einer der beteiligten Knoten spielt den Master und steuert die beteiligten Datenbanken. • Oft für produkthomogene verteilten Datenbanken. Applikation Applikation Knoten 1 AppServer/Transaktionsmanager Knoten 3 Knoten 1 Knoten 2 Knoten 2 Knoten 3