Download

1 / 70
710 likes | 986 Views
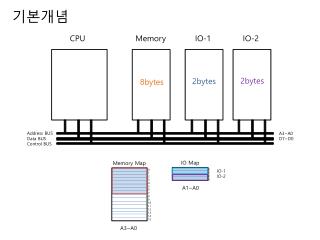
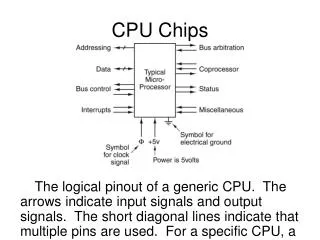
CPU. Maszyna Turinga. Architektura von Neumanna. Architektura von Neumanna. Instrukcje i dane zapisane w tej samej pamięcie Pamięć jest sekwencyjnie adresowana Pamięć jest jednowymiarowa

E N D
Architektura von Neumanna • Instrukcje i dane zapisane w tej samej pamięcie • Pamięć jest sekwencyjnie adresowana • Pamięć jest jednowymiarowa • Znaczenie danych nie jest zapisane w pamięci znaczenie pojawia się w drodze interpretacji (np. przez CPU) • W szczególności nie są rozróżniane dane i kody rozkazów
Architektura von Neumanna • Wczytywane jedno słowo pamięci na raz • Cykl wykonania instrukcji: • wczytanie kodu (Fetch) • Zdekodowani i pobranie z pamięci dodatkowych argumentów (Decode) • Egzekucja (Execute)
Operacje • Opis operacji do wykonania składa się z kodu operacji i ew. argumentów • I kod i dane są liczbami, ale kiedy mówimy o kodach, zazwyczaj używamy tzw. mnemoników: ADD, SUB, MUL, DIV, AND, OR, itp. • Rozkaz do wykonania ma więc zazwyczaj postać: Kod_operacji [argument(y)], np.:ADD AX, 7INC BXJMP 32
Operacje Argumenty czasem dane są jawni, czasem niejawnie (np.: INC AX – to dodawanie z niejawnym drugim argumentem 1, PUSHF – argumenty w ogóle niejawne)
Kodowanie operacji Kodowanie operacji – sposób ich zapisania jako liczby – dość ważna decyzja projektowa (później)
Architektura von Neumanna • Generalnie rozkazy są wczytywane z pamięci i wykonywane sekwencyjnie • Pozycja, z której został wczytany aktualnie realizowany rozkaz (adres pamięci) wskazywana jest przez tzw. IP (Instruction Pointer) czy też PC (Program Counter) • Wczytanie kodu rozkazu oraz ew. następujących po nim argumentów (operandów) zwiększa wartość licznika o stosowną liczbę pozycji • Niektóre rozkazy (np. skoki) – dość drastycznie zmieniają IP
ISA • Wynikiem wszystkich decyzji dotyczących tego, jaki powinien być zbiór rozkazów, jak powinny być kodowane, w jaki sposób mają być określane argumenty jest tzw. ISA – Instruction Set Architecture – Architektura Listy Rozkazów
Typowe składowe ISA • Ilość i sposób korzystania z rejestrów • Zestaw rozkazów • Tryby adresowania • Sposób kodowania rozkazów • Sposób kodowania danych
Rejestry • Pamięć wewnętrzna – bardzo szybka (i bardzo droga) • Nie mylić z cache • Rejestry mogą być specjalizowane lub uniwersalne • Odwołania do pamięci mogą być realizowane albo bezpośrednio, albo za pomocą rejestrów
Tryby adresowania • Dane następujące po kodzie operacji nie muszą być bezpośrednimi wartościami • Bardzo często są adresem pamięci, gdzie znajduje się wartość argumentu (koncept zmiennej) • Adres nie musi być podany wprost, może być podany jako przemieszczeni, jako adres indeksowany, itp.
Skoki warunkowe • Pozwalają na realizację takich struktur języków wyższego poziomu, jak pętle i instrukcje warunkowe, a więc – podstawowych konstrukcji programistycznych
Realizacja pętli repeat ... ... ... until a > 0 pp: ... ... mov ax, a cmp ax, 0 jle pp
Realizacja instrukcji warunkowej mov ax, a sub ax, b jg else ... ... jmp end else: ... ... end: ... if a > b then ... else ... end if;
Kodowanie operacji • Jeśli rozkazy operują na rejestrach, a rejestrów nie jest dużo, można zastosować bardziej zwarte kodownie – nie potrzeba całych 16-tu bitów na zakodowanie jednego z ośmiu rejestrów – wystarczy 3 bity • Z drugiej strony jednym z argumentów może być 16-bitowa liczba
Kodowanie operacji • Czasem stosuje się kodowanie o zmiennej długości • W 80x86 kod operacji może mieć od 1 do 17 bajtów długości • W RISC’ach stosuje się generalnie kodowanie o stałej długości • To jest ważne zagadnienie – pamięć! (np. dla osadzonych – bardzo ważne)
Bloki wykonawcze • ALU – jednostka arytmetyczno-logiczna – odpowiedzialna za realizację operacji arytmetyczno-logicznych: AND, ADD, OR, SUB, itp... • Shifter – odpowiedzialny za realizację przesunięć bitowych – SHR, SHL, ROR, ROL • Comp – odpowiedzialny za realizację komparacji używanych w skokach warunkowych: EQ, NEQ, LE, GT, GE, LT, itp. • Np. skoki są w całości realizowane przez blok kontroli
Kodowanie rozkazów • Pojedyncze słowo
Kodowanie rozkazów • Podwójne słowo
Metoda top-down • Najpierw architektura połączenia CPU-MEM • Po drodze – architektura MEM • Ustalenie definicji wspólnych dla całego CPU • Później architektura połączenia bloków wewnątrz CPU • Na koniec realizacja bloków wewnątrz CPU
Library • Dwie domyślne biblioteki (nie trzeba deklarować ich użycia): • STD (bit, bit_vector, Boolean, itp...) • WORK (pakiety zadeklarowane w plikach VHDL w bieżącym projekcie) – biblioteki WORK nie trzeba deklarować, ale pakiety – tak (np. use work.cpu_lib.all;)
Biblioteki • deklaracja library nazwa; posługuje się nazwą logiczną biblioteki. To, jak związać nazwę logiczną z odpowiednimi plikami VHDL rozwiązane jest w każdym pakiecie realizującym VHDL po swojemu