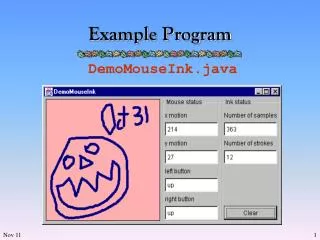
Download

1 / 29
290 likes | 515 Views
Share Memory Program Example. int array_size=1000 int global_array[array_size] main(argc , argv) { int nprocs=4; m_set_procs(nprocs); /* prepare to launch this many processes */ m_fork(sum); /* fork out processes */ m_kill_procs(); /* kill activated processes */ }

E N D
Share Memory Program Example int array_size=1000 int global_array[array_size] main(argc , argv) { int nprocs=4; m_set_procs(nprocs); /* prepare to launch this many processes */ m_fork(sum); /* fork out processes */ m_kill_procs(); /* kill activated processes */ } void sum() { int id; id = m_get_myid(); for (i=id*(array_size/nprocs); i<(id+1)*(array_size/nprocs); i++) global_array[id*array_size/nprocs]+=global_array[i]; }
Message-Passing Systems • A message passing facility provides at least two operations: send(message),receive(message)
Message-Passing Systems • If 2 processes want to communicate, a communication link must exist It has the following variations: • Direct or indirect communication • Synchronize or asynchronize communication • Automatic or explicit buffering
Message-Passing Systems • Direct communication send(P, message) receive(Q, message) Properties: • A link is established automatically • A link is associated with exactly 2 processes • Between each pair, there exists exactly one link
Message-Passing Systems • Indirect communication: the messages are sent to and received from mailbox send(A, message) receive(A, message)
Message-Passing Systems Properties: • A link is established only if both members of the pair have a shared mailbox • A link is associated with more than 2 processes • Between each pair, there exists a number of links
Message-Passing Systems • Mailbox sharing • P1, P2, andP3 share mailbox A • P1, sends; P2 andP3 receive • Who gets the message? Solutions • Allow a link to be associated with at most two processes • Allow only one process at a time to execute a receive operation • Allow the system to select arbitrarily the receiver. Sender is notified who the receiver was.
Message-Passing Systems • If the mailbox owned by process, it is easy to tell who is the owner and user. • And there is no confuse we send the message and who receives it. • When process terminates, the mailbox disappear
Message-Passing Systems • If the mailbox owned by OS, it requires the following functions: • Create a new mailbox • Send and Receive message through the mailbox • Delete a mailbox
Message-Passing Systems • Synchronization: synchronous and asynchronous Blocking is considered synchronous • Blocking send has the sender block until the message is received • Blocking receive has the receiver block until a message is available
Message-Passing Systems Non-blockingis considered asynchronous • Non-blocking send has the sender send the message and continue • Non-blocking receive has the receiver receive a valid message or null
Message-Passing Systems • Buffering: Queue of messages attached to the link, there are 3 variations: • Zero capacity –0 messages Sender must wait for receiver • Bounded capacity –finite length of n messages, sender must wait if link full • Unbounded capacity –infinite length Sender never waits
MPI Program example #include "mpi.h" #include <math.h> #include <stdio.h> #include <stdlib.h> int main (int argc, char *argv[]) { int id; /* Process rank */ int p; /* Number of processes */ int i,j; int array_size=100; int array[array_size]; /* or *array and then use malloc or vector to increase the size */ int local_array[array_size/p]; int sum=0; MPI_Status stat; MPI_Comm_rank (MPI_COMM_WORLD, &id); MPI_Comm_size (MPI_COMM_WORLD, &p);
MPI Program example if (id==0) { for(i=0; i<array_size; i++) array[i]=i; /* initialize array*/ for(i=0; i<p; i++) MPI_Send(&array[i*array_size/p], /* Start from*/ array_size/p, /* Message size*/ MPI_INT, /* Data type*/ i, /* Send to which process*/ MPI_COMM_WORLD); } else MPI_Recv(&local_array[0],array_size/p,MPI_INT,0,0,MPI_COMM_WORLD,&stat);
MPI Program example for(i=0;i<array_size/p;i++) sum+=local_array[i]; MPI_Reduce (&sum, &sum, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD); if (id==0) printf("%d ",sum); }
Chapter 4 Threads Bernard Chen Spring 2007
Overview • A thread is a basic unit of CPU utilization. • Traditional (single-thread) process has only one single thread control • Multithreaded process can perform more than one task at a time example: word may have a thread for displaying graphics, another respond for key strokes and a third for performing spelling and grammar checking
Overview • Another example is web server: a busy web server may have several clients connected. • Past method: when receives a request, create another process (time consuming and resource intensive) • Multithreaded method: server create threads to “listen” the request from user. When a request is made, the server create another thread to service the request
Benefits • Responsiveness: allow a program to continue running even if part of it is blocked or is performing a lengthy operation • Resource sharing: share memory and resources • Economy: unlike multi processors, no need to allocate memory and resources • Utilization of multiprocessor architectures: multithreading on multi-CPU machine increases concurrency
Multithreading Models • Support for threads may be provided either at the user level, for user threads, or by the kernel, for kernel threads • User threads are supported above kernel and are managed without kernel support • Kernel threads are supported and managed directly by the operating system
Multithreading Models • Ultimately, there must exist a relationship between user thread and kernel thread • User-level threads are managed by a thread library, and the kernel is unaware of them • To run in a CPU, user-level thread must be mapped to an associated kernel-level thread
Many-to-one Model User Threads Kernel thread
Many-to-one Model • It maps many user-level threads to one kernel thread • Thread management is done by the thread library in user space, so it is efficient • But the entire system may block makes a block system call. • Besides multiple threads are unable to run in parallel on multiprocessors
One-to-one Model User Threads Kernel threads
One-to-one Model • It provide more concurrency than the many-to-one model by allowing another thread to run when a thread makes a blocking system call • It allows to run in parallel on multiprocessors • The only drawback is that creating a user thread requires creating the corresponding kernel thread • Most implementation restrict the number of threads create by user
Many-to-many Model User Threads Kernel threads
Many-to-many Model • Multiplexes many user-level threads to a smaller or equal number of kernel threads • User can create as many threads as they want • When a block system called by a thread, the kernel can schedule another thread for execution
Pthread Example #include <pthread.h> #include <stdio.h> int sum; /* global variable*/ void *runner(void *param); int main(int argc, char *argv[]) { pthread_t tid; /* thread id*/ pthread_attr_t attr; /* set of thread attributes*/ pthread_attr_init(&attr); /* get the default attributes*/ pthread_create(&tid,&attr,runner,argv[1]); pthread_join(tid,NULL); printf(“sum=%d \n”,sum); }
Pthread Example void *runner(void *param) { int I; int upper = atoi(param); sum=0; for(i=1;i<=upper;i++) sum+=i; pthread_exit(0); }