Download
1 / 8
80 likes | 212 Views
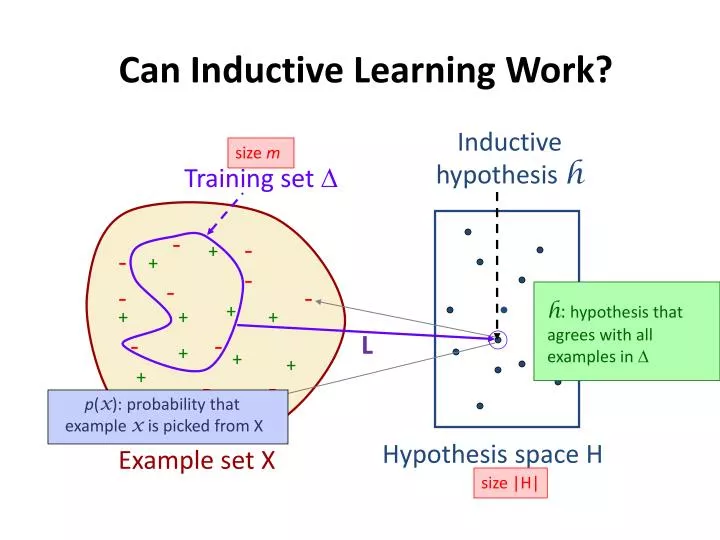
Inductive hypothesis h. Training set D. p ( x ): probability that example x is picked from X. size |H|. size m. -. -. +. -. +. -. -. -. -. +. +. +. +. -. -. +. +. +. +. -. -. -. +. +. Hypothesis space H. Example set X.

E N D
Inductivehypothesis h Training set D p(x): probability that example x is picked from X size |H| size m - - + - + - - - - + + + + - - + + + + - - - + + Hypothesis space H Example set X h: hypothesis that agrees with all examples in D Can Inductive Learning Work? L
Approximately CorrectHypothesis h H is approximately correct (AC)with accuracy eiff: Pr[h(x) correct] > 1 – e where x is an example picked with probability distribution p from X
PAC Learning Algorithm • A leaning algorithm L is Provably Approximately Correct(PAC) with confidence 1-giff the probability that it generates a non-AC hypothesis his g:Pr[his non-AC] g • Can L be PAC if the size m of the training set D is large enough? • If yes, how big should m be?
Intuition • If m is large enough and g H is not AC, it is unlikely that it agrees with all examples in the training dataset D • So, if m is large enough, there should be few non-AC hypotheses that agree with all examples in D • Hence, it is unlikely that L will pick one
Can L Be PAC? • Let g be an arbitraryhypothesis in H that is not approximately correct • Since g is not AC, we have: Pr[g(x) correct] 1–e • The probability that g is consistent with all the examples in D is at most(1-e)m • The probability that there exists a non-AC hypothesis matching all examples in D is at most |H|(1-e)m • Therefore, L is PAC if m verifies: |H|(1-e)m g h H is AC iff: Pr[h(x) correct] > 1–e L is PAC if Pr[h is non-AC] g
Calculus • H = {h1, h2, …, h|H|} • Pr(hi is not-AC and agrees with D) (1-e)m • Pr(h1, or h2, …, is not-AC and agrees with D) Si=1,…,|H|Pr(hi is not-AC and agrees with D) |H| (1-e)m
Size of Training Set • From |H|(1-e)m g we derive:mln(g/|H|) / ln(1-e) • Since e < -ln(1-e) for 0 < e <1, we have:mln(g/|H|) / (-e)mln(|H|/g) / e • So, m increases logarithmicallywith the size of the hypothesis space But how big is |H|?
2n 2 Importance of KIS Bias • If H is the set of all logical sentences with nobservable predicates, then |H| = , and m is exponential in n • If H is the set of all conjunctions of k << nobservable predicates picked among n predicates, then |H| = O(nk) and m is logarithmic in n • Importance of choosing a “good” KIS bias






















