Download
1 / 17
170 likes | 191 Views
FAUST Cluster is the most efficient clustering method using projections onto circumscribing-coord-rectangle midlines for gap analysis. It offers linear and round gap analysis using two methods, dfg and fgd. MCR (Midlines of Circumscribing Coordinate Rectangle) combines d and f, g for a streamlined approach. FAUST Cluster excels in analyzing datasets like Iris150 and efficiently identifies outliers. Speed is optimized with zero calculation costs for certain operations. The method performs well in accuracy, ideal for separating clusters with existing gaps. FAUST Cluster offers lighting-fast processing for big data analysis without pre-processing.

E N D
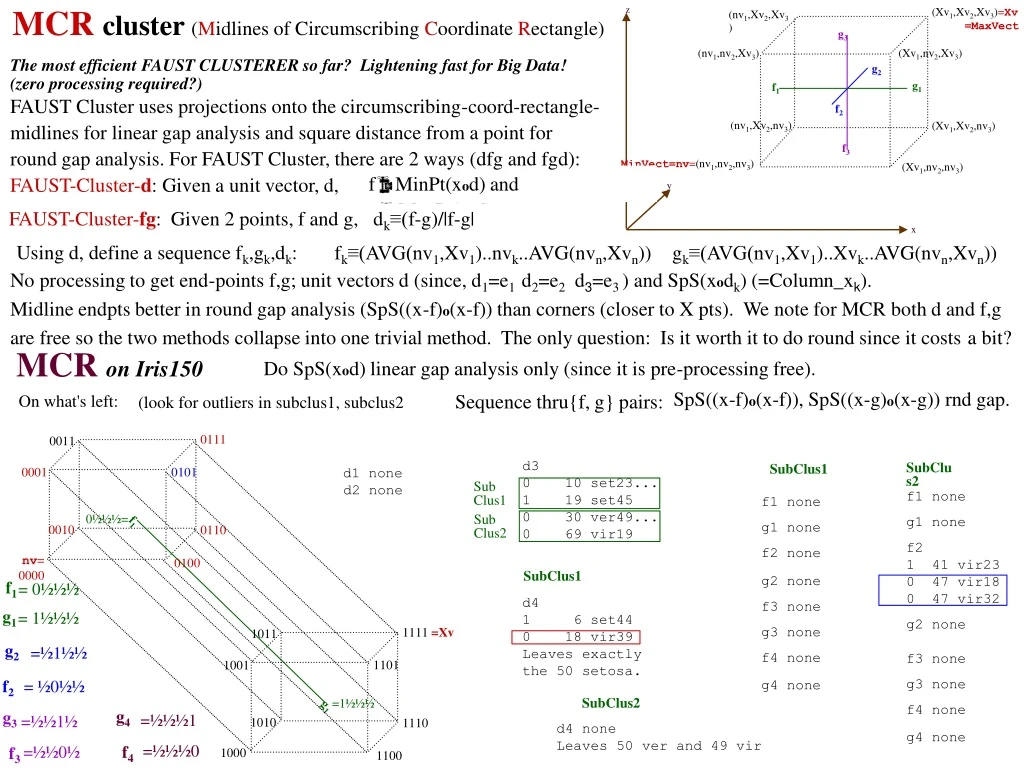
z (Xv1,Xv2,Xv3)=Xv =MaxVect (nv1,Xv2,Xv3) g4 g3 g3 (Xv1,nv2,Xv3) (nv1,nv2,Xv3) g2 Sub Clus1 Sub Clus2 g1 g1 f1 f1 f2 (Xv1,Xv2,nv3) (nv1,Xv2,nv3) 0111 0011 f4 f3 f3 MinVect=nv=(nv1,nv2,nv3) (Xv1,nv2,nv3) 0101 0001 y g2 =½1½½ x =½½1½ 0½½½= 0110 0010 f2 = ½0½½ =½½0½ nv= 0000 0100 1111 =Xv 1011 1101 1001 =1½½½ f1 = 0½½½ 1110 1010 g1 = 1½½½ 1000 1100 =½½½1 =½½½0 MCR cluster (Midlines of Circumscribing Coordinate Rectangle) The most efficient FAUST CLUSTERER so far? Lightening fast for Big Data! (zero processing required?) FAUST Cluster uses projections onto the circumscribing-coord-rectangle-midlines for linear gap analysis and square distance from a point for round gap analysis. For FAUST Cluster, there are 2 ways (dfg and fgd): FAUST-Cluster-d: Given a unit vector, d, fMinPt(xod) and gMaxPt(xod) FAUST-Cluster-fg: Given 2 points, f and g, dk≡(f-g)/|f-g| Using d, define a sequence fk,gk,dk: fk≡(AVG(nv1,Xv1)..nvk..AVG(nvn,Xvn)) gk≡(AVG(nv1,Xv1)..Xvk..AVG(nvn,Xvn)) No processing to get end-points f,g; unit vectors d (since, d1=e1 d2=e2 d3=e3 ) and SpS(xodk) (=Column_xk). Midline endpts better in round gap analysis (SpS((x-f)o(x-f)) than corners (closer to X pts). We note for MCR both d and f,g are free so the two methods collapse into one trivial method. The only question: Is it worth it to do round since it costs a bit? MCR on Iris150 Do SpS(xod) linear gap analysis only (since it is pre-processing free). SpS((x-f)o(x-f)), SpS((x-g)o(x-g)) rnd gap. Sequence thru{f, g} pairs: On what's left: (look for outliers in subclus1, subclus2 d3 0 10 set23... 1 19 set45 0 30 ver49... 0 69 vir19 SubClus2 SubClus1 d1 none d2 none f1 none f1 none g1 none g1 none f2 1 41 vir23 0 47 vir18 0 47 vir32 f2 none SubClus1 g2 none d4 1 6 set44 0 18 vir39 Leaves exactly the 50 setosa. f3 none g2 none g3 none f4 none f3 none g3 none g4 none SubClus2 f4 none d4 none Leaves 50 ver and 49 vir g4 none
MCR on Iris150+Outlier30, gap>4: Sub Clus1 Sub Clus1 t2 t23 t24 t234 0.0 35.0 12.0 37 35.0 0.0 37.0 12 12.0 37.0 0.0 35 37.0 12.0 35.0 0 b124 b134 b14 ball 0.0 52.4 30.0 43.0 52.4 0.0 43.0 30.0 30.0 43.0 0.0 52.4 43.0 30.0 52.4 0.0 b24 b2 b234 b23 0.0 28.0 43.0 51.3 28.0 0.0 51.3 43.0 43.0 51.3 0.0 28.0 51.3 43.0 28.0 0.0 t13 t12 t1 t123 0.0 43.0 35.0 25.0 43.0 0.0 25.0 35.0 35.0 25.0 0.0 43.0 25.0 35.0 43.0 0.0 t124 t14 tal t134 0.0 25.0 35.0 43.0 25.0 0.0 43.0 35.0 35.0 43.0 0.0 25.0 43.0 35.0 25.0 0.0 b12 b1 b13 b123 0.0 30.0 52.4 43.0 30.0 0.0 43.0 52.4 52.4 43.0 0.0 30.0 43.0 52.4 30.0 0.0 Do SpS(xodk) linear gap analysis, k=1,2,3,4. Declare subclusters of size 1 or two to be outliers. Create the full pairwise distance table for any subcluster of size 10 and declare any point an outlier if its column (other than the zero diagonal value) values all exceed the threshold (which is 4). d3 0 10 set23... 1 19 set25 0 30 ver49... 1 69 vir19 Same split (expected) d1 0 17 t124 0 17 t14 0 17 tal 1 17 t134 0 23 t13 0 23 t12 0 23 t1 1 23 t123 0 38 set14 ... 1 79 vir32 0 84 b12 0 84 b1 0 84 b13 1 84 b123 0 98 b124 0 98 b134 0 98 b14 0 98 ball SubClus1 d4 1 6 set44 0 18 vir39 Leaves exactly the 50 setosa as SubCluster1. SubClus2 d4 0 0 t4 1 0 t24 0 10 ver18 ... 1 25 vir45 0 40 b4 0 40 b24 Leaves the 49 virginica (vir39 declared an outlier) and the 50 versicolor as SubCluster2. MCR performs well on this dataset. Accuracy: We can't expect a clustering method to separate versicolor from virginica because there is no gap between them. This method does separate off setosa perfectly and finds all 30 added outliers (subcluster of size 1 or 2). It also picks out vir39 as an outlier within the virginica class. Speed: dk = ek so there is zero calculation cost for the d's. SpS(xodk) = SpS(xoek) = SpS(Xk) so there is zero calculation cost for it. The only cost is the loading of the dataset PTreeSet(X) (We use one column, SpS(Xk) at a time.) and that loading is required for any method. So MCR isoptimal with respect to speed! d2 0 5 t2 0 5 t23 0 5 t24 1 5 t234 0 20 ver1 ... 1 44 set16 0 60 b24 0 60 b2 0 60 b234 0 60 b23
CCR(Corners of Circumscribing Coordinate Rectangle) (rnd-f, rnd-g, then lin-d)f=MinVecX≡(minXx1..minXxn) Sub Clus1 Sub Clus2 Subc2.1 ver49 ver8 ver44 ver11 ver49 set42 ver8 set36 ver44 ver11 0.0 19.8 3.9 21.3 3.9 7.2 19.8 0.0 21.6 10.4 21.8 23.8 3.9 21.6 0.0 23.9 1.4 4.6 21.3 10.4 23.9 0.0 24.2 27.1 3.9 21.8 1.4 24.2 0.0 3.6 7.2 23.8 4.6 27.1 3.6 0.0 g≡MaxVecX≡(maxXx1..maxXxn), d≡(g-f)/|g-f| Sequence thru main diagonal pairs, {f, g} lexicographically. For each, create d. start f1=MnVec RnGp>4 none Notes: No calculation required to find f and g (assuming MaxVecX and MinVecXhave been calculated and residualized when PTreeSetX was captured.) 3. (and 2.?) may be unproductive in finding new subclusters (either because 1 finds almost all or because 2 and/or 3 find the same ones) and could be skipped (very likely if dimension is high, since the main diagonal corners are typically far from X, in a high dimensional vector space and thus the radii of a round gap is large and large radii rnd gaps are near linear, suggesting a will find all the subclusters that b and c would find. g1=MxVec RnGp>4 0 7 vir18... 1 47 ver30 0 53 ver49.. 0 74 set14 CCR-1. Do SpS((x-f)o(x-f)) round gap analysis CCR-2. Do SpS((x-g)o(x-g)) rnd gap analysis. CCR-3. Do SpS((xod)) linear gap analysis. SubClus1 Lin>4 none SubCluster2 f2=0001 RnGp>4 none g2=1110 RnGp>4 none This ends SubClus2 = 47 setosa only g1=1111 RnGp>4 none f1=0000 RnGp>4 none Lin>4 none Lin>4 none f3=0010 RnGp>4 none g2=1110 RnGp>4 none f2=0001 RnGp>4 none Lin>4 none g3=1101 RnGp>4 none 2. good!, else setosa/versicolor+virginica are not separated! 3. is unproductive, suggesting productive to calculate 1., 2. but having done that, 3. will probably not be productive. Next consider only 3. to see if it is as productive as 1.+2. f3=0010 RnGp>4 none g3=1101 RnGp>4 none Lin>4 none Lin>4 none f4=0011 RnGp>4 none g4=1100 RnGp>4 none f4=0011 RnGp>4 none Lin>4 none g4=1100 RnGp>4 none f5=0100 RnGp>4 none g5=1011 RnGp>4 none Lin>4 none Lin>4 none CCR is as good as the combo (projection on d appears to be as accurate as the combination of square length of f and of g). This is probably because the round gaps (centered at the corners) are nearly linear by the time they get to the set X itself. To compare the time costs, we note: f6=0101 RnGp>4 1 19 set26 0 28 ver49 0 31 set42 0 31 ver8 0 32 set36 0 32 ver44 1 35 ver11 0 41 ver13 f5=0100 RnGp>4 none g5=1011 RnGp>4 none Lin>4 none f6=0101 RnGp>4 none g6=1010 RnGp>4 none g6=1010 RnGp>4 none Lin>4 none Lin>4 none Combo (p-x)o(p-x) = pop + xox2xop = pop + k=1..nxk2 + k=1..n(-2pk)xk has n multiplications in the second term, n scalar multiplications and n additions in the third term. For both p=f and p=g, then, it takes 2n multiplications, 2n scalar multiplications and 2n additions. f7=0110 RnGp>4 none f7=0110 RnGp>4 1 28 ver13 0 33 vir49 g7=1001 RnGp>4 none Lin>4 none g7=1001 RnGp>4 none Lin>4 none Lin>4 none g8=1000 RnGp>4 none f8=0111 RnGp>4 none f8=0111 RnGp>4 none For CCR, xod = k=1..n(dk)xk involves n scalar mults and n additions. It appears to be cheaper (timewise) g8=1000 RnGp>4 none Lin>4 none This ends SubClus1 = 95 ver and vir samples only
SL SW PL PW set 51 35 14 2 0 1 1 0 0 1 1 1 0 0 0 1 1 0 0 0 1 1 1 0 0 0 0 0 1 0 set 49 30 14 2 0 1 1 0 0 0 1 0 1 1 1 1 0 0 0 0 1 1 1 0 0 0 0 0 1 0 set 47 32 13 2 0 1 0 1 1 1 1 1 0 0 0 0 0 0 0 0 1 1 0 1 0 0 0 0 1 0 set 46 31 15 2 0 1 0 1 1 1 0 0 1 1 1 1 1 0 0 0 1 1 1 1 0 0 0 0 1 0 set 50 36 14 2 0 1 1 0 0 1 0 1 0 0 1 0 0 0 0 0 1 1 1 0 0 0 0 0 1 0 set 54 39 17 4 0 1 1 0 1 1 0 1 0 0 1 1 1 0 0 1 0 0 0 1 0 0 0 1 0 0 set 46 34 14 3 0 1 0 1 1 1 0 1 0 0 0 1 0 0 0 0 1 1 1 0 0 0 0 0 1 1 set 50 34 15 2 0 1 1 0 0 1 0 1 0 0 0 1 0 0 0 0 1 1 1 1 0 0 0 0 1 0 set 44 29 14 2 0 1 0 1 1 0 0 0 1 1 1 0 1 0 0 0 1 1 1 0 0 0 0 0 1 0 set 49 31 15 1 0 1 1 0 0 0 1 0 1 1 1 1 1 0 0 0 1 1 1 1 0 0 0 0 0 1 set 54 37 15 2 0 1 1 0 1 1 0 1 0 0 1 0 1 0 0 0 1 1 1 1 0 0 0 0 1 0 set 48 34 16 2 0 1 1 0 0 0 0 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 1 0 set 48 30 14 1 0 1 1 0 0 0 0 0 1 1 1 1 0 0 0 0 1 1 1 0 0 0 0 0 0 1 set 43 30 11 1 0 1 0 1 0 1 1 0 1 1 1 1 0 0 0 0 1 0 1 1 0 0 0 0 0 1 set 58 40 12 2 0 1 1 1 0 1 0 1 0 1 0 0 0 0 0 0 1 1 0 0 0 0 0 0 1 0 set 57 44 15 4 0 1 1 1 0 0 1 1 0 1 1 0 0 0 0 0 1 1 1 1 0 0 0 1 0 0 set 54 39 13 4 0 1 1 0 1 1 0 1 0 0 1 1 1 0 0 0 1 1 0 1 0 0 0 1 0 0 set 51 35 14 3 0 1 1 0 0 1 1 1 0 0 0 1 1 0 0 0 1 1 1 0 0 0 0 0 1 1 set 57 38 17 3 0 1 1 1 0 0 1 1 0 0 1 1 0 0 0 1 0 0 0 1 0 0 0 0 1 1 set 51 38 15 3 0 1 1 0 0 1 1 1 0 0 1 1 0 0 0 0 1 1 1 1 0 0 0 0 1 1 set 54 34 17 2 0 1 1 0 1 1 0 1 0 0 0 1 0 0 0 1 0 0 0 1 0 0 0 0 1 0 set 51 37 15 4 0 1 1 0 0 1 1 1 0 0 1 0 1 0 0 0 1 1 1 1 0 0 0 1 0 0 set 46 36 10 2 0 1 0 1 1 1 0 1 0 0 1 0 0 0 0 0 1 0 1 0 0 0 0 0 1 0 set 51 33 17 5 0 1 1 0 0 1 1 1 0 0 0 0 1 0 0 1 0 0 0 1 0 0 0 1 0 1 set 48 34 19 2 0 1 1 0 0 0 0 1 0 0 0 1 0 0 0 1 0 0 1 1 0 0 0 0 1 0 set 50 30 16 2 0 1 1 0 0 1 0 0 1 1 1 1 0 0 0 1 0 0 0 0 0 0 0 0 1 0 set 50 34 16 4 0 1 1 0 0 1 0 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 1 0 0 set 52 35 15 2 0 1 1 0 1 0 0 1 0 0 0 1 1 0 0 0 1 1 1 1 0 0 0 0 1 0 set 52 34 14 2 0 1 1 0 1 0 0 1 0 0 0 1 0 0 0 0 1 1 1 0 0 0 0 0 1 0 set 47 32 16 2 0 1 0 1 1 1 1 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 set 48 31 16 2 0 1 1 0 0 0 0 0 1 1 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 0 set 54 34 15 4 0 1 1 0 1 1 0 1 0 0 0 1 0 0 0 0 1 1 1 1 0 0 0 1 0 0 set 52 41 15 1 0 1 1 0 1 0 0 1 0 1 0 0 1 0 0 0 1 1 1 1 0 0 0 0 0 1 set 55 42 14 2 0 1 1 0 1 1 1 1 0 1 0 1 0 0 0 0 1 1 1 0 0 0 0 0 1 0 set 49 31 15 1 0 1 1 0 0 0 1 0 1 1 1 1 1 0 0 0 1 1 1 1 0 0 0 0 0 1 set 50 32 12 2 0 1 1 0 0 1 0 1 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 1 0 set 55 35 13 2 0 1 1 0 1 1 1 1 0 0 0 1 1 0 0 0 1 1 0 1 0 0 0 0 1 0 set 49 31 15 1 0 1 1 0 0 0 1 0 1 1 1 1 1 0 0 0 1 1 1 1 0 0 0 0 0 1 set 44 30 13 2 0 1 0 1 1 0 0 0 1 1 1 1 0 0 0 0 1 1 0 1 0 0 0 0 1 0 set 51 34 15 2 0 1 1 0 0 1 1 1 0 0 0 1 0 0 0 0 1 1 1 1 0 0 0 0 1 0 set 50 35 13 3 0 1 1 0 0 1 0 1 0 0 0 1 1 0 0 0 1 1 0 1 0 0 0 0 1 1 set 45 23 13 3 0 1 0 1 1 0 1 0 1 0 1 1 1 0 0 0 1 1 0 1 0 0 0 0 1 1 set 44 32 13 2 0 1 0 1 1 0 0 1 0 0 0 0 0 0 0 0 1 1 0 1 0 0 0 0 1 0 set 50 35 16 6 0 1 1 0 0 1 0 1 0 0 0 1 1 0 0 1 0 0 0 0 0 0 0 1 1 0 set 51 38 19 4 0 1 1 0 0 1 1 1 0 0 1 1 0 0 0 1 0 0 1 1 0 0 0 1 0 0 set 48 30 14 3 0 1 1 0 0 0 0 0 1 1 1 1 0 0 0 0 1 1 1 0 0 0 0 0 1 1 set 51 38 16 2 0 1 1 0 0 1 1 1 0 0 1 1 0 0 0 1 0 0 0 0 0 0 0 0 1 0 set 46 32 14 2 0 1 0 1 1 1 0 1 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 1 0 set 53 37 15 2 0 1 1 0 1 0 1 1 0 0 1 0 1 0 0 0 1 1 1 1 0 0 0 0 1 0 set 50 33 14 2 0 1 1 0 0 1 0 1 0 0 0 0 1 0 0 0 1 1 1 0 0 0 0 0 1 0 ver 70 32 47 14 1 0 0 0 1 1 0 1 0 0 0 0 0 0 1 0 1 1 1 1 0 0 1 1 1 0 ver 64 32 45 15 1 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 1 1 0 1 0 0 1 1 1 1 ver 69 31 49 15 1 0 0 0 1 0 1 0 1 1 1 1 1 0 1 1 0 0 0 1 0 0 1 1 1 1 ver 55 23 40 13 0 1 1 0 1 1 1 0 1 0 1 1 1 0 1 0 1 0 0 0 0 0 1 1 0 1 ver 65 28 46 15 1 0 0 0 0 0 1 0 1 1 1 0 0 0 1 0 1 1 1 0 0 0 1 1 1 1 ver 57 28 45 13 0 1 1 1 0 0 1 0 1 1 1 0 0 0 1 0 1 1 0 1 0 0 1 1 0 1 ver 63 33 47 16 0 1 1 1 1 1 1 1 0 0 0 0 1 0 1 0 1 1 1 1 0 1 0 0 0 0 ver 49 24 33 10 0 1 1 0 0 0 1 0 1 1 0 0 0 0 1 0 0 0 0 1 0 0 1 0 1 0 ver 66 29 46 13 1 0 0 0 0 1 0 0 1 1 1 0 1 0 1 0 1 1 1 0 0 0 1 1 0 1 ver 52 27 39 14 0 1 1 0 1 0 0 0 1 1 0 1 1 0 1 0 0 1 1 1 0 0 1 1 1 0 ver 50 20 35 10 0 1 1 0 0 1 0 0 1 0 1 0 0 0 1 0 0 0 1 1 0 0 1 0 1 0 ver 59 30 42 15 0 1 1 1 0 1 1 0 1 1 1 1 0 0 1 0 1 0 1 0 0 0 1 1 1 1 ver 60 22 40 10 0 1 1 1 1 0 0 0 1 0 1 1 0 0 1 0 1 0 0 0 0 0 1 0 1 0 ver 61 29 47 14 0 1 1 1 1 0 1 0 1 1 1 0 1 0 1 0 1 1 1 1 0 0 1 1 1 0 ver 56 29 36 13 0 1 1 1 0 0 0 0 1 1 1 0 1 0 1 0 0 1 0 0 0 0 1 1 0 1 ver 67 31 44 14 1 0 0 0 0 1 1 0 1 1 1 1 1 0 1 0 1 1 0 0 0 0 1 1 1 0 ver 56 30 45 15 0 1 1 1 0 0 0 0 1 1 1 1 0 0 1 0 1 1 0 1 0 0 1 1 1 1 ver 58 27 41 10 0 1 1 1 0 1 0 0 1 1 0 1 1 0 1 0 1 0 0 1 0 0 1 0 1 0 ver 62 22 45 15 0 1 1 1 1 1 0 0 1 0 1 1 0 0 1 0 1 1 0 1 0 0 1 1 1 1 ver 56 25 39 11 0 1 1 1 0 0 0 0 1 1 0 0 1 0 1 0 0 1 1 1 0 0 1 0 1 1 ver 59 32 48 18 0 1 1 1 0 1 1 1 0 0 0 0 0 0 1 1 0 0 0 0 0 1 0 0 1 0 ver 61 28 40 13 0 1 1 1 1 0 1 0 1 1 1 0 0 0 1 0 1 0 0 0 0 0 1 1 0 1 ver 63 25 49 15 0 1 1 1 1 1 1 0 1 1 0 0 1 0 1 1 0 0 0 1 0 0 1 1 1 1 ver 61 28 47 12 0 1 1 1 1 0 1 0 1 1 1 0 0 0 1 0 1 1 1 1 0 0 1 1 0 0 ver 64 29 43 13 1 0 0 0 0 0 0 0 1 1 1 0 1 0 1 0 1 0 1 1 0 0 1 1 0 1 ver 66 30 44 14 1 0 0 0 0 1 0 0 1 1 1 1 0 0 1 0 1 1 0 0 0 0 1 1 1 0 ver 68 28 48 14 1 0 0 0 1 0 0 0 1 1 1 0 0 0 1 1 0 0 0 0 0 0 1 1 1 0 ver 67 30 50 17 1 0 0 0 0 1 1 0 1 1 1 1 0 0 1 1 0 0 1 0 0 1 0 0 0 1 ver 60 29 45 15 0 1 1 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 0 1 0 0 1 1 1 1 ver 57 26 35 10 0 1 1 1 0 0 1 0 1 1 0 1 0 0 1 0 0 0 1 1 0 0 1 0 1 0 ver 55 24 38 11 0 1 1 0 1 1 1 0 1 1 0 0 0 0 1 0 0 1 1 0 0 0 1 0 1 1 ver 55 24 37 10 0 1 1 0 1 1 1 0 1 1 0 0 0 0 1 0 0 1 0 1 0 0 1 0 1 0 ver 58 27 39 12 0 1 1 1 0 1 0 0 1 1 0 1 1 0 1 0 0 1 1 1 0 0 1 1 0 0 ver 60 27 51 16 0 1 1 1 1 0 0 0 1 1 0 1 1 0 1 1 0 0 1 1 0 1 0 0 0 0 ver 54 30 45 15 0 1 1 0 1 1 0 0 1 1 1 1 0 0 1 0 1 1 0 1 0 0 1 1 1 1 ver 60 34 45 16 0 1 1 1 1 0 0 1 0 0 0 1 0 0 1 0 1 1 0 1 0 1 0 0 0 0 ver 67 31 47 15 1 0 0 0 0 1 1 0 1 1 1 1 1 0 1 0 1 1 1 1 0 0 1 1 1 1 ver 63 23 44 13 0 1 1 1 1 1 1 0 1 0 1 1 1 0 1 0 1 1 0 0 0 0 1 1 0 1 ver 56 30 41 13 0 1 1 1 0 0 0 0 1 1 1 1 0 0 1 0 1 0 0 1 0 0 1 1 0 1 ver 55 25 40 13 0 1 1 0 1 1 1 0 1 1 0 0 1 0 1 0 1 0 0 0 0 0 1 1 0 1 ver 55 26 44 12 0 1 1 0 1 1 1 0 1 1 0 1 0 0 1 0 1 1 0 0 0 0 1 1 0 0 ver 61 30 46 14 0 1 1 1 1 0 1 0 1 1 1 1 0 0 1 0 1 1 1 0 0 0 1 1 1 0 SL SW PL PW ver 58 26 40 12 0 1 1 1 0 1 0 0 1 1 0 1 0 0 1 0 1 0 0 0 0 0 1 1 0 0 ver 50 23 33 10 0 1 1 0 0 1 0 0 1 0 1 1 1 0 1 0 0 0 0 1 0 0 1 0 1 0 ver 56 27 42 13 0 1 1 1 0 0 0 0 1 1 0 1 1 0 1 0 1 0 1 0 0 0 1 1 0 1 ver 57 30 42 12 0 1 1 1 0 0 1 0 1 1 1 1 0 0 1 0 1 0 1 0 0 0 1 1 0 0 ver 57 29 42 13 0 1 1 1 0 0 1 0 1 1 1 0 1 0 1 0 1 0 1 0 0 0 1 1 0 1 ver 62 29 43 13 0 1 1 1 1 1 0 0 1 1 1 0 1 0 1 0 1 0 1 1 0 0 1 1 0 1 ver 51 25 30 11 0 1 1 0 0 1 1 0 1 1 0 0 1 0 0 1 1 1 1 0 0 0 1 0 1 1 ver 57 28 41 13 0 1 1 1 0 0 1 0 1 1 1 0 0 0 1 0 1 0 0 1 0 0 1 1 0 1 vir 63 33 60 25 0 1 1 1 1 1 1 1 0 0 0 0 1 0 1 1 1 1 0 0 0 1 1 0 0 1 vir 58 27 51 19 0 1 1 1 0 1 0 0 1 1 0 1 1 0 1 1 0 0 1 1 0 1 0 0 1 1 vir 71 30 59 21 1 0 0 0 1 1 1 0 1 1 1 1 0 0 1 1 1 0 1 1 0 1 0 1 0 1 vir 63 29 56 18 0 1 1 1 1 1 1 0 1 1 1 0 1 0 1 1 1 0 0 0 0 1 0 0 1 0 vir 65 30 58 22 1 0 0 0 0 0 1 0 1 1 1 1 0 0 1 1 1 0 1 0 0 1 0 1 1 0 vir 76 30 66 21 1 0 0 1 1 0 0 0 1 1 1 1 0 1 0 0 0 0 1 0 0 1 0 1 0 1 vir 49 25 45 17 0 1 1 0 0 0 1 0 1 1 0 0 1 0 1 0 1 1 0 1 0 1 0 0 0 1 vir 73 29 63 18 1 0 0 1 0 0 1 0 1 1 1 0 1 0 1 1 1 1 1 1 0 1 0 0 1 0 vir 67 25 58 18 1 0 0 0 0 1 1 0 1 1 0 0 1 0 1 1 1 0 1 0 0 1 0 0 1 0 vir 72 36 61 25 1 0 0 1 0 0 0 1 0 0 1 0 0 0 1 1 1 1 0 1 0 1 1 0 0 1 vir 65 32 51 20 1 0 0 0 0 0 1 1 0 0 0 0 0 0 1 1 0 0 1 1 0 1 0 1 0 0 vir 64 27 53 19 1 0 0 0 0 0 0 0 1 1 0 1 1 0 1 1 0 1 0 1 0 1 0 0 1 1 vir 68 30 55 21 1 0 0 0 1 0 0 0 1 1 1 1 0 0 1 1 0 1 1 1 0 1 0 1 0 1 vir 57 25 50 20 0 1 1 1 0 0 1 0 1 1 0 0 1 0 1 1 0 0 1 0 0 1 0 1 0 0 vir 58 28 51 24 0 1 1 1 0 1 0 0 1 1 1 0 0 0 1 1 0 0 1 1 0 1 1 0 0 0 vir 64 32 53 23 1 0 0 0 0 0 0 1 0 0 0 0 0 0 1 1 0 1 0 1 0 1 0 1 1 1 vir 65 30 55 18 1 0 0 0 0 0 1 0 1 1 1 1 0 0 1 1 0 1 1 1 0 1 0 0 1 0 vir 77 38 67 22 1 0 0 1 1 0 1 1 0 0 1 1 0 1 0 0 0 0 1 1 0 1 0 1 1 0 vir 77 26 69 23 1 0 0 1 1 0 1 0 1 1 0 1 0 1 0 0 0 1 0 1 0 1 0 1 1 1 vir 60 22 50 15 0 1 1 1 1 0 0 0 1 0 1 1 0 0 1 1 0 0 1 0 0 0 1 1 1 1 vir 69 32 57 23 1 0 0 0 1 0 1 1 0 0 0 0 0 0 1 1 1 0 0 1 0 1 0 1 1 1 vir 56 28 49 20 0 1 1 1 0 0 0 0 1 1 1 0 0 0 1 1 0 0 0 1 0 1 0 1 0 0 vir 77 28 67 20 1 0 0 1 1 0 1 0 1 1 1 0 0 1 0 0 0 0 1 1 0 1 0 1 0 0 vir 63 27 49 18 0 1 1 1 1 1 1 0 1 1 0 1 1 0 1 1 0 0 0 1 0 1 0 0 1 0 vir 67 33 57 21 1 0 0 0 0 1 1 1 0 0 0 0 1 0 1 1 1 0 0 1 0 1 0 1 0 1 vir 72 32 60 18 1 0 0 1 0 0 0 1 0 0 0 0 0 0 1 1 1 1 0 0 0 1 0 0 1 0 vir 62 28 48 18 0 1 1 1 1 1 0 0 1 1 1 0 0 0 1 1 0 0 0 0 0 1 0 0 1 0 vir 61 30 49 18 0 1 1 1 1 0 1 0 1 1 1 1 0 0 1 1 0 0 0 1 0 1 0 0 1 0 vir 64 28 56 21 1 0 0 0 0 0 0 0 1 1 1 0 0 0 1 1 1 0 0 0 0 1 0 1 0 1 vir 72 30 58 16 1 0 0 1 0 0 0 0 1 1 1 1 0 0 1 1 1 0 1 0 0 1 0 0 0 0 vir 74 28 61 19 1 0 0 1 0 1 0 0 1 1 1 0 0 0 1 1 1 1 0 1 0 1 0 0 1 1 vir 79 38 64 20 1 0 0 1 1 1 1 1 0 0 1 1 0 1 0 0 0 0 0 0 0 1 0 1 0 0 vir 64 28 56 22 1 0 0 0 0 0 0 0 1 1 1 0 0 0 1 1 1 0 0 0 0 1 0 1 1 0 vir 63 28 51 15 0 1 1 1 1 1 1 0 1 1 1 0 0 0 1 1 0 0 1 1 0 0 1 1 1 1 vir 61 26 56 14 0 1 1 1 1 0 1 0 1 1 0 1 0 0 1 1 1 0 0 0 0 0 1 1 1 0 vir 77 30 61 23 1 0 0 1 1 0 1 0 1 1 1 1 0 0 1 1 1 1 0 1 0 1 0 1 1 1 vir 63 34 56 24 0 1 1 1 1 1 1 1 0 0 0 1 0 0 1 1 1 0 0 0 0 1 1 0 0 0 vir 64 31 55 18 1 0 0 0 0 0 0 0 1 1 1 1 1 0 1 1 0 1 1 1 0 1 0 0 1 0 vir 60 30 18 18 0 1 1 1 1 0 0 0 1 1 1 1 0 0 0 1 0 0 1 0 0 1 0 0 1 0 vir 69 31 54 21 1 0 0 0 1 0 1 0 1 1 1 1 1 0 1 1 0 1 1 0 0 1 0 1 0 1 vir 67 31 56 24 1 0 0 0 0 1 1 0 1 1 1 1 1 0 1 1 1 0 0 0 0 1 1 0 0 0 vir 69 31 51 23 1 0 0 0 1 0 1 0 1 1 1 1 1 0 1 1 0 0 1 1 0 1 0 1 1 1 vir 58 27 51 19 0 1 1 1 0 1 0 0 1 1 0 1 1 0 1 1 0 0 1 1 0 1 0 0 1 1 vir 68 32 59 23 1 0 0 0 1 0 0 1 0 0 0 0 0 0 1 1 1 0 1 1 0 1 0 1 1 1 vir 67 33 57 25 1 0 0 0 0 1 1 1 0 0 0 0 1 0 1 1 1 0 0 1 0 1 1 0 0 1 vir 67 30 52 23 1 0 0 0 0 1 1 0 1 1 1 1 0 0 1 1 0 1 0 0 0 1 0 1 1 1 vir 63 25 50 19 0 1 1 1 1 1 1 0 1 1 0 0 1 0 1 1 0 0 1 0 0 1 0 0 1 1 vir 65 30 52 20 1 0 0 0 0 0 1 0 1 1 1 1 0 0 1 1 0 1 0 0 0 1 0 1 0 0 vir 62 34 54 23 0 1 1 1 1 1 0 1 0 0 0 1 0 0 1 1 0 1 1 0 0 1 0 1 1 1 vir 59 30 51 18 0 1 1 1 0 1 1 0 1 1 1 1 0 0 1 1 0 0 1 1 0 1 0 0 1 0 t1 20 30 37 12 0 0 1 0 1 0 0 0 1 1 1 1 0 0 1 0 0 1 0 1 0 0 1 0 1 1 t2 58 5 37 12 0 1 1 1 0 1 0 0 0 0 1 0 1 0 1 0 0 1 0 1 0 0 1 0 1 1 t3 58 30 2 12 0 1 1 1 0 1 0 0 1 1 1 1 0 0 0 0 0 0 1 0 0 0 1 0 1 1 t4 58 30 37 0 0 1 1 1 0 1 0 0 1 1 1 1 0 0 1 0 0 1 0 1 0 0 0 0 0 0 t12 20 5 37 12 0 0 1 0 1 0 0 0 0 0 1 0 1 0 1 0 0 1 0 1 0 0 1 0 1 1 t13 20 30 2 12 0 0 1 0 1 0 0 0 1 1 1 1 0 0 0 0 0 0 1 0 0 0 1 0 1 1 t14 20 30 37 0 0 0 1 0 1 0 0 0 1 1 1 1 0 0 1 0 0 1 0 1 0 0 0 0 0 0 t23 58 5 2 12 0 1 1 1 0 1 0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 0 1 0 1 1 t24 58 5 37 0 0 1 1 1 0 1 0 0 0 0 1 0 1 0 1 0 0 1 0 1 0 0 0 0 0 0 t34 58 30 2 0 0 1 1 1 0 1 0 0 1 1 1 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 t123 20 5 2 12 0 0 1 0 1 0 0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 0 1 0 1 1 t124 20 5 37 0 0 0 1 0 1 0 0 0 0 0 1 0 1 0 1 0 0 1 0 1 0 0 0 0 0 0 t134 20 30 2 0 0 0 1 0 1 0 0 0 1 1 1 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 t234 58 5 2 0 0 1 1 1 0 1 0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 0 0 0 0 0 tall 20 5 2 0 0 0 1 0 1 0 0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 0 0 0 0 0 b1 90 30 37 12 1 0 1 1 0 1 0 0 1 1 1 1 0 0 1 0 0 1 0 1 0 0 1 0 1 1 b2 58 60 37 12 0 1 1 1 0 1 0 1 1 1 1 0 0 0 1 0 0 1 0 1 0 0 1 0 1 1 b3 58 30 80 12 0 1 1 1 0 1 0 0 1 1 1 1 0 1 0 1 0 0 0 0 0 0 1 0 1 1 b4 58 30 37 40 0 1 1 1 0 1 0 0 1 1 1 1 0 0 1 0 0 1 0 1 1 0 1 0 0 0 b12 90 60 37 12 1 0 1 1 0 1 0 1 1 1 1 0 0 0 1 0 0 1 0 1 0 0 1 0 1 1 b13 90 30 80 12 1 0 1 1 0 1 0 0 1 1 1 1 0 1 0 1 0 0 0 0 0 0 1 0 1 1 b14 90 30 37 40 1 0 1 1 0 1 0 0 1 1 1 1 0 0 1 0 0 1 0 1 1 0 1 0 0 0 b23 58 60 80 12 0 1 1 1 0 1 0 1 1 1 1 0 0 1 0 1 0 0 0 0 0 0 1 0 1 1 b24 58 60 37 40 0 1 1 1 0 1 0 1 1 1 1 0 0 0 1 0 0 1 0 1 1 0 1 0 0 0 b34 58 30 80 40 0 1 1 1 0 1 0 0 1 1 1 1 0 1 0 1 0 0 0 0 1 0 1 0 0 0 b123 90 60 80 12 1 0 1 1 0 1 0 1 1 1 1 0 0 1 0 1 0 0 0 0 0 0 1 0 1 1 b124 90 60 37 40 1 0 1 1 0 1 0 1 1 1 1 0 0 0 1 0 0 1 0 1 1 0 1 0 0 0 b134 90 30 80 40 1 0 1 1 0 1 0 0 1 1 1 1 0 1 0 1 0 0 0 0 1 0 1 0 0 0 b234 58 60 80 40 0 1 1 1 0 1 0 1 1 1 1 0 0 1 0 1 0 0 0 0 1 0 1 0 0 0 ball 90 60 80 40 1 0 1 1 0 1 0 1 1 1 1 0 0 1 0 1 0 0 0 0 1 0 1 0 0 0 Before adding the new tuples: MINS 43 20 10 1 MAXS 79 44 69 25 MEAN 58 30 37 12 same after additions. 1 2 3 4 5 6 7 8 9 10 1 2 3 4 5 6 7 8 9 20 1 2 3 4 5 6 7 8 9 30 1 2 3 4 5 6 7 8 9 40 1 2 3 4 5 6 7 8 9 50 3 4 5 6 7 8 9 50 1 2 3 4 5 6 7 8 9 10 1 2 3 4 5 6 7 8 9 20 1 2 3 4 5 6 7 8 9 30 1 2 3 4 5 6 7 8 9 40 1 2 3 4 5 6 7 8 9 50 1 2 3 4 5 6 7 8 9 10 1 2 3 4 5 6 7 8 9 20 1 2 3 4 5 6 7 8 9 30 1 2 3 4 5 6 7 8 9 40 1 2
FMG-GS (Gram-Schmidt o/n basis)uses linear and round gap analysis based on the mediod and furthest point it for round gap analysis (and the linear projections onto the line generated by those two points): cluster X Rn. Calculate M=MeanVector(X) directly, using only the residualized 1-counts of the basic pTrees of X. And BTW, use residualized STD calculations to guide in choosing good gap width thresholds (which define what an outlier is going to be and also determine when we divide into sub-clusters.)) DISTANCES t123 b234 tal b134 b123 0.00 106.48 12.00 111.32 118.36 106.48 0.00 110.24 43.86 42.52 12.00 110.24 0.00 114.93 118.97 111.32 43.86 114.93 0.00 41.04 118.36 42.52 118.97 41.04 0.00 All outliers! |eh-(ehod1)d1-(ehod2)d2-...-(ehodh-1)dh-1| dh≡(eh-(ehod1)d1-(ehod2)d2-..-(ehodh-1)dh-1) / b12 b14 b24 0.00 41.04 42.52 41.04 0.00 43.86 42.52 43.86 0.00 All outliers again! SubClust-2 SubClust-1 FMG(Furthest-to-Mediod Gap) MRndGp>4 1 53 b13 0 58 t123 0 59 b234 0 59 tal 0 60 b134 1 61 b123 0 67 ball f0=t123 RnGp>4 1 0 t123 0 25 t13 1 28 t134 0 34 set42... 1 103 b23 0 108 b13 f1MxPt(SpS[(M-x)o(M-x)]). d1≡(M-f1)/|M-f1|. SubClust-1 f0=b2 RnGp>4 1 0 b2 0 28 ver36 SubClust-2 f0=t3 RnGp>4 none If d110, Gram-Schmidt {d1 e1...ek-1 ek+1..en} d2 ≡ (e2 - (e2od1)d1) / |e2 - (e2od1)d1| d3 ≡ (e3 - (e3od1)d1 - (e3od2)d2) / |e3 - (e3od1)d1 - (e3od2)d2| ... SubClust-1 f0=b3 RnGp>4 1 0 b3 0 23 vir8 ... 1 54 b1 0 62 vir39 SubClust-2 f0=t3 LinGap>4 1 0 t3 0 12 t34 f0=b23 RnGp>4 1 0 b23 0 30 b3... 1 84 t34 0 95 t23 0 96 t234 Thm: MxPt[SpS((M-x)od)]=MxPt[SpS(xod)] (shift by Mod, MxPts are same Repick f1MnPt[SpS(xod1)]. Pick g1MxPt[SpS(xod1)] SubClust-2 f0=t34 LinGap>4 1 0 t34 0 13 set36 Pick fhMnPt[SpS(xodh)]. Pick ghMxPt[SpS(xodh)]. f0=b124 RnGp>4 1 0 b124 0 28 b12 0 30 b14 1 32 b24 0 41 vir10... 1 75 t24 1 81 t1 1 86 t14 1 93 t12 0 98 t124 SubClust-1 f0=t24 RnGp>4 1 0 t24 1 12 t2 0 20 ver13 SubClust-2 f0=set16 LnGp>4 none SubClust-1 f1=ver49 RdGp>4 none SubClust-1 f0=b1 RnGp>4 1 0 b1 0 23 ver1 SubClust-2 f1=set42 RdGp>4 none SubClust-1 f1=ver49 LnGp>4 none 1. Choose f0 (high outlier potential? e.g., furthest from mean, M?) 2. Do f0-rnd-gap analysis (+ subcluster anal?) 3. f1 be s.t. no x further away from f0 (in some dir) (all d1 dot prods0) 4. Do f1-rnd-gap analysis (+ subclust anal?). 5. Do d1-linear-gap analysis, d1≡ f0-f1 / |f0-f1|. 6. Let f2 s.t. no x is further away (in some direction) from d1-line than f2 7. Do f2-round-gap analysis. 8. Do d2-linear-gap d2 ≡ f0-f2 - (f0-f2)od1 / len... SubClust-1 f0=ver19 RnGp>4 none SubClust-2 f1=set42 LnGp>4 none SubClust-2 is 50 setosa! Likely f2, f3 and f4 analysis will not find none. f0=b34 RnGp>4 1 0 b34 0 26 vir1 ... 1 66 vir39 0 72 set24 ... 1 83 t3 0 88 t34 SubClust-1 f0=ver19 LinGp>4 none
b123 b134 b234 0.0 41.0 42.5 41.0 0.0 43.9 42.5 43.9 0.0 b24 b2 b12 0.0 28.0 42.5 28.0 0.0 32.0 42.5 32.0 0.0 x x x x x x xx x x x x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x x x x x x x x xxx x x x x xx x x x x x x x x g for FMG-GM f for FMG-GM t23 t234 t12 t24 t124 t2 0.0 12.0 51.7 37.0 53.0 35.0 12.0 0.0 53.0 35.0 51.7 37.0 51.7 53.0 0.0 39.8 12.0 38.0 37.0 35.0 39.8 0.0 38.0 12.0 53.0 51.7 12.0 38.0 0.0 39.8 35.0 37.0 38.0 12.0 39.8 0.0 b34 b124 b23 t13 b13 0.0 61.4 41.0 91.2 42.5 61.4 0.0 60.5 88.4 59.4 41.0 60.5 0.0 91.8 43.9 91.2 88.4 91.8 0.0 104.8 42.5 59.4 43.9 104.8 0.0 FMG-GS using SpS((M-x)o(M-x)) to find f1, then Linear analyses. f1=ball g1=tall LnGp>4 1 -137 ball 0 -126 b123 0 -124 b134 1 -122 b234 0 -112 b13 ... 1 -29 t13 1 -24 t134 1 -18 t123 1 -13 tal f2=vir11 g2=set16 Ln>4 none f3=t34 g3=vir18 Ln>4 none f4=t4 g4=b4 Ln>4 1 24 vir1 0 39 b4 0 39 b14 f4=t4 g4=vir1 Ln>4 none This ends the process. We found all (and only) added anomalies, but missed t34, t14, t4, t1, t3, b1, b3. f1=b13 g1=b2 LnGp>4 none f2=t2 g2=b2 LnGp>4 1 21 set16 0 26 b2 f2=t2 g2=t234 Ln>4 0 5 t23 0 5 t234 0 6 t12 0 6 t24 0 6 t124 1 6 t2 0 21 ver11 CRC method g1=MaxVector ↓ x x x x x x xx x x x x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x x x x x x x x xxx x x x x xx x x x x x x x x xxx x xx x x x x x x xx x x x x x x x x x x x x x x xx x x x x xx x x x xx x x f2=vir11 g2=b23 Ln>4 1 43 b12 0 50 b34 0 51 b124 0 51 b23 0 52 t13 0 53 b13 MCR g MCR f f2=vir11 g2=b12 Ln>4 1 45 set16 0 61 b24 0 61 b2 0 61 b12 CRC f1=MinVector
f1=bal RnGp>4 1 0 ball 0 28 b123... 1 73 t4 0 78 vir39... 1 98 t34 0 103 t12 0 104 t23 0 107 t124 1 108 t234 0 113 t13 1 116 t134 0 122 t123 0 125 tal Finally we would classify within SubCluster1 using the means of another training set (with FAUST Classify). We would also classify SubCluster2.1 and SubCluster2.2, but would we know we would find SubCluster2.1 to be all Setosa and SubCluster2.2 to be all Versicolor (as we did before). In SubCluster1 we would separate Versicolor from Virginica perfectly (as we did before). FMG-GS start f1MxPt(SpS((M-x)o(M-x))), Round gaps first, then Linear gaps. Sub Clus2 Sub Clus1 t12 t23 t124 t234 0.0 51.7 12.0 53.0 51.7 0.0 53.0 12.0 12.0 53.0 0.0 51.7 53.0 12.0 51.7 0.0 b13 vir32 vir18 b23 0.0 22.5 22.4 43.9 22.5 0.0 4.1 35.3 22.4 4.1 0.0 33.4 43.9 35.3 33.4 0.0 |ver49 ver8 ver44 ver11 0.0 3.9 3.9 7.1 3.9 0.0 1.4 4.7 3.9 1.4 0.0 3.7 7.1 4.7 3.7 0.0 Almost outliers! Subcluster2.2 Which type? Must classify. Sub Clus2.2 b124 b12 b14 0.0 28.0 30.0 28.0 0.0 41.0 30.0 41.0 0.0 We could FAUST Classify each outlier (if so desired) to find out which class they are outliers from. However, what about the rouge outliers I added? What would we expect? They are not represented in the training set, so what would happen to them? My thinking: they are real iris samples so we should not do the really do the outlier analysis and subsequent classification on the original 150. We already know (assuming the "other training set" has the same means as these 150 do), that we can separate Setosa, Versicolor and Virginica prefectly using FAUST Classify. SubClus2 f1=t14 Rn>4 0 0 t1 1 0 t14 0 30 ver8 ... 1 47 set15 0 52 t3 0 52 t34 SubClus1 f1=b123 Rn>4 1 0 b123 0 30 b13 0 30 vir32 0 30 vir18 1 32 b23 0 37 vir6 If this is typical (though concluding from one example is definitely "over-fitting"), then we have to conclude that Mark's round gap analysis is more productive than linear dot product proj gap analysis! FFG (Furthest to Furthest), computes SpS((M-x)o(M-x)) for f1 (expensive? Grab any pt?, corner pt?) then compute SpS((x-f1)o(x-f1)) for f1-round-gap-analysis. Then compute SpS(xod1) to get g1 to have projection furthest from that of f1 ( for d1 linear gap analysis) (Too expensive? since gk-round-gap-analysis and linear analysis contributed very little! But we need it to get f2, etc. Are there other cheaper ways to get a good f2? Need SpS((x-g1)o(x-g1)) for g1-round-gap-analysis (too expensive!) SubClus2 f1=set23 Rn>4 1 17 vir39 0 23 ver49 0 26 ver8 0 27 ver44 1 30 ver11 0 43 t24 0 43 t2 SubClus1 f1=b134 Rn>4 1 0 b134 0 24 vir19 SC1 f2=ver13 Rn>4 1 0 ver13 0 5 ver43 SubClus1 f1=b234 Rn>4 1 0 b234 1 30 b34 0 37 vir10 SC1 g2=vir10 Rn>4 1 0 vir10 0 6 vir44 SubClus1 f1=b124 Rn>4 1 0 b124 0 28 b12 0 30 b14 1 32 b24 0 41 b1... 1 59 t4 0 68 b3 SbCl_2.1 g1=ver39 Rn>4 1 0 vir39 0 7 set21 Note:what remains in SubClus2.1 is exactly the 50 setosa. But we wouldn't know that, so we continue to look for outliers and subclusters. SC1 f4=b1 Rn>4 1 0 b1 0 23 ver1 SbCl_2.1 g1=set19 Rn>4 none SbCl_2.1 f3=set16 Rn>4 none SbCl_2.1 LnG>4 none SbCl_2.1 g3=set9 Rn>4 none SbCl_2.1 f2=set42 Rn>4 1 0 set42 0 6 set9 SC1 f1=vir19 Rn>4 1 44 t4 0 52 b2 SC1 g4=b4 Rn>4 1 0 b4 0 21 vir15 SbCl_2.1 LnG>4 none SbCl_2.1 f4=set Rn>4 none SbCl_2.1 f2=set9 Rn>4 none SbCl_2.1 g4=set Rn>4 none SC1 g1=b2 Rn>4 1 0 t4 0 28 ver36 SubC1us1 has 91, only versicolor and virginica. SbCl_2.1 g2=set16 Rn>4 none SbCl_2.1 LnG>4 none SbCl_2.1 LnG>4 none
Mark 10/15 (“thin” gap using tfxidf). Classification left, reuters text right. Seems right on! Mining and assays grouped, anomalies are gold strikes (vs. production), livestock. Min gap needs to be from the MSB not LSB - ie, how many bits to consider for gaps. Reason: as you add attributes, the distances start getting large, so needs to be relative. I seem to get better results with oblique rather than round, but jury still out…. JAPAN'S DOWA MINING TO PRODUCE GOLD FROM APRIL TOKYO, 3/16 - Dowa Mining Co Ltd> said it will start commercial production of gold, copper, lead and zinc from its Nurukawa Mine in northern Japan in April. A company spokesman said the mine's monthly output is expected to consist of 1,300 tonnes of gold ore and 3,700 of black ore, which consists of copper, lead and zinc ores. A company survey shows the gold ore contains up to 13.3 grams of gold per tonne, he said. Proven gold ore reserves amount to 50,000 tonnes while estimated reserves of gold and black ores total one mln tonnes, he added. GERMAN BANK SEES HIGHER GOLD PRICE FOR 1987 HAMBURG, March 16 - Gold is expected to continue its rise this year due to renewed inflationary pressures, especially in the U.S., Hamburg-based Vereins- und Westbank AG said. It said in a statement the stabilisation of crude oil prices and the Organisation of Petroleum Exporting Countries' efforts to achieve further firming of the price led to growing inflationary pressures in the U.S., The world's biggest crude oil producer. Money supplies in the U.S., Japan and West Germany exceed the central banks' limits and real growth of their gross national products, it said. Use of physical gold should rise this year due to increased industrial demand and higher expected coin production, the banksaid. Speculative demand, which influences the gold price on futures markets, has also risen. These factors and South Africa's unstable political situation, which may lead to a temporary reduction in gold supplies from that country, underline the firmer sentiment, it said. However, Australia's output is estimated to rise to 90 tonnes this year from 73.5 tonnes in 1986. SOME 7,000 MINERS GO ON STRIKE IN SOUTH AFRICA, 3/16 - Some 7,000 black miners went on strike at South African gold and coal mines, the National Union of Mineworkers (NUM) said. A NUM spokesman said 6,000 workers began an underground sit-in at the Grootvlei gold mine, owned by General Union Mining Corp, to protest the transfer of colleagues to different jobs. He said about 1,000 employees of Anglo American Corp's New Vaal Colliery also downed tools but the reason for the stoppage was not immediately clear. Officials of the two companies were not available for comment and the NUM said it was trying to start negotiations with management. LEVON RESOURCES <LVNVF> GOLD ASSAYS IMPROVED VANCOUVER, British Columbia, March 16 - Levon Resources Ltd said re-checked gold assays from the Howard tunnel on its Congress, British Columbia property yielded higher gold grades than those reported in January and February. It said assays from zone one averaged 0.809 ounces of gold a ton over a 40 foot section with an average width of 6.26 feet. Levon previously reported the zone averaged 0.226 ounces of gold a ton over a 40 foot section with average width of 5.16 feet. Levon said re-checked assays from zone two averaged 0.693 ounces of gold a ton over a 123 foot section with average width of 4.66 feet. Levon Resources said the revised zone two assays compared to previously reported averages of 0.545 ounces of gold a ton over a 103 foot section with average width of 4.302 feet. Company also said it intersected another vein 90 feet west of zone two, which assayed 0.531 ounces of gold a ton across a width of 3.87 feet. BP <BP> UNIT SEES MINE PROCEEDING NEW YORK, March 16 - British Petroleum Co PLC said based on a feasibility report from <Ridgeway Mining Co, its joint venture Ridgeway Project in South Carolina could start commercial gold production by mid-1988. The company said the mine would produce at an approximate rate of 158,000 ounces of gold per year over the first four full years of operation from 1989 through 1992 and at an average of 133,000 ounces a year over the full projected 11-year life of the mine. BP's partner in the venture is Galactic Resources of Toronto. The company said subject to receipt of all statutorypermits, finalization of financing arrangements and management and joint venture review, construction of a 15,000 short ton per day processing facility can start. Capital costs to bring the mine into production are estimated at 76 mln dlrs. BP UNIT SEES U.S. GOLD MINE PROCEEDING NEW YORK, March 16 - British Petroleum Co PLC said based on a feasibility report from Ridgeway Mining Co, its joint venture Ridgeway Project in South Carolina could start commercial gold production by mid-1988. The company said the mine would produce approximately 158,000 ounces of gold per year over the first four full years of operation from 1989 through 1992 and at an average 133,000 ounces a year over the full projected 11 year life of the mine. BP's partner is Galactic Resources Ltd of Toronto. BP said subject to receipt of all statutory permits, finalization of financing arrangements and management and joint venture review, construction of a 15,000 short ton per day processing facility can start. Capital costs to bring the mineinto production are estimated at 76 mln dlrs 0 0 2 0 0 0 LEVON RESOURCES REPORTS IMPROVED GOLD ASSAYS VANCOUVER, British Columbia, March 16 - Levon Resources Ltd said re-checked gold assays from the Howard tunnel on its Congress, British Columbia property yielded higher gold grades than those reported in January and February. It said assays from zone one averaged 0.809 ounces of gold a ton. Levon previously reported the zone averaged 0.226 ounces of gold a ton. Levon said re-checked assays from zone two averaged 0.693 ounces of gold a ton. Levon Resources said the revised zone two assays compared to previously reported averages of 0.545 ounces of gold a ton. The company also said it intersected another vein 90 feet west of zone two, which assayed 0.531 ounces of gold a ton. VICEROY RESOURCE CORP> DETAILS GOLD ASSAYS Vancouver, British Columbia, March 17 - Viceroy Resource Corp said recent drilling on the Lesley Ann deposit extended the high-grade mineralization over a width of 600 feet. Assays ranged from 0.35 ounces of gold per ton over a 150-foot interval at a depth of 350 to 500 feet to 1.1 ounces of gold per ton over a 65-foot interval at a depth of 200 to 410 feet. STARREX LINKS SHARE PRICE TO ASSAY SPECULATION TORONTO, March 16 - Starrex Mining Corp Ltd> said a sharp rise in its share price is based on speculation for favorable results from its current underground diamond drilling program at its 35 pct owned Star Lake gold mine in northern Saskatchewan. Starrex Mining shares rose 40 cts to 4.75 dlrs in trading on the Toronto Stock Exchange. The company said drilling results from the program which started in late February are encouraging, "but it is too soon for conclusions." Starrex did not disclose check assay results from the exploration program. U.S. MEAT GROUP TO FILE TRADE COMPLAINTS WASHINGTON, March 13 - </DATELINE><BODY>The American Meat Institute, AME, said it intended to ask the U.S. government to retaliate against a European Community meat inspection requirement. AME President C. Manly Molpus also said the industry wouldfile a petition challenging Korea's ban of U.S. meat products. Molpus told a Senate Agriculture subcommittee that AME and other livestock and farm groups intended to file a petition under Section 301 of the General Agreement on Tariffs and Trade against an EC directive that, effective April 30, will require U.S. meat processing plants to comply fully with EC standards. The meat industry will seek to have the U.S. government retaliate against EC and Korean exports if their complaints are upheld. 0 0 0 1
For speed of text mining (and of other high dimension datamining), we might do additional dimension reduction (after stemming content word). A simple way is to use STD of the column of numbers generated by the functional (e.g., Xk, SpS((x-M)o(x-M)), SpS((x-f)o(x-f)), SpS(xod), etc.). The STDs of the columns, Xk, can be precomputed up front, once and for all. STDs of projection and square distance functionals must wait until they're generated (But that can be done upon capture too). Good functionals produce many large (definitive) gaps. In Iris150 and Iris150+Out30, I find that the precomputed STD is a good for that. A text mining scheme might be: 1. Capture the text as a PTreeSET (after stemming the content words) and store mean, median, STD of every column (content word stem). 2. Throw out low STD columns. 4'. Use a weighted sum of "importance" and STD? (If STD is low, can't be many large gaps. xod5 (x-f5)o(x-f5) (x-g5)o(x-g5) g>4 1 4 0 f5=vir19 STD 20.31 19.87 19.23 g5=set14 1 5 0 f5=vir18 19.90 18.99 19.23 g5=set14 1 3 0 f5=vir23 20.21 19.55 19.23 g5=set14 2 4 0 f5=vir23 19.71 18.30 19.23 g5=set14 1 3 0 f5=vir6 20.22 19.60 19.23 g5=set14 √ √ A possible Attribute Selection algorithm: 1. Peel from X, outliers using CRM-lin, CRC-lin, possibly M-rnd, fM-rnd, fg-rnd.. (Xin = X - Xout) 2. Calculate widths of each Xin-Circumscribing Rectangle edge, crewk 4. Look for wide gaps top down (or, very simply, order by STD). 4'. Divide crewk into count{xk| xXin}. (but that doesn't account for dups) 4''. look for preponderance of wide thin-gaps top down. 4'''. look for high projection interval count dispersion (STD). Notes: 1. Maybe an inlier sub-cluster needs occur from more than one functional projection to be declared an inlier sub-cluster? 2. STD of a functional projection appears to be a good indicator of the quality of its gap analysis. For FAUST Cluster-dfg (pick d, then f=MnPt(xod) and g=MxPt(xod) ) a full grid of unit vectors (all directions, equally spaced) may be needed. Such a grid could be constructed using angles a1, ... , am, each equi-width partitioned on [0,180), with the formulas: d = e1k=n...2cosk + e2sin2k=n...3cosk + e3sin3k=n...4cosk + ... + ensinn where i's start at 0 and increment by . So, di1..in= j=1..n[ ej sin((ij-1)) * k=n. .j+1cos(k) ]; i0≡0, divides 180 (e.g., 90, 45, 22.5...) Best Algorithm (CRM-STD): 0. Eliminate all columns with STD < threshold. 1. Throw out coordintate functionals with low STD. In 3. and 4. also throw out functionals with low STD. Then on functionals with high STD: 2. Use free gap analysis methods: CRM-lin, CRC-lin, (SpS(xodk)=Xk. (We always have to pay for logn-gap-finder, lngf) 3. Use nearly free, M-rnd [M is free. Pay for SpS(x-M)o(x-M), lngf], CRM-rnd, CRC-rnd [ f,g free. Pay for SpS(x-f)o(x-f), SpS(x-g)o(x-g), lngf ] 4. use others, CRM-rnd?, CRC-rnd?, fM-lin, fM-rnd, ff-lin, ff-rnd, ... On Iris150, using a STD threshold of 15: x_ 1 2 3 4 STD 8.3 4.3 17.6 7.6 g>4 0 0 1 0 x_x_ 12 13 14 23 24 34 STD/sqr2 6.3 17.8 10.7 11.5 5.2 17.7 g>4*sqr2 1 1 0 0 0 1 x_x_x_ 123 124 134 234 x_x_x_x 1234 STD/sqr3 13.9 8.49 18.7 13.6 STD/sr4 15.6 g>4*sqr3 1 0 1 0 g>4*sr4 0 A guess: All of the above involve X3. Few new gaps are revealed beyond those of X3? See next slide. At right: I considered other f5's besides vir19 (the absolute furthest from M) that were also far from M. In each case, g5=set14. All have high STDs. Do they reveal high value gaps? On the next slides.
d5 (f5=vir23, g5=set14) none f5 none g5 none Sub Clus2 Sub Clus1 ver49 ver8 ver44 ver11 0.0 3.9 3.9 7.2 3.9 0.0 1.4 4.6 3.9 1.4 0.0 3.6 7.2 4.6 3.6 0.0 d3 0 10 set23...50set+vir39 1 19 set25 0 30 ver49...50ver_49vir 0 69 vir19 d5 (f5=vir32, g5=set14) none f5 none g5 none d5 (f5=vir6, g5=set14) none f5 none g5 none (d1+d3)/sqr(2) clus1 none (d1+d3)/sqr(2) clus2: 0 57.3 ver49 0 58.0 ver8 0 58.7 ver44 1 60.1 ver11 0 64.3 ver10 none (d3+d4)/sqr(2) clus1 none (d3+d4)/sqr(2) clus2 none (d1+d3+d4)/sqr(3) clus1 1 44.5 set19 0 55.4 vir39 (d1+d3+d4)/sqr(3) clus2 none (d1+d2+d3+d4)/sqr(4) clus1 (d1+d2+d3+d4)/sqr(4) clus2 none d5 (f5=vir19, g5=set14) none f5 1 0.0 vir19 clus2 0 4.1 vir23 g5 none d5 (f5=vir18, g5=set14) none f5 1 0.0 vir18 clus2 1 4.1 vir32 0 8.2 vir6 g5 none
APPENDIX: FAUST=Fast, Accurate Unsupervised and Supervised Teaching(Teachingbig data to reveal info) • FAUST CLUSTER-fmg (furthest-to-meangaps for finding round clusters):C=X (e.g., X≡{p1, ..., pf}= 15 pix dataset.) • While an incomplete cluster, C, remains find M ≡ Medoid(C) ( Mean or Vector_of_Medians or? ). • Pick fC furthest fromM from S≡SPTreeSet(D(x,M) .(e.g., HOBbit furthestf, take any from highest-order S-slice.) • If ct(C)/dis2(f,M)>DT (DensThresh), C is complete, else split C where P≡PTreeSet(cofM/|fM|) gap > GT (GapThresh) • End While. • Notes: a. Euclidean and HOBbit furthest. b. fM/|fM| and just fM in P. c. find gaps by sorrting P or O(logn) pTree method? Interlocking horseshoes with an outlier 1 2 p2 p5 p1 3 p4 p6 p9 4 p3 p8 p7 5 pf pb 6 pe pc 7 pd pa 8 1 2 3 4 5 6 7 8 9 a b c d e f C2={p5} complete (singleton = outlier). C3={p6,pf}, will split (details omitted), so {p6}, {pf} complete (outliers). That leaves C1={p1,p2,p3,p4} and C4={p7,p8,p9,pa,pb,pc,pd,pe} still incomplete. C1 is dense ( density(C1)= ~4/22=.5 > DT=.3 ?) , thus C1is complete. Applying the algorithm to C4: In both cases those probably are the best "round" clusters, so the accuracy seems high. The speed will be very high! {pa} outlier. C2 splits into {p9}, {pb,pc,pd} complete. 1 p1 p2 p7 2 p3 p5 p8 3 p4 p6 p9 4 pa 5 6 7 8 pf 9 pb a pc b pd pe c d e f 0 1 2 3 4 5 6 7 8 9 a b c d e f M0 8.3 4.2 M1 6.3 3.5 f1=p3, C1 doesn't split (complete). M f M4 X x1 x2 p1 1 1 p2 3 1 p3 2 2 p4 3 3 p5 6 2 p6 9 3 p7 15 1 p8 14 2 p9 15 3 pa 13 4 pb 10 9 pc 11 10 pd 9 11 pe 11 11 pf 7 8 D(x,M0) 2.2 3.9 6.3 5.4 3.2 1.4 0.8 2.3 4.9 7.3 3.8 3.3 3.3 1.8 1.5 C1 C2 C3 C4 M1 M0
Separate classR, classV using midpoints of means (mom) method: calc a vomV vomR d-line d v2 v1 std of these distances from origin along the d-line a FAUST Oblique PR = P(X dot d)<a D≡ mRmV= oblique vector. d=D/|D| View mR, mV as vectors (mR≡vector from origin to pt_mR), a = (mR+(mV-mR)/2)od = (mR+mV)/2o d(Very same formula works when D=mVmR, i.e., points to left) Training ≡ choosing "cut-hyper-plane" (CHP), which is always an (n-1)-dimensionl hyperplane (which cuts space in two). Classifying is one horizontal program (AND/OR) across pTrees to get a mask pTree for each entire class (bulk classification) Improve accuracy? e.g., by considering the dispersion within classes when placing the CHP. Use 1. the vector_of_median, vom, to represent each class, rather than mV, vomV ≡ ( median{v1|vV}, 2. project each class onto the d-line (e.g., the R-class below); then calculate the std (one horizontal formula per class; using Md's method); then use the std ratio to place CHP (No longer at the midpoint between mr [vomr] and mv [vomv] ) median{v2|vV}, ... ) dim 2 r r vv r mR r v v v v r r v mV v r v v r v dim 1
1. MapReduce FAUST Current_Relevancy_Score =9Killer_Idea_Score=2Nothing comes to minds as to what we would do here. MapReduce.Hadoop is a key-value approach to organizing complex BigData. In FAUST PREDICT/CLASSIFY we start with a Training TABLE and in FAUST CLUSTER/ANOMALIZER we start with a vector space. Mark suggests (my understanding), capturing pTreeBases as Hadoop/MapReduce key-value bases? I suggested to Arjun developing XML to capture Hadoop datasets as pTreeBases. The former is probably wiser. A wish list of great things that might result would be a good start. 2. pTree Text Mining: Current_Relevancy_Score =10Killer_Idea_Score=9I I think Oblique FAUST is the way to do this. Also there is the very new idea of capturing the reading sequence, not just the term-frequency matrix (lossless capture) of a corpus. 3. FAUST CLUSTER/ANOMALASER: Current_Relevancy_Score =9Killer_Idea_Score=9No No one has taken up the proof that this is a break through method. The applications are unlimited! 4. Secure pTreeBases: Current_Relevancy_Score =9Killer_Idea_Score=10 This seems straight forward and a certainty (to be a killer advance)! It would involve becoming the world expert on what data security really means and how it has been done by others and then comparing our approach to theirs. Truly a complete career is waiting for someone here! 5. FAUST PREDICTOR/CLASSIFIER: Current_Relevancy_Score =9Killer_Idea_Score=10No one done a complete analysis of this is a break through method. The applications are unlimited here too! 6. pTree Algorithmic Tools: Current_Relevancy_Score =10Killer_Idea_Score=10This is Md’s work. Expanding the algorithmic tool set to include quadratic tools and even higher degree tools is very powerful. It helps us all! 7. pTree Alternative Algorithm Impl: Current_Relevancy_Score =9Killer_Idea_Score=8This is Bryan’s work. Implementing pTree algorithms in hardware/firmware (e.g., FPGAs) - orders of magnitude performance improvement? 8. pTree O/S Infrastructure: Current_Relevancy_Score =10Killer_Idea_Score=10This is Matt’s work. I don’t yet know the details, but Matt, under the direction of Dr. Wettstein, is finishing up his thesis on this topic – such changes as very large page sizes, cache sizes, prefetching,… I give it a 10/10 because I know the people – they do double digit work always! From:Arjun.Roy@my.ndsu.edu] Sent: Thurs, Aug 09 Dear Dr. Perrizo, Do you think a map reduce class of FAUST algorithms could be built into a thesis? If the ultimate aim is to process big data, modification of existing P-tree based FAUST algorithms on Hadoop framework could be something to look on? I am myself not sure how far can I go but if you approve, then I can work on it. From: Mark to:Arjun Aug 9 From industry perspective, hadoop is king (at least at this point in time). I believe vertical data organization maps really well with a map/reduce approach – these are complimentary as hadoop is organized more for unstructured data, so these topics are not mutually exclusive. So from industry side I’d vote hadoop… from Treeminer side text (although we are very interested in both) From:msilverman@treeminer.comSent: Friday, Aug 10I’m working thru a list of what we need to get done – it will include implementing anomaly detection which is now on my list for some time. I tried to establish a number of things such that even if we had some difficulties with some parts we could show others (w/o digging us too deep). Once I get this I’ll get a call going. I have another programming resource down here who’s been working with me on our production code who will also be picking up some of the work to get this across the finish line, and a have also someone who was a director at our customer previously assisting us in packaging it all up so the customer will perceive value received… I think Dale sounded happy yesterday.
Density: A set is T-dense iff it has no distance gaps greater than T. (Equivalently, every point has neighbors in its' T-neighborhood.) We can use L1 or HOB or L distance, since disL1(x,y) disL2(x,y); disL2(x,y) 2*disHOB(x,y) and disL2(x,y) n*disL(x,y) Definition: YX is T-dense iff there does not exist yY such that dis2(y, Y-{y}) > T. Theorem-1:If for every yY, dis2(y,Y-{y}) T then Y is T-dense. Using L1 distance, not L2=Euclidean: Theorem-2: disL1(x,y) disL2(x,y) (from here on we will use disk to mean disLk ). Therefore: If, for every yY, dis1(y,Y-{y}) T then Y is T-dense. ( Proof: dis2(y,Y-{y}) dis1(y,Y-{y}) T ) 2*disHOB(x,y) dis2(x,y) (Proof: Let the bit pattern of dis2(x,y) be 001bk-1...b0 then disHOB(x,y)=2k and the most bk-1 ...b0 can contribute is 2k-1 (if it's all 1-bits). So dis2(x,y) 2k + (2k - 1) 2*2k = 2*disHOB(x,y). Theorem-3: If, for every yY, disHOB(y,Y-{y}) T/2 then Y is T-dense. Proof: dis2(y,Y-{y}) 2*disHOB(y,Y-{y}) 2*T/2 = T Theorem-4: If, for every yY, dis(y,Y-{y}) T/n then Y is T-dense. Proof: dis2(y,Y-{y}) n*disHOB(y,Y-{y}) n*T/n = T Pick T' based on T and the dimension, n (It can be done!). If MaxGap(yoek)=MaxGap(Yk) < T' k=1..n, then Y is T-dense (Recall, yoek is just Yk as a column of values.) Note: We use the logn pTreeGapFinder to avoid sorting. Unfortunately, it doesn't immediately find all gaps precisely at their full width (because it descends using power of 2 widths), but if we find all PTreeGaps, we can be assured that MaxPTreeGap(Y) MaxGap(Y) or we can keep track of "thin gaps" and thereby actually identify all gaps (see the slide on pTreeGapFinder). Theorem-5: If k=1..nMaxGap(Yk) T, then Y is T-dense Proof: dis1(y,x)≡k=1..n|yk-xk|. |yk-xk| MaxGap(Yk) xY. So dis2(y,Y-{y}) dis1(y,Y-{y}) k=1..nMaxGap(Yk) T
Alternative definition of Density: A set, Y, is kT-dense iff yY, |Disk(y,T)|k (Equivalently, every point has at least k neighbors in its' T-neighborhood.) IRIS[SL] is below: [0,128) 150 [0,64) [64,128) 108 42 [0,32) [32,64) [64,96) [96,128) 0 108 42 0 [32,48) [48,64) [64,80) [80,96) 13 95 42 0 [32,40) [40,48) [48,56) [56,64) [64,72) [72,80) 0 13 46 49 31 11 [40,44) [44,48) [48,52) [52,56) [56,60) [60,64) [64,68) [68,72) [72,76) [76,80) 1 12 28 18 24 25 22 9 5 6
F:XR any distance dominated functional (=ScalarPTreeSet(x,F(x)) s.t. |F(x)-F(y)|dis(x,y) for gap-based FAUST machine teaching. d0≡(M-f0)/|M-f0|. x' d2 [ [ [ [ ] ] ] ] x'ox' x'ox' = = (x-f0) (x-f0) (x-f0) (x-f0) ((x-f0)od1)d1 ((x-f0)od1)d1 ((x-f0)od1)d1 ((x-f0)od1)d1 - - - - o o d1 = X' ≡ space perpendicular to d1. x-f0 ((x-f0)od1)d1 x' x' (x-f0) (x-f0) Projection of x-f0 onto d1 is ≡ - The projection of x-f0 onto d1 is ≡ - ((x-f0)od1)d1 ((x-f0)od1)d1 x''od1 = x'od1- (x'od2)(d2od1) = (x-f0)od1 - ((x-f0)od1)(d1od1) = 0 Each of these defining dk+1 ≡ (fk+1-f0) / |fk+1-f0| rather than dk+1 ≡ fk-1' / |fk-1'| d1≡(f1-f0)/|f1-f0|. E.g., the dot product with any fixed vector, v, (gaps in the projections along the line generated by the vector). E.g., use vectors: fM; fM/|fM|; or in general, a*fM (a constant); (where M is a medoid (mean or vector of medians) and f is a "furthest point" from M). ek where ek - (0 0 0 ... 1 0 0 0 ...) (1 in the kth position) fF; fF/|fF|; or in general, a*fF (a constant); (where F is a "furthest point" from f). But also, if one takes the ScalarPTreeSet(x,xox) of square vector lengths (or just lengths), the gaps are rounded gaps as one proceeds out from the origin. One can note that this is just the column of xox values, so it is dot product generated also. Find a furthest point from M, f0MaxPt[SpS((x-M)o(x-M))]. Do f0 rd gap anal onSpS((x-f0)o(x-f0)) to ident/eliminate (repeat if f0 elimin'd). Find a furthest point from f0, f1MaxPt[SpS((x-f0)o(x-f0))]. Do f1 round gap analysis { SpS((x-f1)o(x-f1)) } to identify/eliminate (repeating if f1 is eliminated) anomalies on the f1 end. Do d1 linear gap analysis (SpS((x-f0)od1)) X'=d1≡space perp to d1. = (x-f0)o(x-f0) - ((x-f0)od1)2 d2≡f2'/|f2'|=[(f2-f0)-((f2-f0)od1)d1]/|f2'| For a subcluster, find f2MaxPt[SpSSubCluster(x'ox')] and SpS(x'ox') = SpS[(x-f0)o(x-f0)) - SpS[(x-f0)od1]2 dk≡fk-1'/ fk-1'| x(k) ≡ x(k-1) - (x(k-1)odk)dk where fk MaxPtSubCluster[SpS(x(k-1)ox(k-1))] Do dk linear gap analysis { SpS[(x-f0)odk] } to separate sub-clusters. Do fk round gap analysis { SpS[(x-fk)o(x-fk)] } to identify/eliminate (repeating if fk is eliminated) on the fk end. Method-1: Find a furthest point from M, f0 = MaxPt[SpS((x-M)o(x-M))]. Do M round gap analysis using SpS((x-M)o(x-M)). d0≡(M-f0)/|M-f0|. f2 Do f0 rd gap anal SpS((x-f0)o(x-f0)). Do d0 linear gap analysis on SpS((x-f0)od0). Find a furthest pt from f0, f1MaxPt[SpS((x-f0)o(x-f0))]). d1≡(f1-f0)/|f1-f0|. Do d1 linear gap analysis on SpS((x-f0)od1). Do f1 round gap analysis on SpS((x-f1)o(x-f1)). x f1 = (x-f0)o(x-f0) - ((x-f0)od1)2 SpS(x'ox') = SpS[(x-f0)o(x-f0)) - SpS[(x-f0)od1]2 Let f2MaxPt[SpS(x'ox')] d2≡f2'/|f2'|=[(f2-f0)-((f2-f0)od1)d1]/|f2'| d2od1=[(f2-f0)od1-((f2-f0)od1)(d1od1) ]/|f2'|=0 d1 x'' ≡ x'- (x'od2)d2 f0 x(k) ≡ x(k-1) - (x(k-1)odk)dk where fk MaxPt[SpS(x(k-1)ox(k-1))] and dk ≡ fk-1' / |fk-1'| d1 Do fk round gap analysis on SpS[(x-fk)o(x-fk)]. Do dk linear gap analysis on SpS[(x-f0)odk]. x''od2 = x'od2- (x'od2)(d2od2) = 0 or (x-p)o(a1...an) ) xo(a1...an) ) Linear gap anal. incl: Coordinate gap analysis. truncated Taylor series, k=1..Nbk*(i=1..nai(x-p)ik) {dk} orthonormal basis. or i=1..nai*(x-p)i2 ) (len2 is sub-case.) Square gradient-like length: i=1..n(MaxVal(x(k-1)ox (k-1))). x(k-1)-MaxLength itself: MaxVal(x(k-1)ox (k-1)).
Thin interval finderon the fM line using the scalar pTreeSet, PTreeSet(xofM) (the pTree slices of these projection lengths) &p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 C=2 &p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 C=3 &p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 C=1 &p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 C=0 p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 C=2 p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 C=1 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 C=2 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 C=5 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 C=5 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 C=5 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 C=5 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 C=3 p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 C=2 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 C=1 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 C=6 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 C=2 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 C=2 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 C=8 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 C=2 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 C=8 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 C10 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 C10 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 C10 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 C10 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 Looking for Width24_Count=1_ThinIntervals or W16_C1_TIs 1 z1 z2 z7 2 z3 z5 z8 3 z4 z6 z9 4 za 5 M 6 7 8 zf 9 zb a zc b zd ze c 0 1 2 3 4 5 6 7 8 9 a b c d e f xofM 11 27 23 34 53 80 118 114 125 114 110 121 109 125 83 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 p3 1 1 0 0 0 0 0 0 1 0 1 1 1 1 0 p2 0 0 1 0 1 0 1 0 1 0 1 0 1 1 0 p1 1 1 1 1 0 0 1 1 0 1 1 0 0 0 1 p0 1 1 1 0 1 0 0 0 1 0 0 1 1 1 1 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 p3' 0 0 1 1 1 1 1 1 0 1 0 0 0 0 1 p2' 1 1 0 1 0 1 0 1 0 1 0 1 0 0 1 p1' 0 0 0 0 1 1 0 0 1 0 0 1 1 1 0 p0' 0 0 0 1 0 1 1 1 0 1 1 0 0 0 0 X x1 x2 z1 1 1 z2 3 1 z3 2 2 z4 3 3 z5 6 2 z6 9 3 z7 15 1 z8 14 2 z9 15 3 za 13 4 zb 10 9 zc 11 10 zd 9 11 ze 11 11 zf 7 8 f= W=24 C=1 [000 0000, 000 1111] =[0,16). z1ofM=11 is 5 units from 16, so z1 not declared an anomaly. W=24 C=1 [0110000, 0111111] =[48, 64). z5ofM=53 is 19 from z4ofM=34 (>24) but 11 from 64. The next interval [64,80) is empty and it's 27 from 80 (>24) so z5 is an anomaly and we make a cut through z5. W=24 C=1 [010 0000 , 010 1111] =[32,48). z4ofM=34 is within 2 of 32, so z4 is not declared an anomaly. W=24 C=0 [100 0000 , 100 1111]=[64, 80). Ordinarily we cut thru the midpoint of C=0 intervals, but in this case it's unnecessary since it would duplicate the z5 cut just made. Here we started with xofM distances. The same process works starting with any distance based ScalarPTreeSet, e.g., xox, etc.